O Arquivo.pt lançou uma nova versão denominada Isis, no dia 7 de janeiro de 2025.
Suporte ao Flash utilizando o emulador Ruffle
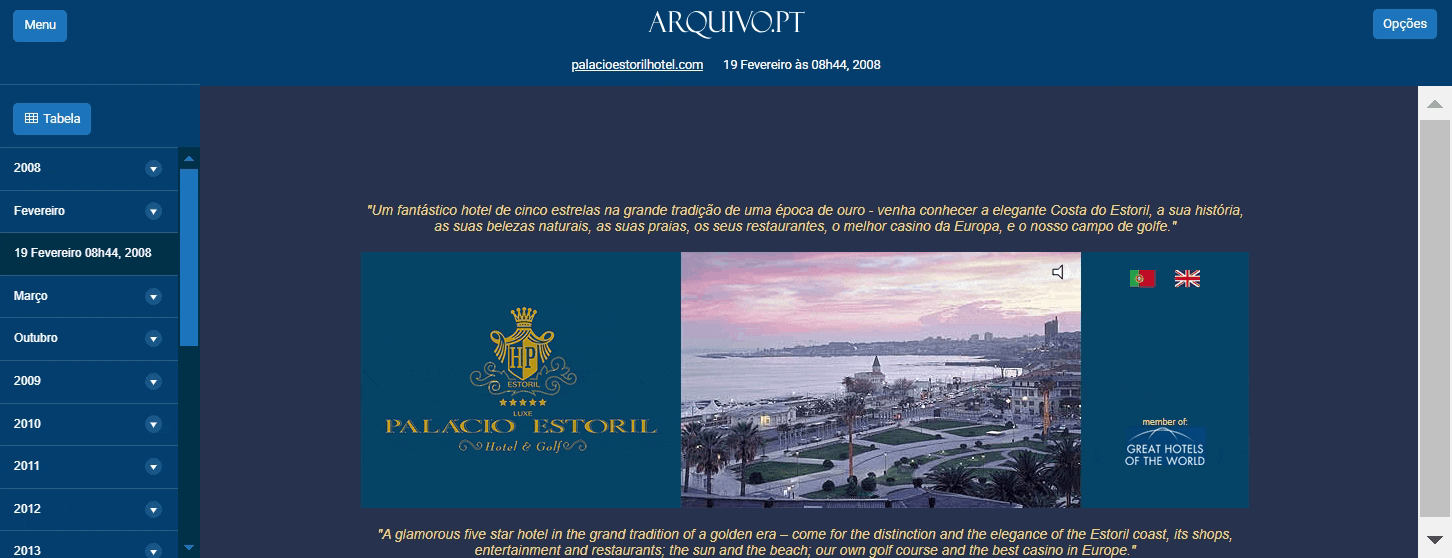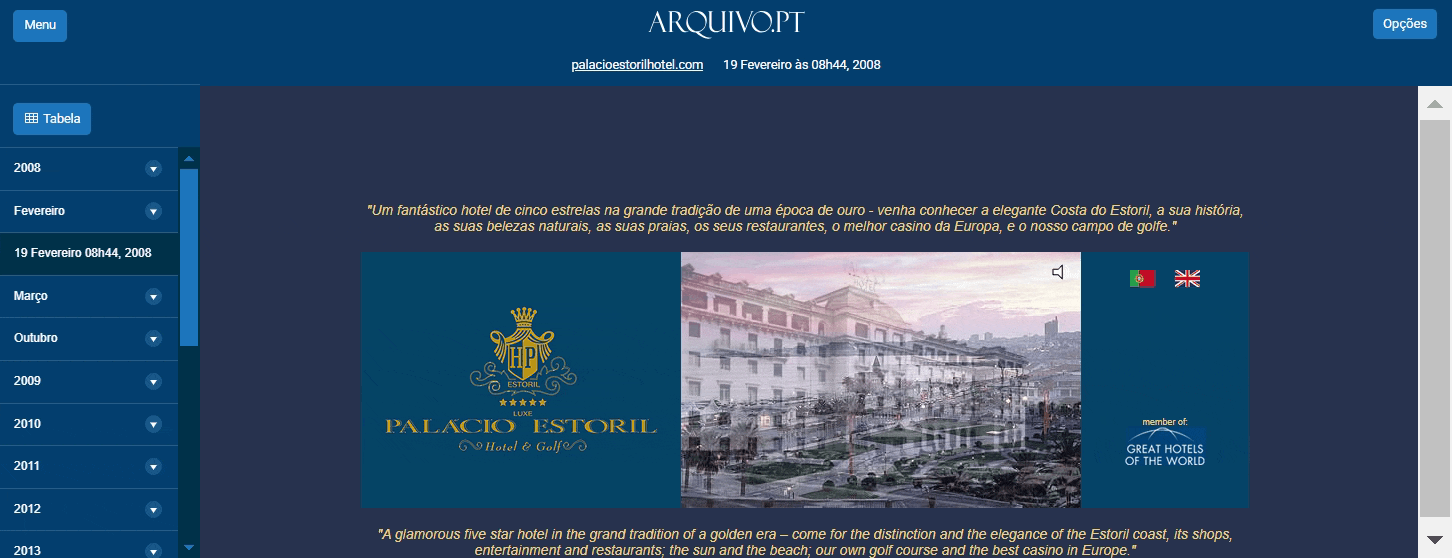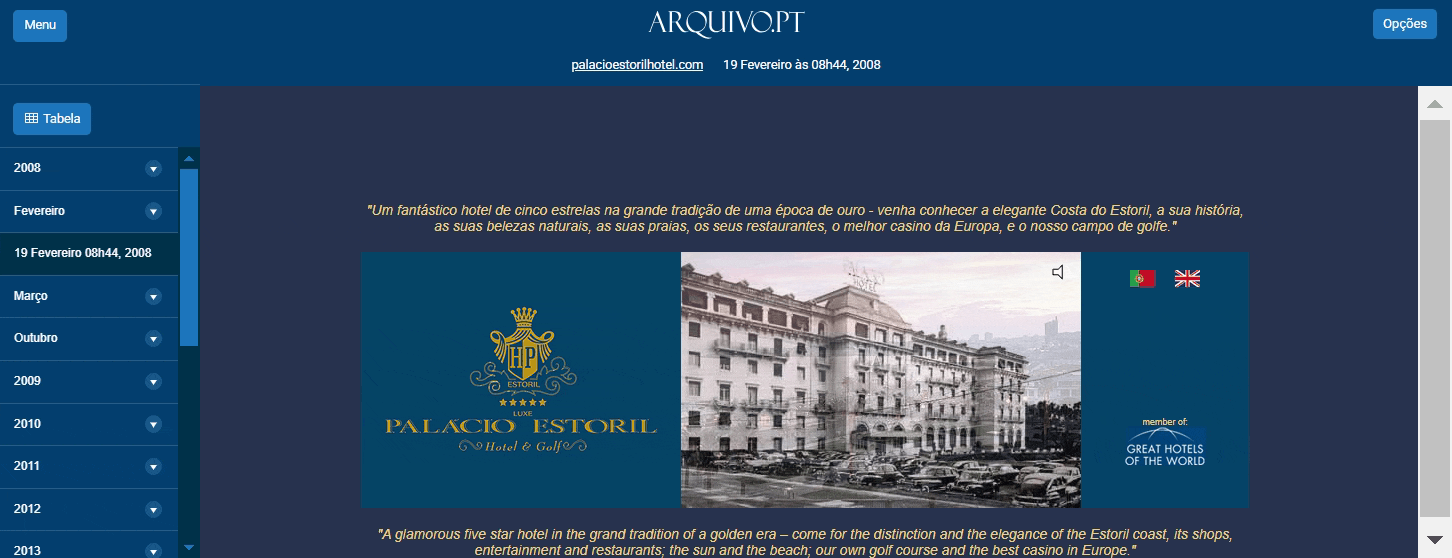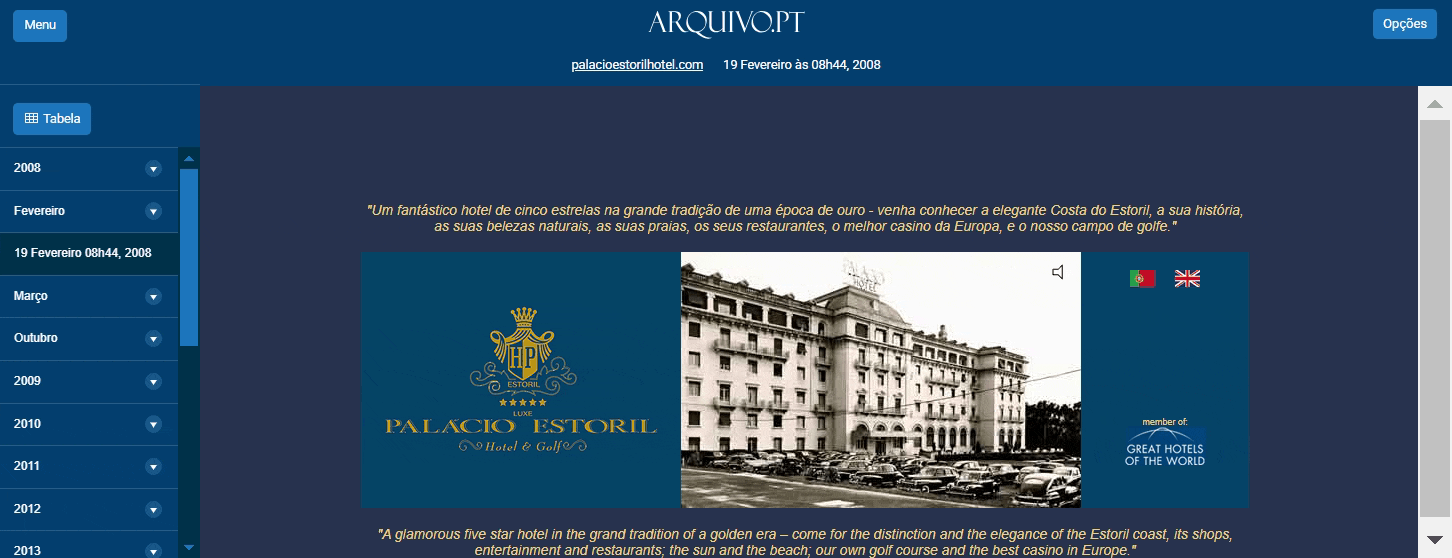
Na nova versão do Arquivo.pt, destaca-se a funcionalidade que permite agora reproduzir animações e conteúdos interativos em Flash.
A tecnologia Flash foi utilizada em websites nos primeiros anos da Web.
Porém, tornou-se obsoleta e os navegadores atuais, tais como o Google ou o Edge, deixaram de lhe dar suporte, impedindo a visualização desses conteúdos. A emulação por software é uma forma de dar acesso a conteúdos produzidos por tecnologias obsoletas.
Assim, o Arquivo.pt incluiu o Ruffle, um emulador de Flash Player que permite visualizar conteúdos em Flash, anteriormente inacessíveis ao utilizador.
Animações em Flash preservados no Arquivo.pt: antes e depois
