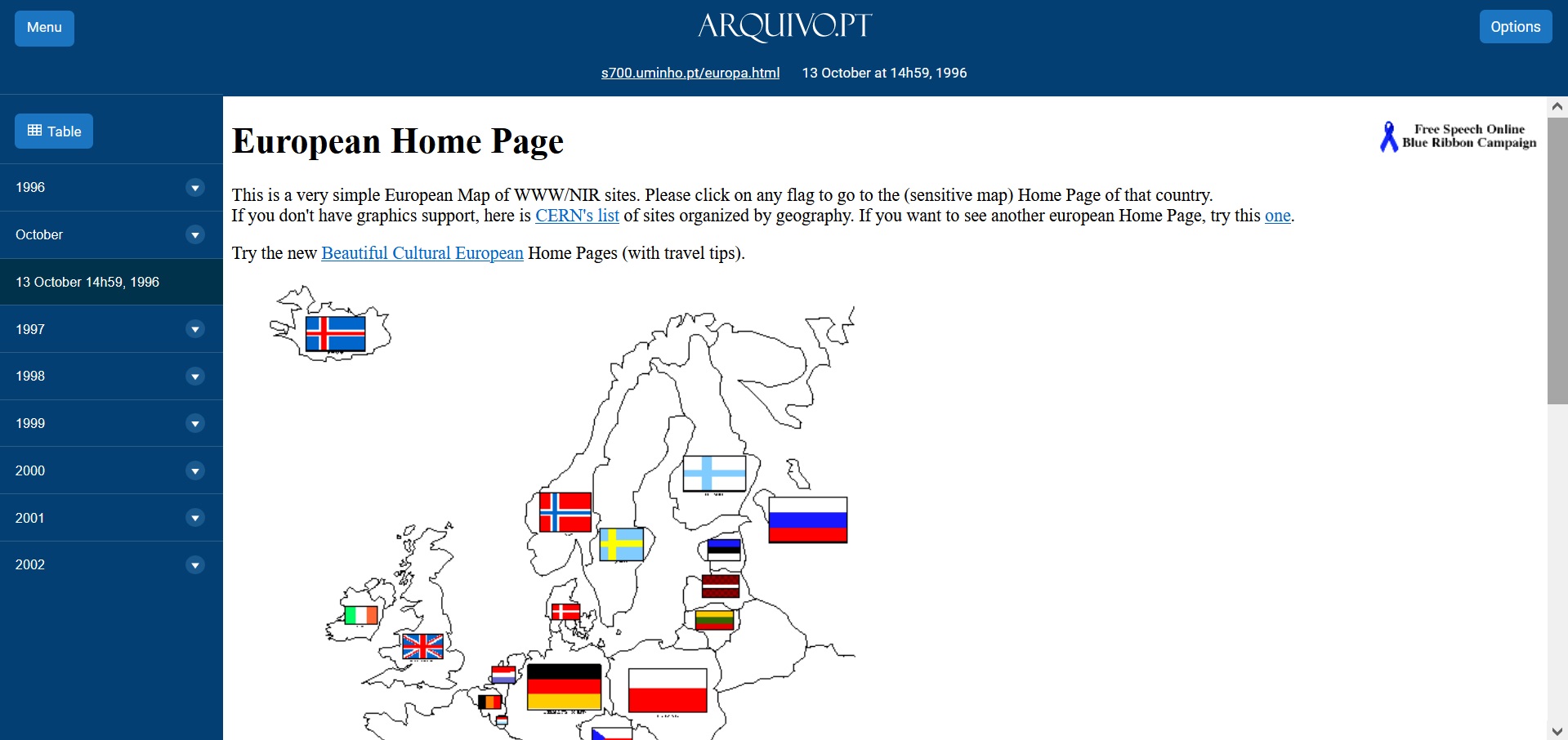
More than 8,000 unique pages were recorded, before and after the elections, resulting in around 250 Gigabytes of information.
This collection includes news items from the media, party websites and other citizen publications documenting this important event in Portuguese life.
The data collected is available for researchers to use in their work and projects.
