
Last updated on May 13th, 2025 at 02:29 pm
The interconnected nature of the World Wide Web has long fascinated researchers and technologists alike. Today, we are thrilled to announce the release of the Arquivo.pt Links dataset, a comprehensive collection that opens new possibilities for understanding and analyzing web connectivity patterns.
The dataset encompasses more than 139 million webpage URLs, each accompanied by crucial metadata about their incoming links – both the source URLs and their corresponding anchor texts, i.e., visible and clickable text in hyperlinks. This rich collection of interconnection data provides researchers with a unique window into the web’s underlying structure.
The importance of hyperlinks in web architecture cannot be understated. They serve as the fundamental building blocks of web navigation and discovery, enabling both users and automated systems to traverse the vast landscape of online content.
Links formed the foundation of Google’s revolutionary PageRank algorithm, which transformed our approach to information retrieval and web search. PageRank’s fundamental insight – that a page’s importance could be measured by analyzing its incoming links – revolutionized search technology and remains influential in modern information retrieval systems.
By making this dataset publicly available, Arquivo.pt enables researchers to explore similar innovative approaches to web analysis and search engine development. The dataset opens up numerous exciting research possibilities across multiple domains:
- Researchers can implement and experiment with various ranking algorithms, from classic approaches like PageRank to modern machine learning-based techniques. The inclusion of anchor texts provides valuable semantic context that can enhance search relevance and document classification.
- The dataset enables deep analysis of web topology and link structures. Researchers can investigate questions about web connectivity patterns, identify clusters of related content, and study how information spreads across the web through link networks.
- The anchor text associated with each link offers a rich source of human-generated descriptions of web content. This data can be particularly valuable for developing and testing document summarization algorithms, semantic analysis tools, and automated classification systems.
- For web archiving researchers, this dataset provides insights into how web pages are connected and referenced over time, offering valuable data for studying web preservation strategies and digital heritage maintenance.
Methodology
The process begins with a temporal snapshot of web pages from a specific time period (collection). During this initial phase, our systems analyze each captured page, extracting all outgoing hyperlinks along with their associated anchor texts and capture timestamps. This creates a preliminary mapping of how pages connect to one another within our captured timeframe.
What makes this dataset particularly valuable is its inverted link structure. Rather than organizing the data around source pages and their outgoing links, we’ve created an inverted map that centers on destination pages and their incoming links. This approach is particularly useful for analyzing a page’s importance or authority within the web’s structure, as it provides immediate access to all pages that reference or point to a given URL.
Consider a traditional link structure where Page A links to Pages B, C, and D. In our inverted structure, we instead see entries for Pages B, C, and D, each listing Page A as a source of incoming links. This reorganization of the data facilitates more efficient analysis of page authority and influence, making it particularly valuable for researchers working on ranking algorithms or studying information flow patterns across the web.
The Arquivo.pt links dataset combines three distinct web collections:
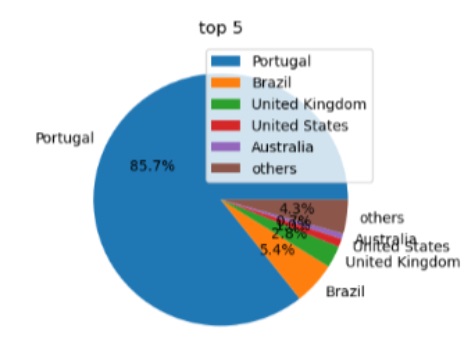
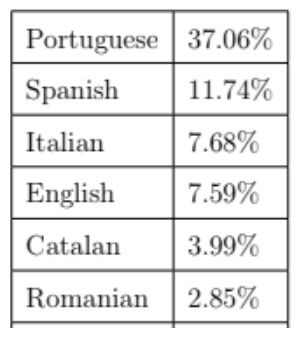
- PWA9609 (1996-2009): 89 million pages capturing early Internet evolution, focused on the .pt domain. This historical collection provides insights into early web linking patterns.
- AWP38 (Oct-Nov 2021): 44 million pages offering a contemporary snapshot of web connectivity, with emphasis on the .pt domain while including broader Internet content.
- FAWP47 (Oct-Dec 2021): 8 million pages from daily captures of .pt domain content, designed to track short-term changes in link patterns.
Getting Started with the Dataset
Researchers can access the complete dataset. The data is provided in a format that supports efficient processing and analysis, making it suitable for both large-scale studies and focused investigations.
Conclusion
The release of the Arquivo.pt links dataset represents a significant contribution to the web science research community. By making this rich collection of web connectivity data freely available, we hope to facilitate innovative research and deepen our understanding of the web’s complex structure.
We encourage researchers to explore this dataset and look forward to seeing the novel insights and applications that emerge from its analysis. Whether you’re interested in developing new search algorithms, studying web topology, or investigating content relationships, this dataset provides a robust foundation for your research.







.")


