The collection of 1 PetaByte of content predominantly in Portuguese, accessible to both researchers and ordinary citizens, is a milestone that deserves to be celebrated, in the month of its 16th anniversary.
At Arquivo.pt you can search for information published on the Web in the past, such as:
Arquivo.pt was created on November 8, 2007 with the aim of preserving content from the Portuguese Web.
In 2013, as a service operated by the Fundação para a Ciência e a Tecnologia (FCT), its mission was formulated as follows: “To promote the preservation of content available on the national Internet, ensuring that it is made available to the scientific community and the general public” (Decreto-Lei no. 55/2013).
In recent years, Arquivo.pt has created new services, such as CitationSaver, which allows researchers to record references to web content in their scientific articles, Memorial and Complete page, which facilitate access to content scattered throughout the huge 1 PetaByte block of data.
Where did so much information come from?
In order to reach the 1 PetaByte volume, Arquivo.pt periodically recorded content from websites in the .PT domain and from Portuguese websites in other domains.
In addition, frequent daily and monthly collections were made from a small number of government sites and the main news sites in Portugal.
As part of international collaborations, content was collected from sites in various languages, for example on the 2019 European Elections.
Content prior to 2008 came from the Internet Archive and donations, such as a collection made by the National Library and INESC on the 2005 Legislative Elections.
The largest Portuguese-language dataset available to researchers
By making 1 PetaByte of information available, in open access and through the use of APIs (Application Programming Interfaces), Arquivo.pt is a useful tool for research.
For example, a researcher who wants to do a study on elections in Portugal can use the entire Arquivo.pt collection. Better still, they can focus on just a few special collections dedicated to the elections, choosing the ones that interest them and downloading just a few Terabytes to process automatically with the APIs.
Contributions from the various teams and friends of Arquivo.pt
The new release of Arquivo.pt named Helios was launched on November 13, 2023 and includes developments in Arquivo404 and CitationSaver.
Arquivo404 with new methods for defining time intervals
Arquivo404 is a service that presents website users with links to web-archived versions, instead of laconic “Page not found” error messages.
However, sometimes it is necessary to specify the correct version of a web-archived page to be displayed. For example, a website’s domain may have belonged to another entity in the past, and only web-archived versions since the website came under its current owners should to be displayed.
setMinimumDate( minDate : Date ) – specifies the earliest date of the web-archived version of the URL that can be displayed.
setMaximumDate( maxDate : Date ) – specifies the latest date of the web-archived version of the URL that can be displayed.
setMostRelevantMemento( criterion : ‘oldest’ | ‘most-recent’ ) – specifies the order of results for the versions retrieved from the web archive. By default, the oldest version is displayed ( ‘oldest’ ).
In short, Arquivo404 now allows you to define whether to display the oldest or most recent web-archived page to the users, within a certain time interval.
CitationSaver processes HTML documents
CitationSaver is a service that extracts citations in documents to online resources and archives them. This service is particularly useful for maintaining the integrity of scientific articles and the reproducibility of the experiments and studies described in them.
Many open-access articles are published in hypertext format (HMTL). CitationSaver now processes documents in HTML format, in addition to PDF and TXT formats.
For example, if a user finds an article on the Web which contains citations to online resources, he/she simply needs to submit the URL of the article into CitationSaver. The URLs cited in the article will be extracted and their content will be web-archived for later access.
The event, which took place in the auditorium of the Polícia Judiciária in Lisbon, was attended by representatives from the government’s justice department and professionals from the archives, communications and IT departments.
How to use Arquivo.pt to preserve institutional websites
Arquivo.pt took part in the presentation “Preserve your website”, which addressed the issue of preserving institutional websites and critical aspects such as cybersecurity.
Justice entities can benefit from Arquivo.pt and its various services to ensure good preservation of their websites, mitigate cybersecurity threats and provide historical content to citizens.
The presentation concluded with the following recommendations:
Inventory and publicize your current and historical websites
To promote the use of the Arquivo.pt in the context of teaching, research or professional usage, three partners institutions promoted honorable mentions with an associated prize.
The Público newspaper will award an Honorable Mention to works based on the Público online content preserved by Arquivo.pt.
The Aveiro Media Competence Center (AMCC) will award an Honorable Mention to the best work on the web archive of one or more Portuguese online media.
