The National Library of Norway was the host institution for this international event. The Norwegian Web Archive is part of the Library’s mission and is held in a second location specialising in digital preservation, in the city of Mo i Rana, in the centre of the country.
The first day, 8 April, was dedicated to the General Assembly, exclusively for members of the consortium, and to the working groups in which Arquivo.pt plays an active role. The Content Development Working Group is dedicated to the creation of thematic collections and has the participation of Arquivo.pt in the ‘Street Art’ collection. The Training Working Group creates training content and training actions, such as IIPC webinars and face-to-face workshops.
The Web Archiving Conference was held on 9 and 10 April, an event open to all entities and initiatives related to web preservation and archiving.
Arquivo.pt’s contribution
Arquivo.pt presented its services and initiatives for interacting with the community, such as its collaboration with the Sines Municipal Archive in preserving content of local interest. The concern with access to content, both for researchers and for citizens in general, is an aspect that is highly appreciated by the IIPC community.
Arquivo.pt toolkit for web archiving – Lightning talk session 1 – Daniel Gomes – Slides, video
Arquivo.pt Query Logs – Lightning talk session 3 – Pedro Gomes – Slides, video
Collaborative collections at Arquivo.pt: four years of recordings from the city of Sines (Portugal) – Lightning talk session 4 – Ricardo Basílio – Slides, notes, video
API/Bulk access and its usage – Poster slam – Vasco Rato – Poster
Arquivo.pt annual awards: a glimpse since 2018 – Poster slam – Daniel Gomes – Slides
The month of September marks the beginning of a year’s work and also the end of many websites that are hopelessly lost. Remodelled or shut down without making a good copy of their content, this is how historic websites are lost unnecessarily.
There are tools that allow websites to be saved immediately by the organisations that manage them. In addition, there is the on-demand archiving service for high-quality websites that Arquivo.pt provides to partner organisations or in occasional collaborations.
This article aims to highlight the Browsertrix Crawler used by Arquivo.pt, without excluding other tools, which can be useful to information managers and IT departments.
Use of Browsertrix-crawler by Arquivo.pt for high-quality collections
Browsertrix Crawler is a tool that lets you record entire websites and lists of web pages automatically and in a format compatible with web archives.
Arquivo.pt uses the Browsertrix Crawler to make high-quality site collections (RAQs) on-demand of the community. For example, when a site is about to be shut down, when it’s going to undergo remodelling or, periodically, to maintain a good history of a particular site.
Requests for high-quality collections (RAQs) to Arquivo.pt are increasingly frequent: 77 requests from January to September 2024. This is a sign that there is greater concern about the preservation of web content.
What you need to use Browsertrix-crawler locally
The group that developed the Browsertrix Crawler, Webrecorder.net, led by Ilya Kreymer, has the motto ‘web archiving for all’. Its tools make it possible to record the Internet in a decentralised way and on a small scale.
The Browsertrix Crawler is available and can be installed on your computer for small collections.
The basic version of Browsertrix that Arquivo.pt is using requires basic command line knowledge, which is the only barrier for non-experts.
From Arquivo.pt’s own experience, using the Browsertrix Crawler is easy in multidisciplinary teams, where there is always someone with minimal knowledge to use Linux commands and provide occasional support.
Demonstration of recording entire websites on your own computer
To promote the preservation of sites in Web archive format, Arquivo.pt presents a use case for the Browsertrix Crawler. It’s useful for anyone who wants to deepen their knowledge and practice of saving sites in a local environment.
Other tools used by Arquivo.pt to record content
Brozzler: a tool for improving the history of daily and monthly collection sites
Brozzler is a similar tool to Browsertrix Crawler in that it also bases its recording on a browser. It is used and maintained by the Internet Archive.
Arquivo.pt has been using Brozzler since at least 2018 to record web pages with interactive content present on the web pages and for high-quality collections (RAQs).
Lists of up to 200 sites are successfully recorded by Brozzler. For example, the 125 daily collection sites (FAWP) are recorded with Brozzler at the beginning of each month.During the month, another list of 75 monthly collection sites (MAWP) is recorded using Brozzler.
At the end of 2023, Arquivo.pt compared Brozzler and Browsertrix Crawler and chose to keep these two tools.