Methodology for collecting the electoral event
The collection was carried out using a semi-automatic methodology that allows information to be identified and collected quickly and saves resources. The steps were as follows:
The starting point for identifying pages for this electoral event was a list of search terms, including words, names, dates, website addresses and also words in other languages. For example, we used ‘eleições’ “legislativas”, 2025, candidate names, party websites, newspaper websites and ‘eleições Portugal’ in other European languages to find foreign media pages that referred to the Portuguese elections. A total of 384 search terms were used.
The extracted addresses or URLs are then recorded, assuming that there are pages that miss the target and favouring speed, an important factor in this type of event.
A search was carried out to identify web pages before the elections and two the following week, with the corresponding recording, in order to add new content to the collection.
Finally, all the data from this special collection was published. Researchers are invited to use this information for projects or studies and to compete for the annual Arquivo.pt Award.
Arquivo.pt took part in the workshop entitled “Digital preservation: tools and practices”, promoted by the Faculty of Letters of the University of Coimbra, on the afternoon of May 7, 2025. Moderated by Inês Santos, we highlight the initial panel with excellent speeches by Moisés Rockembach (University of Coimbra), Humberto Innarelli (Unicamp, Brazil) and Daniel Gomes (Arquivo.pt, digital service of FCCN-FCT).
The aim of the meeting was to offer the community a critical reflection on new trends in digital preservation tools and practices.
Digital preservation is a cross-cutting issue for organizations, as they all produce and generate information in digital format. There is a growing range of tools and solutions that promise greater efficiency in information processing. Many are labeled Artificial Intelligence. Such an abundance of products and frameworks calls for greater discussion and a critical approach. And this was achieved brilliantly by the panel of speakers.
Three approaches to Artificial Intelligence and Digital Preservation
This meeting brought together three authors of works on digital preservation at the Amphitheatre III of the Faculty of Letters of the University of Coimbra and discussed different approaches.
Moisés Rockembach, co-author with Caterina Pavão of Arquivamento da Web e preservação digital (Archiving the Web and Digital Preservation), the first work in Portuguese on web archives, focused his presentation on the impact of Artificial Intelligence on digital preservation systems, namely on searching for and accessing information, in classification and indexing processes, for example. With regard to the impact of the new tools that digital technology offers us, he referred to a phrase by Demi Gretscko: “The process of searching for and capturing information described in the text could certainly be improved in the future, especially when considering the contribution of new tools, such as those of Artificial Intelligence”.
There are Artificial Intelligence tools that allow interesting access to information through novelty and format. Archiving must take this reality into account and test the extent to which it can transform the way in which many types of content are disseminated and accessed. One example to illustrate this idea was the presentation of a Podcast generated by Artificial Intelligence from An example to illustrate this idea was the presentation of a Podcast generated by Artificial Intelligence, based on chapter 2 of the book on Web Archives, which deals with digital preservation policies.
Humberto Innarelli, author of Criptex da preservação digital (Digital preservation cryptex), coordinator of the Arquivo Edgard Leuenroth (AEL) and specialist archival researcher at Unicamp, São Paulo and PhD professor at the Paula Souza Centre, São Paulo, posed the question of the future of digital preservation. Until now, the practice for preserving dynamic digital content has been to convert it into static documents. On the other hand, information is increasingly given to us dynamically, from databases or algorithms and Artificial Intelligence. What’s the next step? Archival practice needs to look not only at metadata, as it has done in recent years, but also at what explains how the information was generated (what we might call paradata). This is the only way to put archives and digital preservation in the long-term perspective. A hundred or two hundred years from now we should still be able to access the digital information produced today.
Daniel Gomes, editor of the book The Past Web and founder of Arquivo.pt, discussed the issue of Artificial Intelligence as it relates to non-artificial, human-produced content. What added value do tools that generate text, images, audio or video bring? If we consider, for example, that a Podcast on digital preservation used a book written by a human author as its basis, what new knowledge did it generate? Little or none. So, what has come to be called Artificial Intelligence can be considered a way of presenting human knowledge and in no way exempts humanity from continuing to think, research and produce new knowledge.
Arquivo.pt preserves content that has been published by individuals and organizations and in this sense is a unique source of its kind. Information published on the web is important for reporting and better understanding recent history, since the 1990s. Any Artificial Intelligence tool will have to go back to the point where the information was created by people. The human origin of the content preserved by Arquivo.pt, and the same can be said of traditional archives, makes them of enormous value, even considering their economic value. How much is the information stored in a web archive worth?