Association DNS.PT will award an Honorable Mention to a professor or teacher who has encouraged the submission of works.
Share and spread the word!
Help us spreading the word about the Arquivo.pt Award 2024 among potential candidates!
More than 100 historical websites from the Faculty of Sciences of the University of Lisbon (FCUL) are now accessible through the Memorial service of Arquivo.pt.
FCUL’s IT Department sent to Arquivo.pt a list of old websites hosted on its servers that were no longer updated, but whose historical content continues to be interesting to the community (e.g. websites of research projects or scientific events).
Arquivo.pt preserved these websites in collaboration with their ownersa, seeking to maintain a faithful representation of the published content for the future.
FCUL redirected the domain of each website to Arquivo.pt, and then, became able to disconnect the respective servers and begin sparing the resources spent on their maintenance (e.g. electricity, data center space, human resources).
The MiNEMA scientific program website was the first that FCUL integrated into the Memorial. This website stopped being updated in 2009 when the project ended. FCUL invested resources in maintaining the website for another 10 years until it became necessary to suspend it down for cybersecurity reasons.
The Memorial of Arquivo.pt emerged as an option and since 2020, FCUL just needs to maintain the domain www.minema.di.fc.ul.pt while Arquivo.pt preserveS the information contained on the website.
Follow FCUL and preserve your historical websites in the Memorial!
An increasing number of institutions are recurring to the Memorial of Arquivo.pt to safely preserve the content of their historical websites. For example, FCUL preserved 116 websites, the Government IT Network Management Center preserved 23 and the Foundation for Science and Technology preserved 40.
Public institutions have priority to benefit from this service. However, other entities can also request it as long as they own the website domain.
Identify your historical websites candidate to be integrated into the Memorial of Arquivo.pt and contact us!
Some web-archived pages are reproduced incompletely due to problems occurred during the archiving process (e.g. deformatted or missing embedded images).
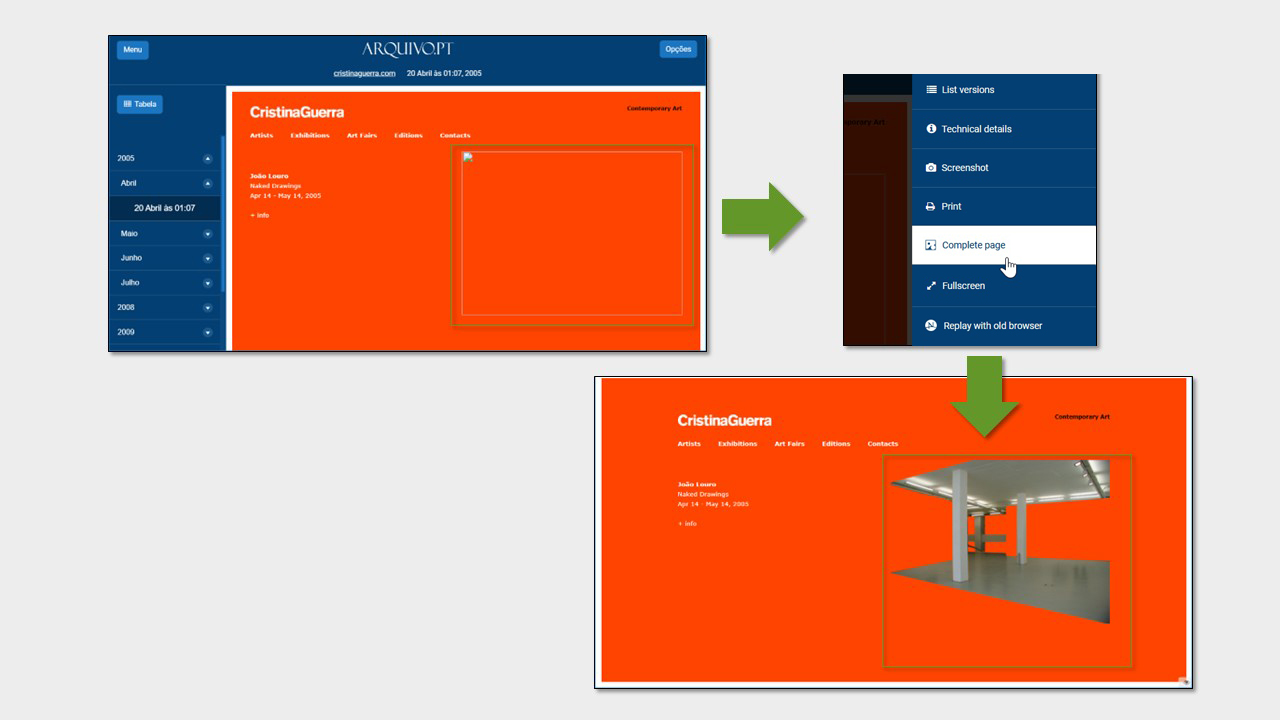
Complete page is a function of Arquivo.pt that allows to recover missing elements in web-archived pages, from other web archives or the original websites.