Heritrix, pywb and ArchiveWeb.page: tools for thousands of sites or one page
The Heritrix crawler is Arquivo.pt’s main recording tool. It is used on huge lists of websites, such as the .PT domain sites, to which other Portuguese sites are added, totalling more than half a million.
To complete the list of recording tools used by Arquivo.pt, mention should be made of pywb, which comes into play, for example, when an Arquivo.pt user uses the ‘Complete the page’ functionality or the ArchivePageNow service.
IPL – Politécnico de Lisboa, through its Distance Learning Group (EaD@IPL), organised a series of webinars for its community dedicated to Arquivo.pt and the preservation of content published on the Internet.
This initiative was attended by IPL – Politécnico de Lisboa lecturers and researchers, as well as people linked to the institution’s communications department.
The cycle of webinars took place in three sessions, between May and July 2024, and followed the training programme that Arquivo.pt has been offering for several years.
Presentation materials
1st webinar – Arquivo.pt: a new tool for researching the past. Well publish to well preserve. June 5 , 2024.
Archiving content published on the web and using a web archive on a day-to-day basis is an unusual practice, largely due to the community’s lack of knowledge about the existence and operation of Arquivo.pt.
As a result of this series of webinars, the collaboration between the IPL – Politécnico de Lisboa and Arquivo.pt was strengthened, with a view to preserving its institutional websites and other interesting content that is available on various online media (news, events, references to teachers, researchers and students).
The collection of 1 PetaByte of content predominantly in Portuguese, accessible to both researchers and ordinary citizens, is a milestone that deserves to be celebrated, in the month of its 16th anniversary.
At Arquivo.pt you can search for information published on the Web in the past, such as:
Arquivo.pt was created on November 8, 2007 with the aim of preserving content from the Portuguese Web.
In 2013, as a service operated by the Fundação para a Ciência e a Tecnologia (FCT), its mission was formulated as follows: “To promote the preservation of content available on the national Internet, ensuring that it is made available to the scientific community and the general public” (Decreto-Lei no. 55/2013).
In recent years, Arquivo.pt has created new services, such as CitationSaver, which allows researchers to record references to web content in their scientific articles, Memorial and Complete page, which facilitate access to content scattered throughout the huge 1 PetaByte block of data.
Where did so much information come from?
In order to reach the 1 PetaByte volume, Arquivo.pt periodically recorded content from websites in the .PT domain and from Portuguese websites in other domains.
In addition, frequent daily and monthly collections were made from a small number of government sites and the main news sites in Portugal.
As part of international collaborations, content was collected from sites in various languages, for example on the 2019 European Elections.
Content prior to 2008 came from the Internet Archive and donations, such as a collection made by the National Library and INESC on the 2005 Legislative Elections.
The largest Portuguese-language dataset available to researchers
By making 1 PetaByte of information available, in open access and through the use of APIs (Application Programming Interfaces), Arquivo.pt is a useful tool for research.
For example, a researcher who wants to do a study on elections in Portugal can use the entire Arquivo.pt collection. Better still, they can focus on just a few special collections dedicated to the elections, choosing the ones that interest them and downloading just a few Terabytes to process automatically with the APIs.
Contributions from the various teams and friends of Arquivo.pt
The event, which took place in the auditorium of the Polícia Judiciária in Lisbon, was attended by representatives from the government’s justice department and professionals from the archives, communications and IT departments.
How to use Arquivo.pt to preserve institutional websites
Arquivo.pt took part in the presentation “Preserve your website”, which addressed the issue of preserving institutional websites and critical aspects such as cybersecurity.
Justice entities can benefit from Arquivo.pt and its various services to ensure good preservation of their websites, mitigate cybersecurity threats and provide historical content to citizens.
The presentation concluded with the following recommendations:
Inventory and publicize your current and historical websites
On the following days, May 11 and 12, the IIPC Web Archiving Conference (IIPC WAC) was held, an initiative open to the community, where people or entities not associated with the IIPC and interested in the Web preservation domain can participate.
Contributions from the Arquivo.pt at the Web Archiving Conference
Arquivo.pt participated in the IIPC working group meetings (Training Working Group and Curators Working Group) and contributed with presentations in the thematic sessions Collaborations & Outreach and Program infrastructure (sessions 7 and 17).
Arquivo.pt contributed with presentations to the sessions Web Archive in Mediterranean area and its merge (4.A), From online Tools to Web Archive (6.B.), Towards a participatory approach to collections (9. A.), Digging up the materials for writing web history (9.B.).