Aceda aos sites em Flash no Arquivo.pt, antes e depois do uso do Ruffle, tendo em conta que muitos deles foram criados para serem vistos em computadores de secretária e podem ter limitações em dispositivos móveis.
Para promover a utilização do acervo do Arquivo.pt, no contexto do ensino e investigação ou no contexto profissional, quatro parceiros do prémio criaram menções honrosas com um prémio associado.
O jornal Público atribuirá uma Menção Honrosa para os trabalhos realizados com base nos conteúdos do Público online guardados no Arquivo.pt. Esta distinção inclui dois anos de assinatura do Público online.
O Aveiro Media Competence Center (AMCC) atribuirá uma Menção Honrosa ao melhor trabalho sobre o arquivo da web de um ou vários media online portugueses (500 €).
A Associação DNS.PT atribuirá uma Menção Honrosa a um professor que tenha incentivado a submissão de trabalhos (1900 € para aquisição de um computador portátil).
A Comissão Comemorativa 50 Anos 25 de Abril atribuirá uma Menção Honrosa acompanhada de um prémio de 5.000 € a um dos trabalhos submetidos que use o Arquivo.pt para tratar o tema “25 de Abril e a Democracia”.
A iniciativa conta com o Alto Patrocínio do Presidente da República Portuguesa.
Partilhe e divulgue
Ajude-nos a divulgar o Prémio Arquivo.pt 2025 por potenciais candidatos.
O Arquivo.pt foi reconhecido na categoria “Promoção da Sociedade mais Inovadora e Digital”.
Esta categoria destaca a vertente inovadora na transição digital das organizações.
O gestor do Arquivo.pt, Daniel Gomes, e o encarregado das recolhas do Arquivo.pt, Pedro Gomes, estiveram presentes na cerimónia que decorreu em Oeiras, no dia 3 de dezembro de 2024.
Arquivo.pt, um serviço para a transformação digital
Daniel Gomes, num vídeo preparado para a cerimónia de entrega de prémios, explica como um serviço de preservação da Web contribui para uma sociedade da informação mais sustentável.