New MOOC (Massive Online Open Course) about web archiving
Arquivo.pt data can be processed by Artificial Intelligence. The works competing for the Arquivo.pt Award have already demonstrated this, as have projects such as GlórIA, a Large Language Model developed at NOVA-FCT.
Finally, Ricardo Basílio, digital curator, showed how anyone can save a page or an entire website on their own computer in a standardized format, compatible with web archives. ArchiveWeb.page and browsertrix-crawler were used for this, as training tools. This practice allows the community to be increasingly active in preserving institutional information published on the Web.
Agenda
14h30 Panel – Moderator: Inês Santos, University of Coimbra
Digital Preservation and Artificial Intelligence – Moisés Rockembach, University of Coimbra – Slides
Cryptex for Digital Preservation: The Next Step – Humberto Innarelli, Unicamp – Slides
Arquivo.pt and Web Preservation – Daniel Gomes, FCCN-FCT – Slides
16h00 Break
Open Data for Research. Automatic information processing through APIs – Vasco Rato, FCCN-FCT – Slides
Professor José Borbinha, eArchiving workshop, 25 February 2025, at the Instituto Superior Técnico in Lisbon (José Tribolet Room)
Arquivo.pt took part in the eArchiving Portugal workshop, which was held at the Instituto Superior Técnico on 25 February 2025, at the invitation of Professor José Borbinha, one of the first people to do web archiving in Portugal when he worked at the Biblioteca Nacional in the 90’s.
Professor José Borbinha, better than anyone, knows how to tell in the first person the small, almost epic episodes, the actions of the first ‘heroes’ that led to the creation of a web archive in Portugal. He sees Arquivo.pt as an essential service when it comes to digital preservation and safeguarding organisations’ communication heritage.
The event had a hybrid format with 50 in-person and 270 online participants and was open to all public and private organisations concerned with digital preservation and information management in any type or format. This includes the content of websites and social networks!
eArchiving, a European initiative born in Portugal
The eArchiving Initiative‘s main objective is digital cultural heritage and was created at a meeting of European partners in Lisbon.
‘It was precisely in this room (the José Tribolet room at the Instituto Superior Técnico) that eArchiving began eleven years ago, on 29 May 2014,’ recalled José Borbinha (INESC-ID), host and organiser of the workshop.
Janet Anderson, manager of eArchiving, showed the progress made in eleven years in the field of digital preservation. The projects funded by the European Union within the consortium have resulted in the development of specifications, software, training and knowledge about digital preservation.
This was followed by a presentation of contributions to digital preservation in Portugal: DGLAB, by Pedro Penteado, Centro Hospitalar São João, by Fernanda Gonçalves, Ministério da Justiça, by Alexandra Lourenço and Cristina Soares, Arquivo.pt, by digital curator Ricardo Basílio.
Finnaly, Miguel Ferreira spoke on behalf of DLM Forum MTÜ , a community in which KEEP Solutions LDA participates by developing software. Taking a more technical approach, he showed how the metadata in the E-Ark packaging specifications is structured to fulfil the requirements of digital preservation.
How to use Arquivo.pt to preserve institutional websites
Digital preservation requires collaboration, both internally and externally between organisations, and this workshop served that purpose: sharing good practices, disseminating tools and services and connecting people.
Arquivo.pt highlighted three services from its catalogue for preserving content published on the web:
Arquivo.pt services can be used, for example, by municipalities to preserve content published on institutional websites.
Arquivo.pt training, such as webinars or face-to-face sessions, are useful for empowering organisations to take care of institutional content, including social media content that requires an alternative strategy.
The aim of this joint FCT team was precisely to bring about the meeting and sharing of experiences between various institutions that inevitably have to manage information, both in traditional formats such as paper and in digital formats.
The meeting had 243 participants and 29 speakers throughout the day. Nine of the twenty-seven presentations were submitted for a session called ‘Community Space’.
Digital information was the main theme of the speeches. At the opening, the Head of the DGLAB – Direção Geral do Livro, dos Arquivos e das Bibliotecas (Directorate for Books, Archives and Libraries), Silvestre Lacerda, recalled that the DGLAB was a pioneer among public organisations in tackling the issue of digital preservation. FCT vice-president Francisco Santos emphasised the economic value of data for scientific research.