How to research governmental web data? (abstract, slides)
Arquivo.pt has participated in three courses: Incentives design for hybrid multilingual information processing and analytics, in Southampton; National and transnational media coverage of European parliamentary elections, 2004-2014, London; and NLP for under-resourced languages, in Zagreb, Croatia.
In 2022, the Arquivo.pt welcomed two researchers in its facilities who used the archived resources and received special support from the Arquivo.pt team to develop their research.
The CLEOPATRA Project ended in 2023 with a meeting on the 16th May, in Hannover, which brought together Professors, Researchers and representatives of the institutions involved.
Daniel Gomes, Arquivo.pt’s Manager, highlighted the new tools that Arquivo.pt makes available and the results of the work carried out by the researchers that have passed through Arquivo.pt.
Secondments@Arquivo.pt and new research tools available (slides)
The platform is maintained by the Celestino Domingues Library of The Estoril Higher Institute for Tourism and Hotel Studies (ESHTE) and has the participation of institutions from various areas of heritage that are content providers.
Among the digitized contents that can be consulted in the catalog and accessed in the provider institutions were sound, image, photography, printed material, but websites were missing.
Thus, the idea for the MUVITUR’s new “Web Pages” collection emerged.
Collaboration between MUVITUR and Arquivo.pt
In 2019, a collaboration between Arquivo.pt and MUVITUR began with the aim of identifying websites related to Tourism in Portugal and to disseminate the history of content published on the Web since 1996.
In 2022, a list was established with about 400 records of websites of various entities related to tourism, hotels, travel agencies, pages of municipalities’ websites dedicated to tourism and others.
Collection of records in the MUVITUR catalog with webpages preserved at Arquivo.pt.
How the integration was done
MUVITUR uses Nyron software, which allows content from different sources to be aggregated using the OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting) interoperability protocol, which is very common among libraries, archives and museums to provide content to portals such as Europeana.
Arquivo.pt, however, does not make information available through OAI-PMH so it was necessary to find alternative ways to create a record in Nyron with descriptive information from preserved sites.
The procedure for integration was as follows:
The XML schema with the fields for the metadata, according to what works in Nyron, was exported to an Excel sheet.
The information was entered manually, respecting the format and syntax, in collaboration with the computer technicians.
The XML file with the inserted data was validated and imported into Nyron.
Creating records in catalogs is largely a manual task and requires human curation. However, it was possible to input information to be automatically processed in the records of the Website collection. For example, the thumbnail was obtained using the Arquivo.pt API, more specifically the linkToScreenShot, visible in the technical details of a preserved page (see the options menu on the top right of a replayed page).
For other elements, such as the site’s title, it would be possible to obtain them automatically through the Arquivo.pt API, however the quality of the information depends on what the site’s producers have inserted and may not be accurate. The dates to limit the temporal scope can also be obtained automatically, but the manual method was chosen to control the information presented.
In the continuation of the project, the collection will be increased with new records, as there are thousands of websites about the Tourism sector.
Description of Web contents in the MUVITUR catalog
In the collection “Paginas Web” the following data are used:
Denomination – usually the title of the website
Organization – the entity to which the publication belongs
Website address on the Internet
Address for version in Arquivo.pt
Moment(s) to remember
Link for miniature in Arquivo.pt
Descriptors
Geographical data (location, coordinates, geographical name)
The presentation of the information was adjusted to be aligned with that of other MUVITUR resources and contains links to Arquivo.pt.