O Prémio Transformação Digital (4ª edição em 2024) tem por objetivo “reconhecer e divulgar as melhores práticas de adoção e implementação das tecnologias de informação e comunicação (TIC), com vista a uma sociedade mais digital sustentada por instituições públicas e privadas mais eficiente e mais próximas do cidadão” (website da APDSI).
A edição de 2024 teve 33 candidaturas integradas em três categorias:
Eficácia/Eficiência das Organizações
Proximidade com o Cidadão e Sociedade mais inclusiva
Mensagem do Professor Doutor José Tribolet acerca do Arquivo.pt, enviada para a cerimónia de entrega de prémios:
“Um conjunto de funcionários públicos com grande visão, enorme perseverança e continuidade, dotaram o país das bases da ‘Torre do Tombo digital’ da produção em português existente que foi emergindo na Net, memória fundamental para alimentar muitas aplicações e serviços, existentes e a existir, e permitir análises e investigações relevantes para a nossa cultura e o nosso devir como portugueses.”
O objetivo desta equipa conjunta da FCT foi precisamente provocar o encontro e a partilha de experiências entre diversas instituições que têm inevitavelmente de gerir informação, quer em formatos tradicionais como o papel, quer em formatos digitais.
O encontro teve 243 participantes e 29 oradores. Nove das 27 apresentações foram submetidas para uma a sessão denominada “Espaço comunidade”.
A informação digital foi o fio condutor das intervenções. Na abertura, o Diretor da Direção Geral do Livro, dos Arquivos e das Bibliotecas, Silvestre Lacerda, lembrou que a DGLAB foi pioneira entre as entidades públicas na abordagem à questão da preservação digital. O vice-presidente da FCT, Francisco Santos, sublinhou o valor económico que representam os dados para a investigação científica.
Preservação digital não se trata apenas de tecnologia, como referiu Henrique São Mamede, Professor da Universidade Aberta, INESC TEC na conferência de abertura. Trata-se também das pessoas, do fator humano, do ambiente exterior às organizações e das novas sensibilidades, como a sustentabilidade e a ecologia. Daí a importância de criar pontes, de usar por exemplo, a Inteligência Artificial articulando-a com a ética. Slides.
Ao longo do dia, quatro painéis agregaram apresentações sobre diversos contextos da preservação tais como a digitalização de som, imagem e vídeo, dados de investigação, quadros normativos, sistemas de gestão de informação digitalizada ou nascida digital, divulgação e acesso, uso na investigação académica.
Imagem e montagem: Leonor Arrimar (FCT)
Painel 1: Iniciativas e realidades de preservação digital
O primeiro painel foi moderado por João Gomes, Diretor de Serviços Avançados da FCT, e trouxe para a mesa a diversidade de contextos em que se coloca a questão da preservação e do acesso. Destaca-se, aqui, um aspeto de cada apresentação e deixa-se o convite para seguir as ligações e conhecer melhor essas iniciativas.
Moisés Rockemback, Professor da Universidade de Coimbra e co-autor do livro Arquivamento da web e preservação digital, falou das primeiras iniciativas realizadas no Brasil para preservar conteúdos publicados na Web. Os websites dos candaditatos às eleições brasileiras, por exemplo, são por natureza efémeros mas tornaram-se material para a pesquisa historiográfica ao serem preservados num arquivo da Web. Numa perspetiva mais teórica abordou a questão da memória. A preservação da web permite-nos trazer à luz acontecimentos que foram veiculados unicamente em meios digitais como a Web e, nesse sentido, adia o fim da História expresso na metáfora da “Dark Age”, tempo da escuridão, vazio de informação. Slides.
Pedro Penteado, Diretor de Serviços de Arquivística e Normalização, apresentou um conjunto de instrumentos que a DGLAB tem desenvolvido, como por exemplo a Macro Estrutura Funcional (MEF), o projeto Avaliação Suprainstitucional da Informação Arquivística (ASIA) e ainda a Lista Consolidada na Plataforma CLAV, que permite às diferentes entidades da Administração Pública cumprir a legislação e normalizar práticas de classificação e avaliação. Recordou que estes intrumentos são flexíveis para atender às especificidades das organizações. Slides.
Pedro Príncipe, Chefe da Divisão de Serviços de Documentação da Universidade do Minho, abordou os dados de investigação. A preservação e o acesso aos dados é fundamental para a produção de ciência. Para isso é necessário conjugar iniciativas e trabalhar em rede e criar comunidades de prática. O Fórum GDI é um exemplo de que o encontro entre profissionais é útil. A certificação é altamente recomendável, como o tem demonstrado a Universidade do Minho que certificou o seu repositório, pois é um motivo extra para criar robustez e para atingir os objetivos FAIR (Findable, Acessible, Interoperable, and Reusable). Slides.