Digital preservation is not just about technology, as Henrique São Mamede, Professor at Universidade Aberta, INESC TEC, said at the opening conference. It’s also about people, the human factor, the environment outside organisations and new sensibilities such as sustainability and ecology. Hence the importance of creating bridges, of using Artificial Intelligence, for example, in conjunction with ethics. Presentation.
Throughout the day, four panels brought together presentations on various preservation contexts such as the digitisation of sound, image and video, research data, regulatory frameworks, management systems for digitised or born-digital information, dissemination and access, and use in academic research.
Panel 1: Digital preservation initiatives and realities
The first panel was moderated by João Gomes, Director of Advanced Services at FCT, and brought to the table the diversity of contexts in which the issue of preservation and access arises. Here we highlight one aspect of each presentation and invite you to follow the links to learn more about these initiatives.
Moisés Rockemback, Professor at the University of Coimbra and co-author of the book Arquivamento da web e preservação digital (Web archiving and digital preservation), spoke about the first initiatives carried out in Brazil to preserve content published on the Web. The websites of the candidates in the Brazilian elections, for example, are ephemeral by nature but have become material for historiographical research by being preserved in a web archive. From a more theoretical perspective, he addressed the issue of memory. Preserving the web allows us to bring to light events that were only broadcast on digital media such as the web and, in this sense, postpones the end of history expressed in the metaphor of the ‘Dark Age’, a time of darkness, empty of information. Presentation.
Pedro Penteado, Director of Archival and Standardisation Services, presented a set of instruments that the DGLAB has developed, such as the Macro Estrutura Funcional (MEF) (Macro Functional Structure, the Avaliação Suprainstitucional da Informação Arquivística (ASIA) (Super-institutional Assessment of Archival Information) project and the Lista Consolidada na Plataforma CLAV (Consolidated List on the CLAV Platform), which allows the different public administration bodies to comply with legislation and standardise classification and assessment practices. He recalled that these tools are flexible to meet the specific needs of organisations. Presentation.
Pedro Príncipe, Head of the Documentation Services Division at the University of Minho, spoke about research data. The preservation of and access to data is fundamental to the production of science. To achieve this, it is necessary to combine initiatives and work in networks and create communities of practice. The GDI Forum is an example of how useful it is to meet professionals. Certification is highly recommended, as demonstrated by the University of Minho, which has certified its repository, as it is an extra reason to create robustness and to achieve the FAIR (Findable, Accessible, Interoperable, and Reusable) objectives. Presentation.
Hilário Lopes, RTP’s Deputy Director of Institutional Relations and Archive, described the path to digitalisation that has completely changed the way we access the RTP archive (Portuguese Radio and Televison). If until 2001 digitisation was done on request, from that year onwards the contents were massively digitised. Since 2007, the contents have been accessible in digital format, which has facilitated access and use. RTP Memória and Portal RTP are two examples of access to the audiovisual heritage of public radio and television. Presentation.
Panel 2: Preserving and reusing Web information
The theme of web archiving was highlighted in the second panel, moderated by Daniel Gomes, manager of Arquivo.pt and its initiator on 8 November 2007.
Ricardo Basílio, digital curator at Arquivo.pt, presented the online exhibition ‘Memories of 25 April on the Internet’, created in collaboration with the 50 Years of 25 April Commemorative Commission, based on preserved web pages. Select pages about the 25 April celebrations across the country were highlighted through a guided tour of the exhibition. Presentation.
António Campos and Hélder Mestre, from the Arquivo Municipal de Sines (Sines City Council Archive), showed how, since 2020, they have been preserving web content of local interest in collaboration with Arquivo.pt. They record web pages with ArchiveWeb.page, a Webrecorder tool, send a copy of the files to Arquivo.pt, transcribe images and videos verbatim, and also use PDF as the most traditional format for archiving news. The issue of accessibility to content for people with special needs is fundamental in the preservation process. Presentation.
Finally, Daniel Gomes emphasised how much has been done in the last 17 years in the field of web preservation, to the point where we now have a functional service that everyone can use. As a testimony to those early days, we found a page from Diário Digital newspaper from November 2006.