When a user views a page archived in Arquivo.pt, just needs to access the Options menu in the top right corner and choose Complete page.
This process is performed automatically.
How does Complete page work?
If you open a web-archived page that appears incomplete, try the Complete page option and wait.
Arquivo.pt will search for missing elements on the Internet and in other web archives using the Memento protocol. If it succeeds, the obtained elements will be immediately displayed on the web-archived page.
Later, these recovered elements are integrated into the Arquivo.pt collection, so that the web-archived page will appear more complete in the future accesses performed by any user.
Completing the home page of artist Cristina Guerra’s website found a missing image.
For example, the website of artist Cristina Guerra archived in 2005 had a missing image. By using Complete page, it was possible in 2021 to obtain this missing image from another web archive which preserved it.
Participate in collaborative curation to improve the quality of Arquivo.pt!
Due to the high number of web-archived pages, it is not possible for Arquivo.pt to complete them all automatically. Therefore, the collaboration of users to identify important pages with missing elements and try to complete them is important.
By using Complete page, the users are contributing to improve the quality of the historical webpages preserved in Arquivo.pt!
Always give it a try to complete web-archived pages may that look incomplete. If you detect any problem, contact us.
Spread the word about the Arquivo.pt Complete page!
Arquivo.pt preserved online documents in several languages about the 2019 European Parliamentary Elections
The 2019 European Parliamentary Elections were an event of international relevance. The strategy to preserve the relevant information on the World Wide Web is delegated to national institutions. However, the preservation of web pages that document transnational events is not officially assigned.
The Arquivo.pt team, with the aim of preserving the cross-lingual online content that documents this event, applied a combination of human and automatic selection processes.
In the first step, 40 relevant terms in Portuguese about the 2019 European Parliamentary Elections were identified, and then, automatically translated into the 24 official languages of the European Union: Bulgarian, Croatian, Czech, Danish, Dutch, English, Estonian, Finnish, French, German, Greek, Hungarian, Irish, Italian, Latvian, Lithuanian, Maltese, Polish, Portuguese, Romanian, Slovak, Slovenian, Spanish and Swedish.
These translations were reviewed in collaboration with the Publications Office of the European Union. Besides that, in parallel, a collaborative list was launched to gather contributions of relevant seeds from the international community.
In the second step, the Arquivo.pt team iteratively ran 6 crawls (99 million web files, 4.8 TB) using different configurations and crawling software, to maximize the quality of the collected content.
The obtained web-data was aggregated into one special collection identified as EAWP23 and became searchable and accessible through Arquivo.pt in July 2020 (https://arquivo.pt/ee2019).
CLEOPATRA project: Cross-lingual Event-centric Open Analytics Research Academy
Daniel Gomes and Diego Alves at presenting at CLEOPATRA final event
The CLEOPATRA ITN was a Marie Skłodowska-Curie Innovative Training Network aimed to generate ways to better understand the massive digital coverage of major events in Europe over the past decades.
The main goal was to facilitate advanced cross-lingual processing of textual and visual information related to key contemporary events at large scale and develop innovative methods for efficient access and interaction with multilingual information.
In total, 14 Early-Stage Researchers hosted across 9 European Universities developed their research while enrolled as Ph.D. students.
Associated partners such as Arquivo.pt contributed to CLEOPATRA by hosting and training early-stage researchers such as Diego Alves. As part of the training program, he conducted a secondment at Arquivo.pt in Lisbon from June to August 2022.