Hilário Lopes, Diretor adjunto das Relações Institucionais e Arquivo da RTP, descreveu o caminho para o digital que mudou completamente a forma de acesso ao Arquivo da RTP. Se até de 2001 a digitalização se fazia a pedido, a partir desse ano os conteúdos foram massivamente digitalizados. Desde 2007, os conteúdos são acessíveis em formato digital, o que facilitou o acesso e o uso. A RTP Memória e o Portal RTP são dois exemplos de acesso ao património audiovisual da rádio e televisão pública. Slides.
Painel 2: Preservar e reutilizar a informação da Web
O tema do arquivo da Web esteve em destaque no segundo painel, moderado por Daniel Gomes, Gestor do Arquivo.pt e seu iniciador em 8 de de novembro de 2007.
António Campos e Hélder Mestre, do Arquivo da Câmara Municipal de Sines, mostraram como, desde 2020, preservam conteúdos da Web de interesse local em colaboração com o Arquivo.pt. Gravam páginas Web com o ArchiveWeb.page, ferramenta do Webrecorder, enviam uma cópia dos ficheiros para o Arquivo.pt, fazem transcrição textual de imagens e vídeos, e usam também o PDF como formato mais tradicional para arquivar notícias. A questão da acessibilidade aos conteúdos para pessoas com necessidades especiais é fundamental no processo de preservação. Slides.
António Ramiro e Carmen Fonseca, vencedores do Prémio Arquivo.pt 2024, apresentaram o seu trabalho Noticioso.pt. É um projeto que reutiliza a informação do Arquivo.pt para desafiar a capacidade crítica dos cidadãos. Slides.
Para finalizar, Daniel Gomes, destacou o muito que foi feito nos últimos 17 anos no domínio da preservação da Web, a ponto de termos atualmente um serviço funcional que toda a gente pode usar. Fomos encontrar, como testemunho desses primeiros tempos, uma página do Diário Digital, de novembro de 2006.
Painel 3: Preservar a atualidade e salvaguardar o futuro
O terceiro painel foi moderado por Paula Meireles, Coordenadora do serviço Arquivo, Documentação e Informação da Fundação para a Ciência e a Tecnologia (FCT) e trouxe à mesa outras quatro realidades.
Filipe Guimarães Silva, Diretor Executivo da Fundação Mário Soares e Maria Barroso e António Coelho, Coordenador de reprodução digital, aprofundaram as questões técnicas relacionadas com a digitalização, a partir do caso do acervo, que também está acessível no portal Casa Comum. O controlo de qualidade é o fator mais importante para obter uma versão digital preservável. Nem sempre são necessárias tecnologias caras para obter bons resultados. É fundamental seguir os standards e cuidar para que sejam gerados metadados de qualidade.
Fernanda Gonçalves, Diretora do Arquivo da Unidade Local de Saúde São João, mostrou como o Repositório Clínico Digital São João está a transformar o acesso aos processos clínicos com vantagens tanto na rapidez como na qualidade da informação. O modelo de gestão da informação nesta enorme instituição traz imensos desafios para a preservação e o acesso continuado, pois trata-se criar interoperabilidade entre múltiplos sistemas. Acresce que se tratam de dados sensíveis com diferentes níveis de acesso. É aqui que surge o arquivo como uma mais valia. O serviço de arquivo deve estar à altura dos desafios em qualquer organização para servir todos os seus “clientes”.
Augusto Ribeiro, responsável pelo Serviço de Gestão da Documentação e Informação na UPdigital, Universidade do Porto, explicou como está ser feita a preservação do acervo universitário. Desde o tratamento dos documentos em papel, à sua digitalização e à inserção no repositório digital, é importante garantir a robustez. Este trabalho tem sido progressivo e sistemático, ou seja, segue um plano onde todas as peças se encaixam, à medida que o trabalho é desenvolvido.
Pedro Penteado (DGLAB) apresentou o projeto “Guía de Preservación Digital” que está a ser desenvolvido em colaboração com a Asociación Latinoamericana de Archivos (ALA). Esta iniciativa vai estruturar conteúdos sobre a preservação digital de forma pragmática. Em breve, os profissionais terão à mão uma base de conhecimento para consultar, sempre que desenvolverem atividades de preservação digital.