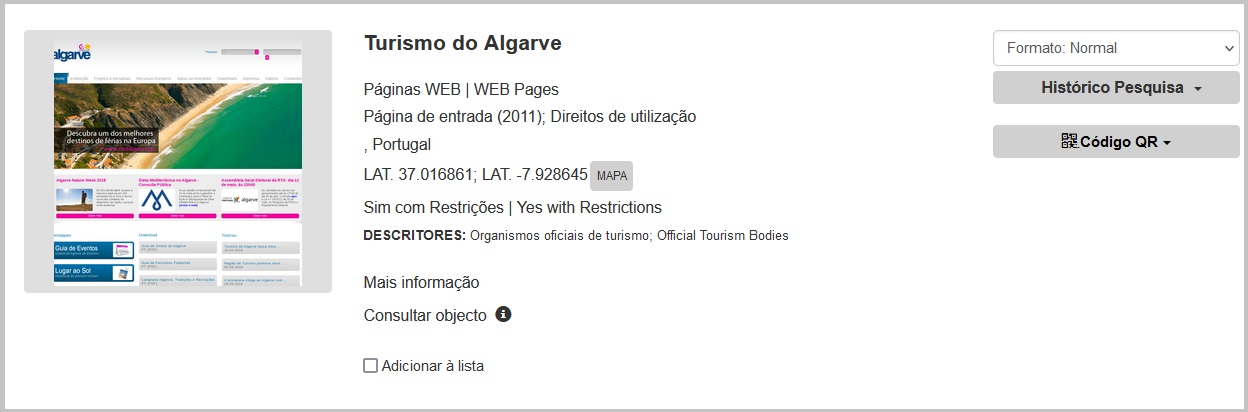
For example, in the register of the Turismo do Algarve site, we find a link to a moment to remember in 2011 and another link to the history in Arquivo.pt under “Consultar objecto”.
Organizations can create collections of Websites from their area
The National Library of Australia, for example, included records of preserved Websites in its catalog. In the Library of Congress there are collections of old Websites alongside traditional resources.
However, websites are rarely included in museums.
With this unprecedented project we can say that preserved Web sites have gained citizenship in digital platforms dedicated to cultural heritage.
MUVITUR has paved the way with this project for other entities to create collections of websites of their interest on their own platforms.
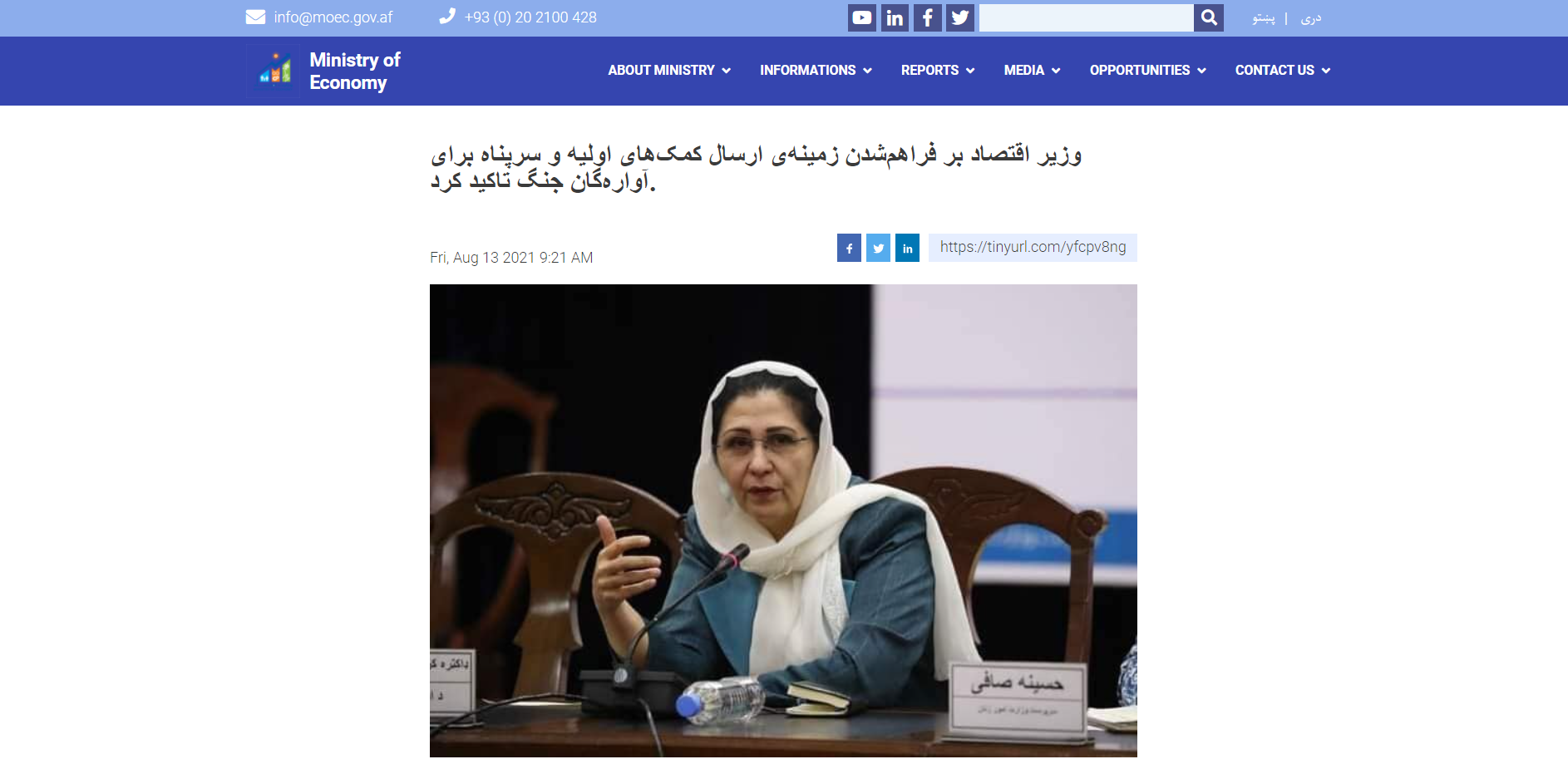
On August 15, 2021 the presidential palace in Kabul was taken over by the Taliban, consummating the fall of the regime that had been in place for 20 years, following the 9/11 attacks on the United States.