The idea was to develop part of his research about syntactic structures of EU languages using the textual resources preserved by the Arquivo.pt and exchange knowledge with the web-archiving experts on the strategies to extract and process historical web-data.
Generating textual datasets for Natural Language Processing
Diego Alves’ work originated cross-lingual datasets about the 2019 European Parliamentary Elections precious for research.
This work will be detailed in chapter “Robustness of Corpus-based Typological Strategies for Dependency Parsing” of the open-access CLEOPATRA book entitled “Event Analytics across Languages and Communities”.
A 3-step Natural Language Processing pipeline was developed to generate research textual datasets that can be used in several types of digital humanities studies:
Extract text: The textual content was extracted from each web-archived URL using the newspaper3k Python library. The language of each extracted text was determined using the langdetect library, to separate the texts written in different languages across distinct files;
Clean extracted texts: a Python script was applied to clean the texts by removing unnecessary information (e.g.: repeated instances, empty lines, etc.);
Double-check of language identification: the language of each cleaned extracted text was verified again to eliminate possible errors originated during the previous steps.
Two new research datasets are openly available!
The result was a dataset of cleaned and language-verified texts publicly available. Each file contains the texts in a given language about the 2019 European Union Elections. The distribution of extracted texts for each language is described in the figure below:
Number of tokens of each corpus extracted from the collection 2019 European Union Elections preserved by Arquivo.pt (EAWP23).
The aforementioned corpus was automatically annotated regarding part-of-speech and dependency relations to generate a corpus with syntactic information which is useful for linguistic studies.
The texts in these annotated corpora followed the same order of the respective raw-texts files. Each sentence is annotated following the Universal Dependencies framework in the CoNNL-U format, which is the reference in terms of syntactic annotation in Natural Language Processing. Thus, each file in this dataset contains the annotated texts in a given language about the 2019 European Union Elections
Wikipedia articles reference external web pages with important complementary information that became unavailable on their original websites.
One of the most used online resources for educational purposes are Wikipedia articles. However, Wikipedia articles sometimes reference external web pages with important complementary information which disappeared from their original websites. This problem degrades the quality of Wikipedia as a credible and verifiable source of information.
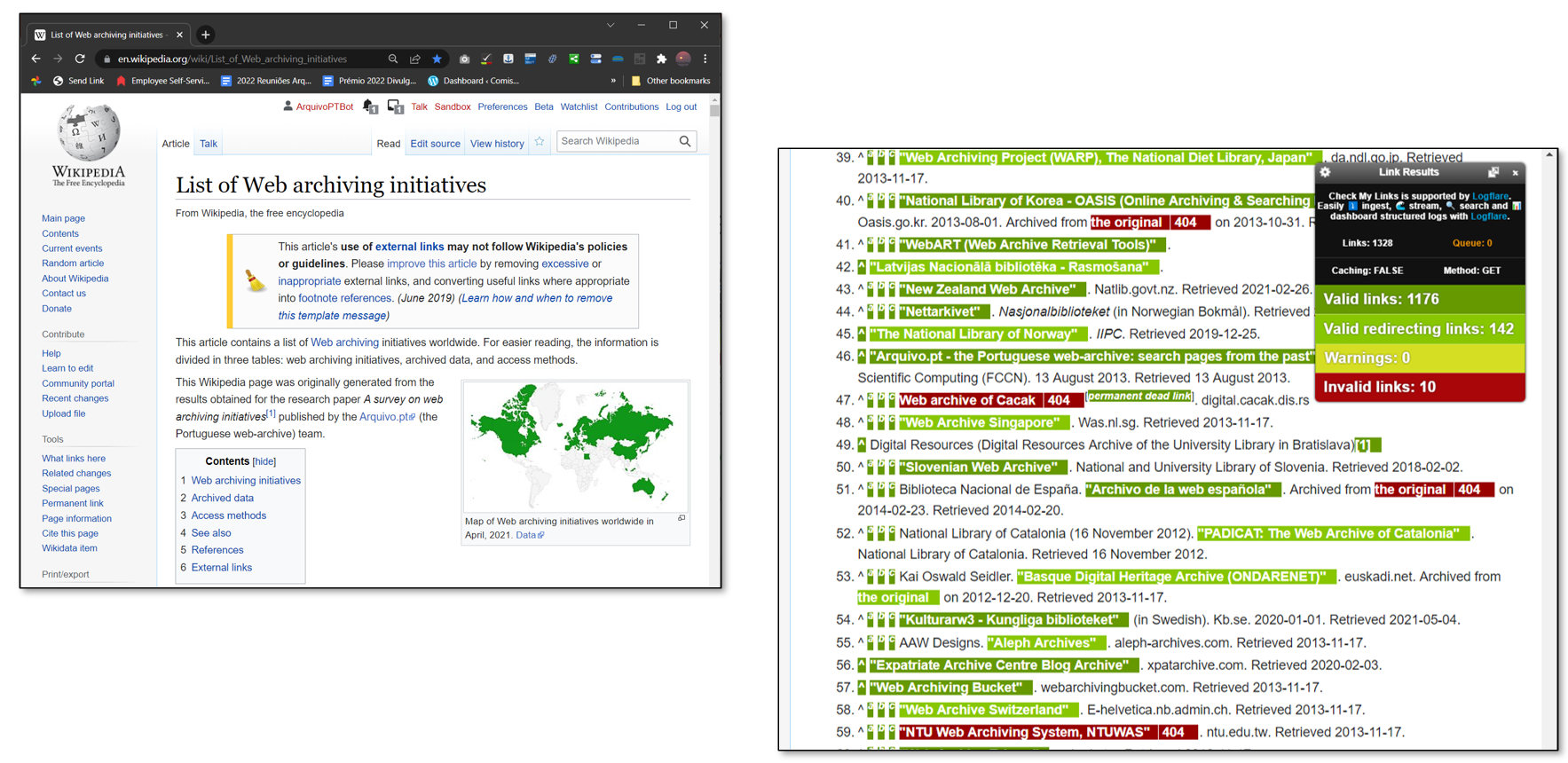
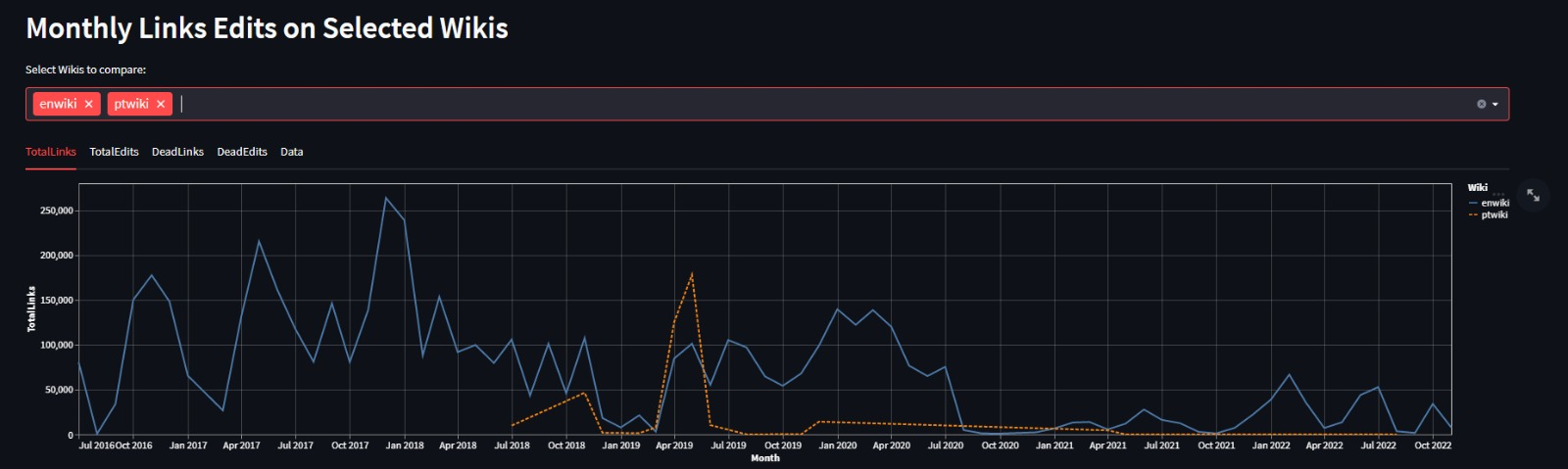
In August 2023, the Arquivo.pt team carried out an experiment to measure the percentage of external links (outside the wikipedia.org domain) that were broken in Portuguese Wikipedia articles. The obtained results showed that 25% of the external links referenced in the Portuguese Wikipedia were broken.