Panel 3: Preserving the present and safeguarding the future
The third panel was moderated by Paula Meireles, Coordinator of the Archive, Documentation and Information service at the Foundation for Science and Technology (FCT) and brought four other realities to the table.
Filipe Guimarães Silva, Executive Director of the Fundação Mário Soares e Maria Barroso, and António Coelho, Digital Reproduction Coordinator, delved into the technical issues related to digitisation, based on the case of the collection, which is also accessible on the Casa Comum portal. Quality control is the most important factor in obtaining a preservable digital version. You don’t always need expensive technology to get good results. It is essential to follow standards and ensure that quality metadata is generated. Presentation.
Fernanda Gonçalves, Director of Archives at the São João Local Health Unit, showed how the São João Digital Clinical Repository is transforming access to clinical files with advantages in terms of both speed and quality of information. The information management model at this huge institution poses immense challenges for preservation and continued access, as it involves creating interoperability between multiple systems. What’s more, this is sensitive data with different levels of access. This is where the archive comes in as an asset. The archive service must rise to the challenges of any organisation in order to serve all its ‘clients’. Presentation.
Augusto Ribeiro, head of the Documentation and Information Management Service at UPdigital, University of Porto, explained how the university collection is being preserved. From the treatment of paper documents to their digitisation and inclusion in the digital repository, it’s important to guarantee their robustness. This work has been progressive and systematic, i.e. it follows a plan where all the pieces fit together as the work is carried out. Presentation.
Pedro Penteado (DGLAB) presented the ‘Digital Preservation Guide’ project that is being developed in collaboration with the Asociación Latinoamericana de Archivos (ALA). This initiative will structure content on digital preservation in a pragmatic way. Soon, professionals will have a knowledge base to consult whenever they carry out digital preservation activities. Presentation.
Panel 4: Community space
The fourth panel, moderated by Paula Carvalho, from FCT’s Science and Technology Archive, included 9 short presentations submitted by the community. Below, we present the abstracts submitted by the authors:
Justiça do Futuro: + Digital – Alexandra Lourenço, Albertina Catrola, Alexandra Henriques, António Dias, Cristina Ferreira, Inês Nunes, Rute Ramos | SGMJ
It was shown the work that the Commission has been doing to identify archives, documentation centres and collections of all kinds with material about 25 April. There are public collections that are practically unknown, and others that are in private collections. Inventorying and publicising them is therefore the first step in promoting study and knowledge about 25 de Abrril.
Finally, Maria Inácia Rezola announced the award of the Honourable Mention ‘25 de Abril and Democracy’, together with a prize of 5,000 euros, in the Arquivo.pt Award 2025, to the best work on 25 April that uses Arquivo.pt.
Image gallery
Encontro Dia Mundial da Preservação Digital 2024 #WDPD2024
Credits: photos by Leonor Arrimar (FCT). Included are some images of mobile devices sent in by participants.
The month of September marks the beginning of a year’s work and also the end of many websites that are hopelessly lost. Remodelled or shut down without making a good copy of their content, this is how historic websites are lost unnecessarily.
There are tools that allow websites to be saved immediately by the organisations that manage them. In addition, there is the on-demand archiving service for high-quality websites that Arquivo.pt provides to partner organisations or in occasional collaborations.
This article aims to highlight the Browsertrix Crawler used by Arquivo.pt, without excluding other tools, which can be useful to information managers and IT departments.
Use of Browsertrix-crawler by Arquivo.pt for high-quality collections
Browsertrix Crawler is a tool that lets you record entire websites and lists of web pages automatically and in a format compatible with web archives.
Arquivo.pt uses the Browsertrix Crawler to make high-quality site collections (RAQs) on-demand of the community. For example, when a site is about to be shut down, when it’s going to undergo remodelling or, periodically, to maintain a good history of a particular site.
Requests for high-quality collections (RAQs) to Arquivo.pt are increasingly frequent: 77 requests from January to September 2024. This is a sign that there is greater concern about the preservation of web content.
What you need to use Browsertrix-crawler locally
The group that developed the Browsertrix Crawler, Webrecorder.net, led by Ilya Kreymer, has the motto ‘web archiving for all’. Its tools make it possible to record the Internet in a decentralised way and on a small scale.
The Browsertrix Crawler is available and can be installed on your computer for small collections.