No time to lose when it comes to preserving the Web
Arquivo.pt reacted quickly, launching an automatic content search focused on .af domain sites and on international media news about the ongoing events.
On August 17, the websites began to be recorded.
1800 website addresses from Afghanistan (ending in .af) and 500 media news stories from around the world were used.
The addresses, URLs or “seeds” were obtained through automated search using the Bing Search API and immediately put into recording.
Content available to know Afghanistan’s history
As a result of the collection carried out, more than 400 Gigabytes of information became available at Arquivo.pt, which anyone can use for research in the most diverse areas.
The main contribution of Arquivo.pt to the community of Web archivists was the use of the automatic search that allows a quick reaction in the recording of Web contents in imminent risk of being lost.
The International Internet Preservation Consortium (IIPC), a consortium that brings together Web preservation initiatives from around the world, held its General Assembly with its members between May 17 and 19, 2022.
The following week, between May 24 and 25, held the IIPC Web Archiving Conference (IIPC WAC), online as in the previous year due to the contingencies of the Covid-19 pandemic.
Arquivo.pt resources and initiatives presented at the IIPC WAC 2022
The IIPC Web Archiving Conference is an initiative open to the community, where people or entities interested in the Web preservation domain may participate.
The Arquivo.pt contributed to the Ligthtning Talks sessions (session 5 and session 13).
The Arquivo.pt presentations focused on the resources and initiatives that this service has lately developed for the community.
Exhibiting Web memories from Arquivo.pt with free tools (abstract, slides, video)
Welcome to the third season of the Online Cafe with Arquivo.pt
Talk directly to the Arquivo.pt team and get answers to all your questions! The Arquivo.pt launched a new cycle of team chats with you through online sessions. Brief introductory presentations will be given, leaving time to ask all your questions about how to get more out of Arquivo.pt or how to apply to the Arquivo.pt Awards.
Sessions
February 17, 2022 – Primeiras páginas de jornais online portugueses
“Primeiras páginas de jornais online portugueses” (Front pages of Portuguese online newspapers) presents an interactive graphical analysis of the front pages of Portuguese online newspapers. For this study, specific items within the newspaper design were analysed, thus allowing trends to be observed over time.
Susana Parreira, explains how she developed this work as part of her Masters, with the collaboration and guidance of Ana Boavida (Universidade de Coimbra) Ana Sabino (Instituto Politécnico de Castelo Branco) and Penousal Machado (Universidade de Coimbra).
Politiquices.pt, allows to research support or opposition relations between political personalities and parties expressed in news headlines. This application uses information preserved in Arquivo.pt to create an ontology of relations. It uses Natural Language Processing technology. David Batista, 2nd place of Arquivo.pt Awards 2021, will explain how he developed his work and demonstrate the applications for researchers and citizens in general.
Special session – World Digital Preservation Day 2021 – Major minors project – november 5
In November, World Digital Preservation Day is broadly celebrated and, to mark this international initiative, Arquivo.pt held an online session open to the community. Special guests of this session were the winners of the Arquivo.pt Award 2021, Leandro Costa, Paulo Martins and José Carlos Ramalho.