Painel 4: Espaço comunidade
O quarto painel, moderado por Paula Carvalho, do Arquivo de Ciência e Tecnologia da FCT, incluiu 9 apresentações breves submetidas pela comunidade. Em seguida, apresentamos os resumos enviados pelos autores:
Justiça do Futuro: + Digital – Alexandra Lourenço, Albertina Catrola, Alexandra Henriques, António Dias, Cristina Ferreira, Inês Nunes, Rute Ramos | SGMJ
Celebrando os 50 anos do 25 de Abril na sessão de encerramento
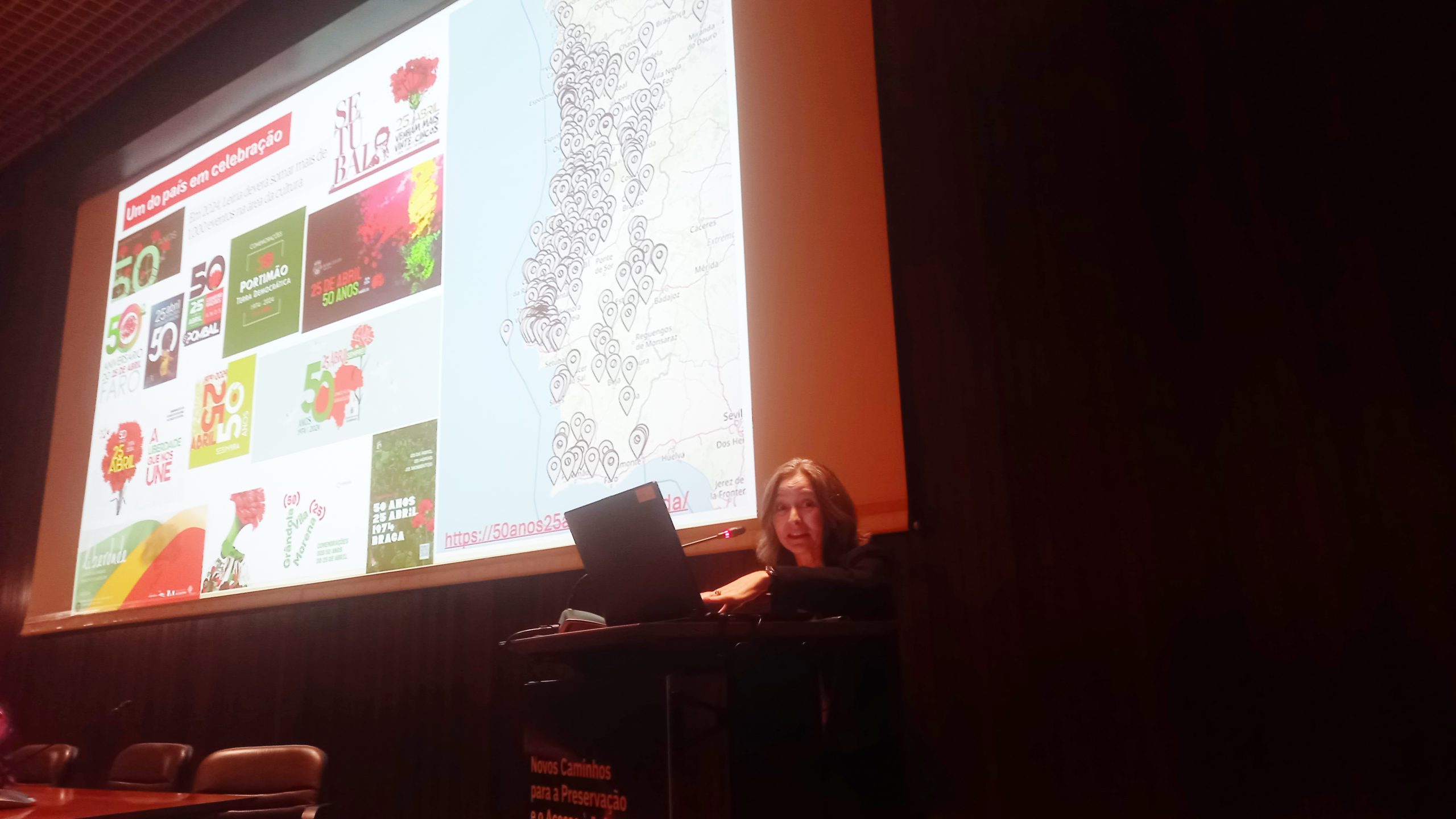
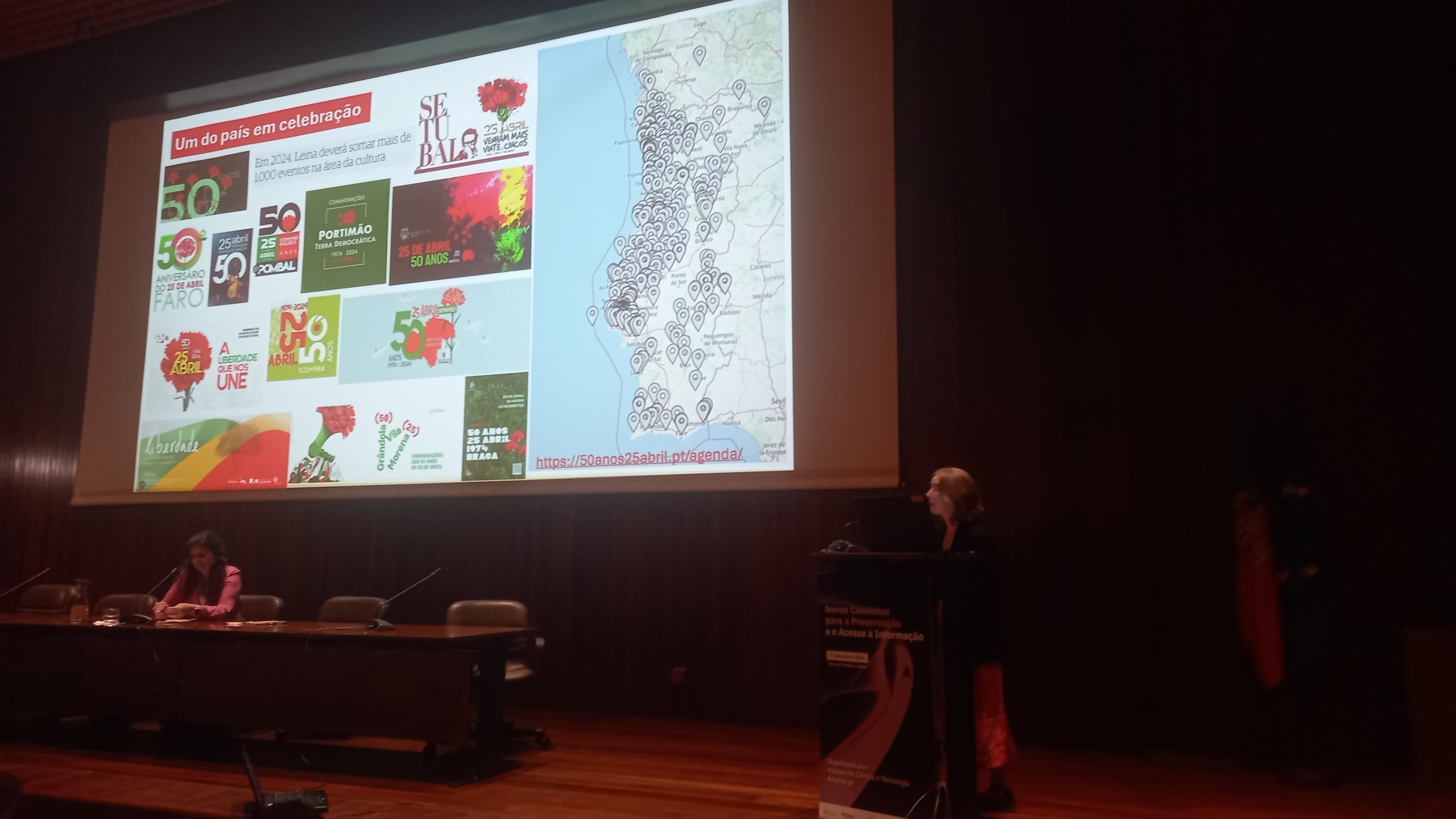