The basic version of Browsertrix that Arquivo.pt is using requires basic command line knowledge, which is the only barrier for non-experts.
From Arquivo.pt’s own experience, using the Browsertrix Crawler is easy in multidisciplinary teams, where there is always someone with minimal knowledge to use Linux commands and provide occasional support.
Demonstration of recording entire websites on your own computer
To promote the preservation of sites in Web archive format, Arquivo.pt presents a use case for the Browsertrix Crawler. It’s useful for anyone who wants to deepen their knowledge and practice of saving sites in a local environment.
Other tools used by Arquivo.pt to record content
Brozzler: a tool for improving the history of daily and monthly collection sites
Brozzler is a similar tool to Browsertrix Crawler in that it also bases its recording on a browser. It is used and maintained by the Internet Archive.
Arquivo.pt has been using Brozzler since at least 2018 to record web pages with interactive content present on the web pages and for high-quality collections (RAQs).
Lists of up to 200 sites are successfully recorded by Brozzler. For example, the 125 daily collection sites (FAWP) are recorded with Brozzler at the beginning of each month.During the month, another list of 75 monthly collection sites (MAWP) is recorded using Brozzler.
At the end of 2023, Arquivo.pt compared Brozzler and Browsertrix Crawler and chose to keep these two tools.
Heritrix, pywb and ArchiveWeb.page: tools for thousands of sites or one page
The Heritrix crawler is Arquivo.pt’s main recording tool. It is used on huge lists of websites, such as the .PT domain sites, to which other Portuguese sites are added, totalling more than half a million.
To complete the list of recording tools used by Arquivo.pt, mention should be made of pywb, which comes into play, for example, when an Arquivo.pt user uses the ‘Complete the page’ functionality or the ArchivePageNow service.
Arquivo.pt has contributed to the international collection of web pages on the Summer Olympics Games taking place in Paris from 26 July to 11 August 2024 and is doing the same for the Summer Paralympics taking place from 28 August to 8 September.
The pages of this collection will also be available on Arquivo.pt for those who want to carry out studies on sport and Olympism.
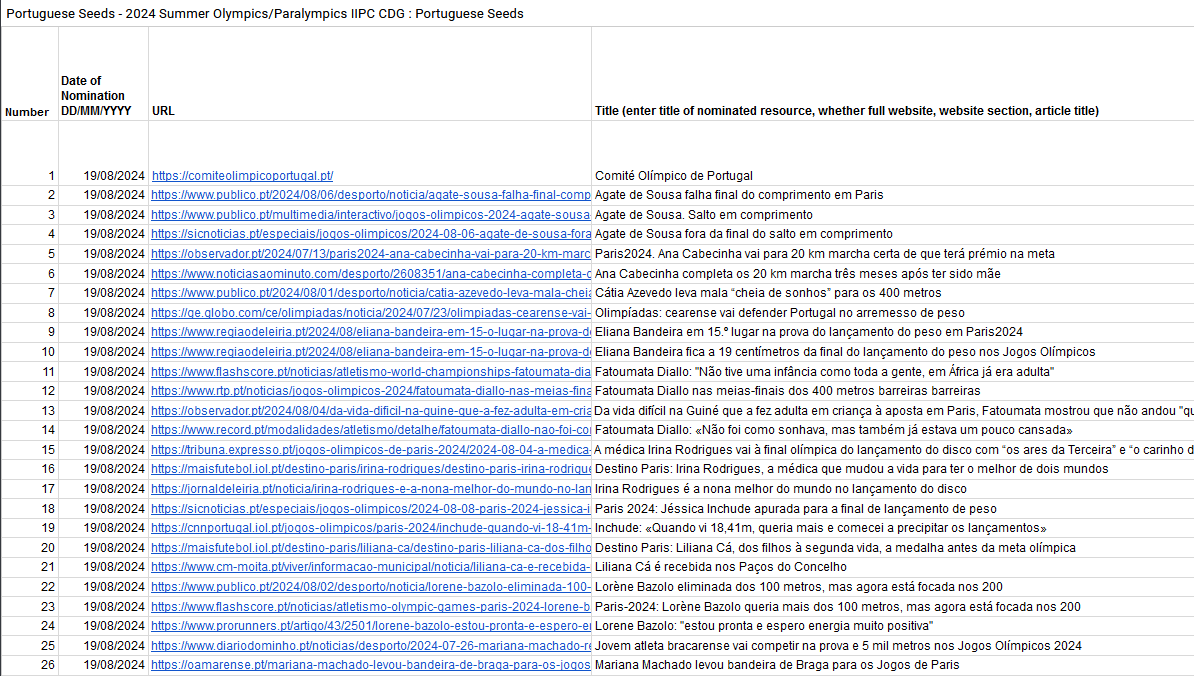
How the pages about Portuguese athletes were selected
At the Olympic Games 73 athletes represented Portugal in 15 sports, and at the Paralympic Games 27 athletes in 10 sports.