There is also the problem that a link may refer to an accessible web page, but its content changed meanwhile and it is no longer what it was meant to be referenced (Content Drift problem). The domain of the hosting website may have meanwhile been purchased by third parties, for example for malicious purposes.
To mitigate these problems, Arquivo.pt launched a project to preserve the online references contained in Portuguese Wikipedia articles in collaboration with Wikimedia Portugal. The objective was to change the references to broken links on Wikipedia articles, to start referencing web-archived content preserved in Arquivo.pt, thus keeping the referenced information accessible to Wikipedia users.
Arquivo.pt archived the pages referenced in Portuguese Wikipedia articles
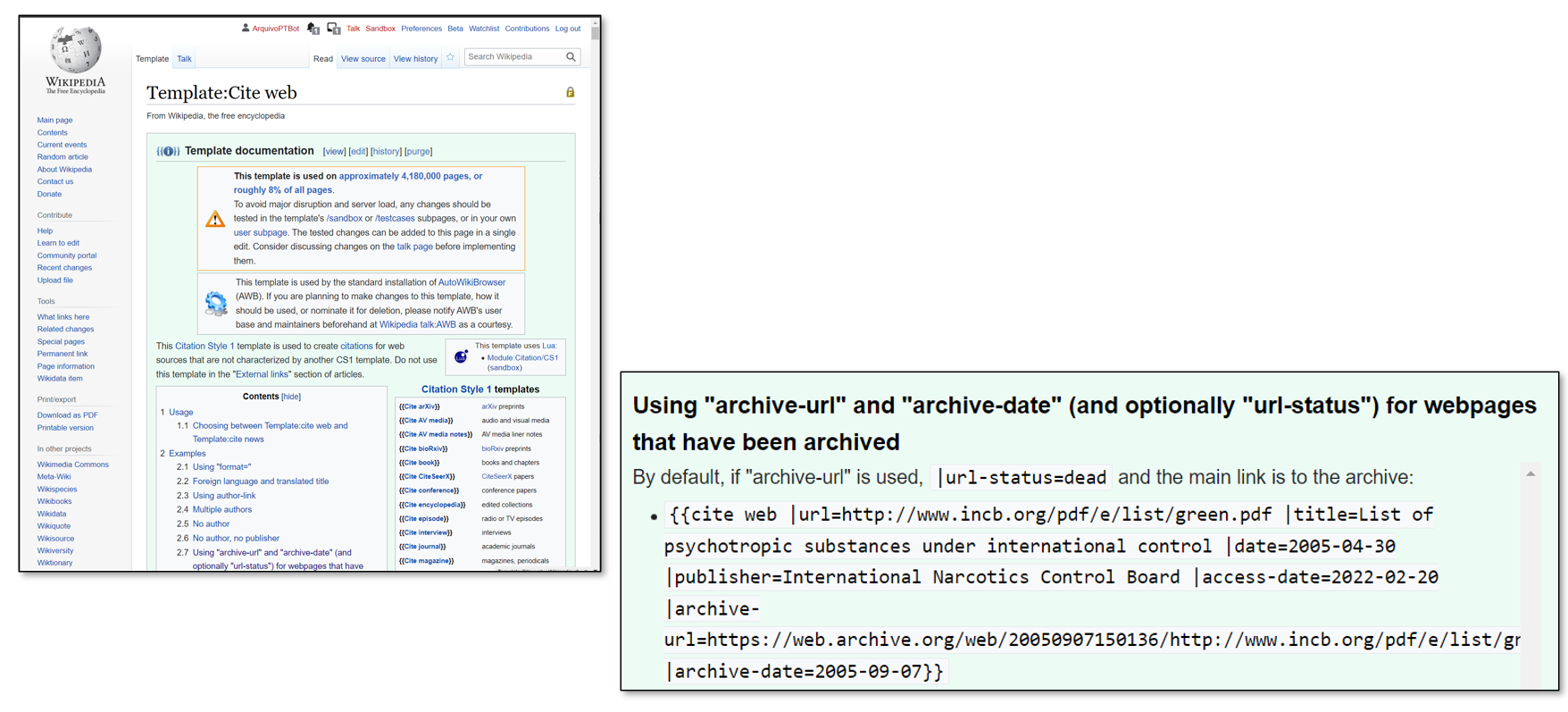
Wikipedia recommends citing web archives (archiveurl/archive-url parameter).