The criterion for selecting pages for the international collection was news about the athletes. For each athlete, pages were selected about their expectations before the games, their performance in the competition and their comments during and after the competition.
Some athletes have more news selected than others, and the same goes for the sites from which the news comes. The selection of pages was not limited to the first results presented by the search engine. We looked for a variety of channels and news from regional and local sites, some from the region or city where the athletes came from.
More than 500 pages to remember the Portuguese presence in Paris
The contribution of Arquivo.pt, as you can see in the table, already has more than 500 web pages.
May 18, International Museum Day, was celebrated all over the country with free admission, guided tours, entertainment and exhibitions related to memory and heritage.
Arquivo.pt contributed with an exhibition of old web pages, entitled “Digital Memory through the Internet of the Past”, which was on display at one of the stands at the National Coach Museum in Lisbon.
The pages were selected to show different aspects of the Alentejo over time. From 2016, pages relating to the Heritales project were selected.
Heritales and Crowd-Recycling drew attention to the preservation of the Internet’s memory
Heritales is a project based in Évora that aims to study and disseminate heritage in all its manifestations. It is known for its main event created in 2016, HERITALES – International Heritage Film Festival.
Crowd-Recycling is a project focused on good practices for sustainability.
Heritales, Crowd-Recycling and Arquivo.pt carried out this action in collaboration with the aim of giving visibility to content published on the web over time. Preserving and giving access to digital content is fundamental to enhancing heritage.
Why an exhibition of old websites is a good idea
Making an exhibition of websites over time is relatively easy, all you have to do is come up with a theme, which can also be the history of an institution, and choose pages preserved on Arquivo.pt.
An exhibition of old websites is an original idea for the target audience. It often features texts and images that only existed on the web.
By drawing attention to the websites, we realize that many things were left unrecorded and this changes our view of the content we publish today. We start taking more care to save important pages, for example by taking action or saving them on the spot with SavePageNow.
Heritales, Crowd-Recycling and Arquivo.pt on International Museum Day at the National Coach Museum
World Internet Day was on May 17th
The day before International Museum Day was World Internet Day (May 17). The proximity of the two commemorations ties in with the theme of preserving memory.
Portugal connected to the Internet for the first time in 1991, with the FCCN project “RCCN IP Service”.
The DPC Awards promote exemplary and innovative digital preservation use cases from all over the world.
The Arquivo.pt team submitted two applications to the DPC Awards 2024 in the categories of “Safeguarding the Digital Legacy” and “Research and Innovation”.
The Award for Safeguarding the Digital Legacy celebrates the practical application of preservation tools to protect at-risk digital objects.
The Award for Research and Innovation recognizes excellence in practical research and innovation activities.
Arquivo.pt applications to the DPC Awards
#1 Arquivo.pt catalog of tools for digital preservation
Information that rules modern-day lives is born-digital and disseminated online. However, invaluable digital objects published online have been continuously lost.
Arquivo.pt is a public infrastructure which supports the preservation of digital objects published online to safeguard this digital legacy for future generations.
Images published online are precious digital assets that document contemporary times for future generations.
This initiative describes the research and development of an innovative image search system that enables the discovery and access to billions of preserved images acquired from the web since the 1990s.
This research was applied to enhance the Arquivo.pt web archive with an image search service publicly available to any Internet user, officially launched in August 2022.
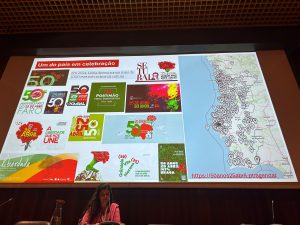
The initiatives were as follows: a journey through time, a special collection on the theme “Abril 25”, a presentation at the “50 years of April International Congress” and the inclusion of a special mention in the 2025 edition of the Arquivo.pt Award.