The main result of this project was the creation of a new automatic process for extracting and collecting external links cited on Portuguese Wikipedia pages. Therefore, Arquivo.pt will perform an annual crawl of Wikipedia citations.
Attempt to automatically fix broken links in Wikipedia articles
InternetArchiveBot offers powerful operation and monitoring tools (e.g. Dashboard and Insights)
There are software robots which automatically add links to web-archived content when they find broken links in Wikipedia articles (e.g. Pywikibot, Wayback Medic or InternetArchiveBot).
An experiment was carried out to create an ArquivoPTBot based on the InternetArchiveBot because it offers powerful operation and monitoring tools (e.g. Dashboard and Insights ) and it is maintained by the Internet Archive: the largest web archive in the world.
However, it was not possible to launch this service in production because it implies changes in the software to use Arquivo.pt as a source of web-archived information.
If you want to collaborate to resume this project, please contact us!
Preserving Wikipedia references is at your fingertips!
Arquivo.pt remains committed in contributing to preserve links cited in Wikipedia articles and offers the following services that may be useful to you.
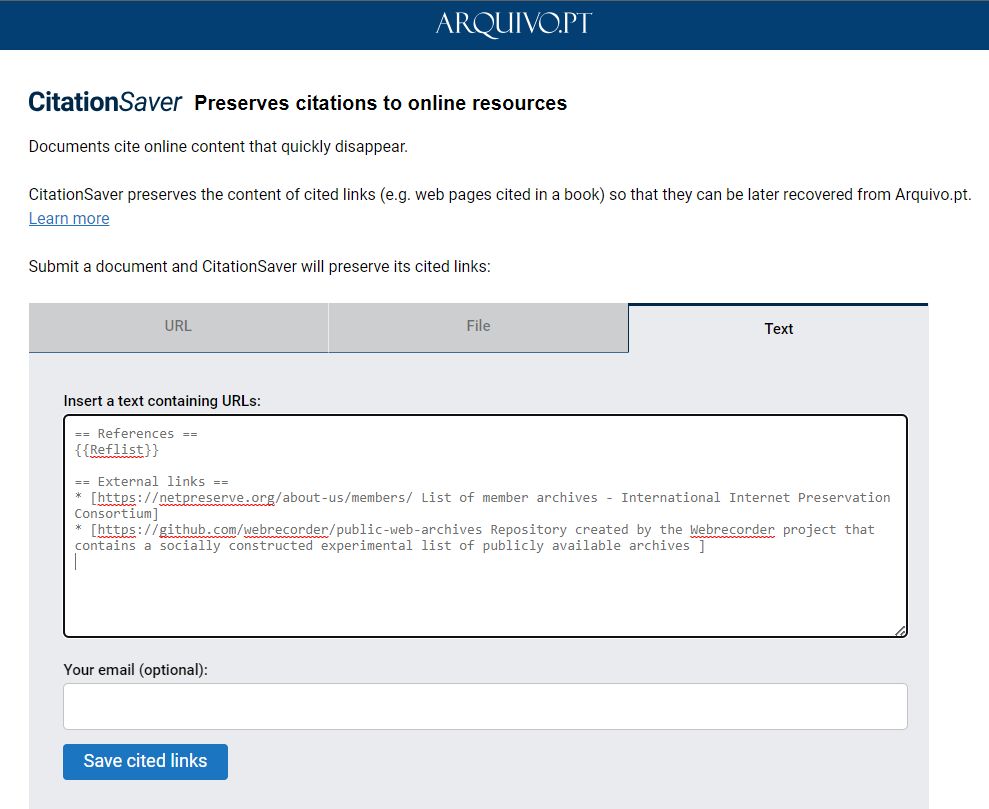
Arquivo.pt CitationSaver: preserves citations to online content (https://arquivo.pt/citationsaver).
CitationSaver allows you to submit the source code of an Wikipedia article and Arquivo.pt will automatically extract the referenced links and archive the correspondent content.
Arquivo.pt ArchivePageNow: saves pages in Arquivo.pt (https://arquivo.pt/archivepagenow).
SavePageNow allows you to immediately archive a web page in Arquivo.pt, for example, that is being referenced in a Wikipedia article so that it doesn’t get lost.
Training Arquivo.pt/Wikimedia
Wikimedia Portugal, in collaboration with Arquivo.pt, promoted a set of webinars to capture the community’s attention for the preservation of content published and cited on Wikipedia. The videos and slides of these webinars are available:
The winner of the 10 000 euro prize was the work “Viajar no tempo sobre carris” (Travelling through time on rails) developed by Antero Pires, Carlos Cipriano, Diogo Ferreira Nunes and Ruben Martins.
“Viajar no tempo sobre carris” is an online platform that analyses and presents the evolution of train travel times in Portugal, based on timetables preserved in Arquivo.pt.
For example, it allows you to see the duration of the journey Lisbon-Oporto on the Alfa Pendular since the year 2000.
This work resulted in the website Existo that provides information on Portuguese artists, referring to the web pages in which they were mentioned over time. The work is based on an analysis of their representation and visibility that allows several readings.
For example, we can find information about the artist Joana Vasconcelos, news about other artists in a certain year or even get a graphic visualization of women artists compared to men.
The 3rd prize of 2 000 euros was awarded to the work “Memória Política”, (Political Memory) developed by Miguel Lopes, Maria Carneiro and João Andrade.
“Memória Política” is a Web application that processes and presents information taken from the web pages of political parties represented in the Portuguese Parliament, archived by Arquivo.pt.
For example, it allows you to search for the term “democracy” and obtain pages from the websites of the Parties related to the search. The results can be grouped by Party and by year.
The Público newspaper, official partner of the 6th edition of the Arquivo.pt Prize, awarded an Honourable Mention to the work “Fábrica do Jornal” (Newspaper factory), carried out by Miguel Almeida.
“Fábrica do Jornal” is a Web application that allows the user to generate a personalized newspaper from the news preserved at Arquivo.pt. The user can obtain a version that can be printed or saved in digital format.
The awards ceremony took place at the closing session of the Science 2023 Meeting, at the University of Aveiro, on 7 July 2023.
The awards were presented by the Minister of Science, Technology and Higher Education, Elvira Fortunato, the President of the FCT Board of Directors, Madalena Alves and the Executive Director of the Aveiro Media Competence Centre, João Moraes Palmeiro.
On the following days, May 11 and 12, the IIPC Web Archiving Conference (IIPC WAC) was held, an initiative open to the community, where people or entities not associated with the IIPC and interested in the Web preservation domain can participate.
Contributions from the Arquivo.pt at the Web Archiving Conference
Arquivo.pt participated in the IIPC working group meetings (Training Working Group and Curators Working Group) and contributed with presentations in the thematic sessions Collaborations & Outreach and Program infrastructure (sessions 7 and 17).
Arquivo.pt contributed with presentations to the sessions Web Archive in Mediterranean area and its merge (4.A), From online Tools to Web Archive (6.B.), Towards a participatory approach to collections (9. A.), Digging up the materials for writing web history (9.B.).
How to research governmental web data? (abstract, slides)
Arquivo.pt has participated in three courses: Incentives design for hybrid multilingual information processing and analytics, in Southampton; National and transnational media coverage of European parliamentary elections, 2004-2014, London; and NLP for under-resourced languages, in Zagreb, Croatia.
In 2022, the Arquivo.pt welcomed two researchers in its facilities who used the archived resources and received special support from the Arquivo.pt team to develop their research.
The CLEOPATRA Project ended in 2023 with a meeting on the 16th May, in Hannover, which brought together Professors, Researchers and representatives of the institutions involved.
Daniel Gomes, Arquivo.pt’s Manager, highlighted the new tools that Arquivo.pt makes available and the results of the work carried out by the researchers that have passed through Arquivo.pt.
Secondments@Arquivo.pt and new research tools available (slides)








.")








































{kind=link}