Memories of April 25 on the Internet exhibition
The exhibition Memories of April 25 on the Internet presents a selection of web pages about the celebrations of April 25 in various regions of the country, since the beginning of the web in the 1990s.
The criteria for choosing the pages for the exhibition were as follows:
Pages relating to the April 25 commemorations;
Pages found on Arquivo.pt on dates close to the anniversary each year;
Diversity to include different areas of the country;
Popular demonstrations and official ceremonies.
A historical memory without web archives is incomplete. The aim of this journey through time is to invite citizens to travel back in time, browsing through old web pages and reliving recent episodes in our life as a democracy.
The dataset contains a list of keywords put into a search engine in order to obtain results on the topic of “April 25”. The search considered names of people, places, political, social and cultural aspects, as well as words associated with the event.
The searches were carried out on March 22, 2024 using the Bing Search API, an automatic search service that returns results according to the relevance criteria of the Bing service itself and others configured by us.
A total of 12,650 unique web page addresses were obtained. It is hoped that the recording of these pages will be useful for the organizations that produced this content, for researchers who want to study our history and for citizens who cultivate a sense of memory and democracy.
Participation in the 50 years of April International Congress
João Gomes, Director of Advanced Services, FCCN-FCT presenting the Arquivo.pt Memorial service at the 50 years of April International Congress
On May 2, 2024, João Gomes, Director of Advanced Services at the FCCN Scientific Computing Unit of the Foundation for Science and Technology I.P., presented Arquivo.pt to the participants of the 50 years of April International Congress, as a distinctive service, open to citizens and useful for organizations.
Arquivo.pt is a web preservation service available to all citizens who want to search for old content published on the web.
Using Arquivo.pt contributes to a better understanding of our history. It also provides useful services for cybersecurity, such as the Arquivo.pt Memorial, which is able to maintain institutions’ old websites, preventing attacks and saving them resources.
Special mention for “April 25 and Democracy” at the Arquivo.pt Awards 2025
In 2025, as part of the celebrations for the 50th anniversary of April 25, a special mention will be made of work on the theme “April 25 and Democracy”.
We therefore challenge researchers and interested citizens to create innovative works using Arquivo.pt.
If you have any questions about the Arquivo.pt Award, please contact us.
The collection of 1 PetaByte of content predominantly in Portuguese, accessible to both researchers and ordinary citizens, is a milestone that deserves to be celebrated, in the month of its 16th anniversary.
At Arquivo.pt you can search for information published on the Web in the past, such as:
Arquivo.pt was created on November 8, 2007 with the aim of preserving content from the Portuguese Web.
In 2013, as a service operated by the Fundação para a Ciência e a Tecnologia (FCT), its mission was formulated as follows: “To promote the preservation of content available on the national Internet, ensuring that it is made available to the scientific community and the general public” (Decreto-Lei no. 55/2013).
In recent years, Arquivo.pt has created new services, such as CitationSaver, which allows researchers to record references to web content in their scientific articles, Memorial and Complete page, which facilitate access to content scattered throughout the huge 1 PetaByte block of data.
Where did so much information come from?
In order to reach the 1 PetaByte volume, Arquivo.pt periodically recorded content from websites in the .PT domain and from Portuguese websites in other domains.
In addition, frequent daily and monthly collections were made from a small number of government sites and the main news sites in Portugal.
As part of international collaborations, content was collected from sites in various languages, for example on the 2019 European Elections.
Content prior to 2008 came from the Internet Archive and donations, such as a collection made by the National Library and INESC on the 2005 Legislative Elections.
The largest Portuguese-language dataset available to researchers
By making 1 PetaByte of information available, in open access and through the use of APIs (Application Programming Interfaces), Arquivo.pt is a useful tool for research.
For example, a researcher who wants to do a study on elections in Portugal can use the entire Arquivo.pt collection. Better still, they can focus on just a few special collections dedicated to the elections, choosing the ones that interest them and downloading just a few Terabytes to process automatically with the APIs.
Contributions from the various teams and friends of Arquivo.pt