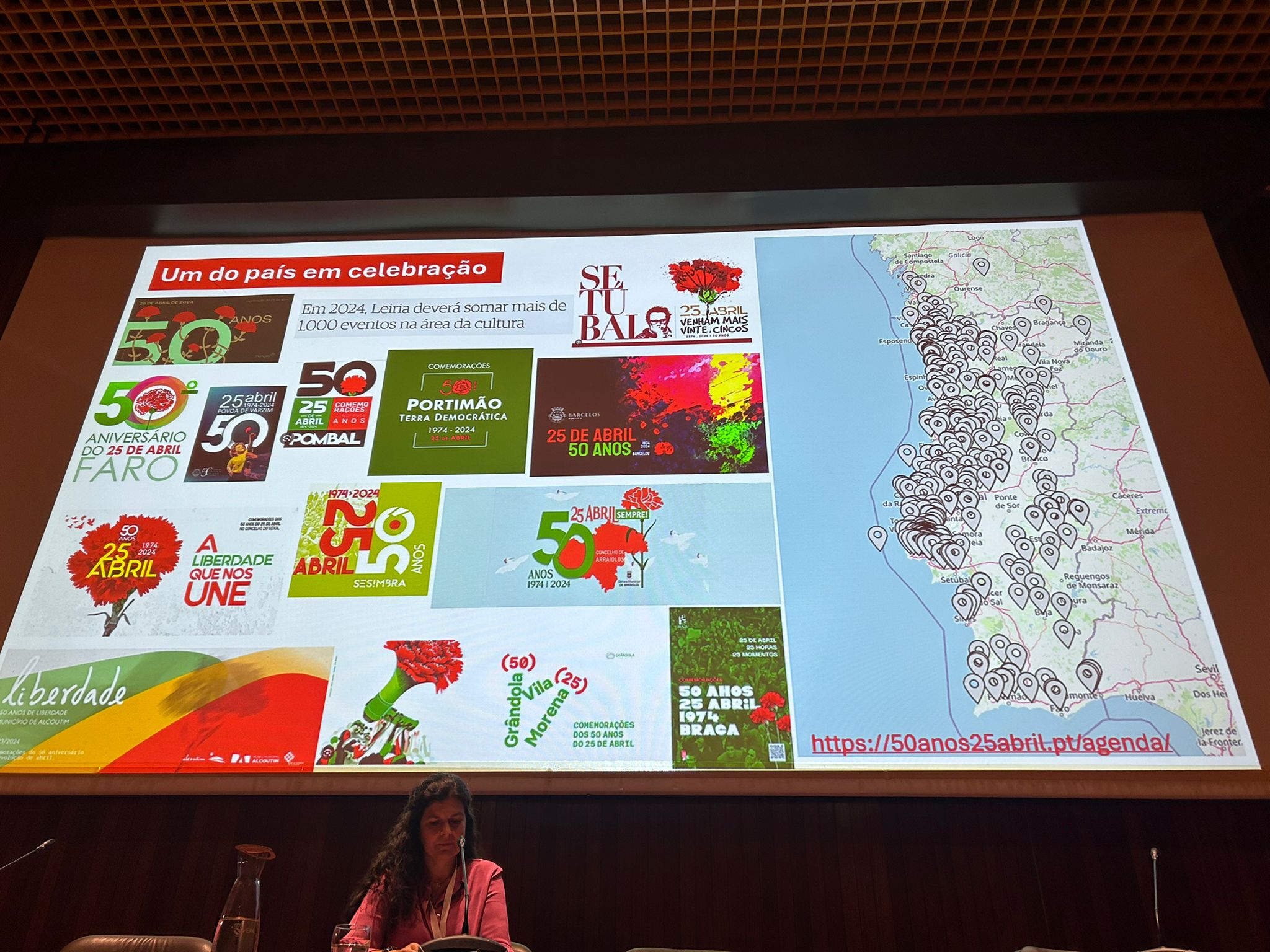
Maria Inácia Rezola, Comissária Executiva da Estrutura de Missão para as Comemorações do 50º aniversário da Revolução de 25 de Abril de 1974, apresentou uma perspetiva histórica do impacto do 25 de Abril na sociedade portuguesa, nomeadamente através da forma como este é comemorado por todo o país.
Deu a conhecer o trabalho que a Comissão Comemorativa 50 Anos 25 de Abril tem realizado para identificar arquivos, centros de documentação e acervos das mais variadas espécies com material acerca do 25 de Abril. Há acervos públicos praticamente desconhecidos, outros que se encontram-se em acervos privados. A inventariação e a divulgação é, portanto, o primeiro passo para promover o estudo e o conhecimento sobre o 25 de Abril.
Para terminar, Maria Inácia Rezola, anunciou a atribuição da Menção Honrosa “O 25 de Abril e a Democracia”, juntamente com um prémio de 5.000 euros, na edição Prémio Arquivo.pt 2025, ao melhor trabalho sobre o 25 de Abril que utilize o Arquivo.pt.
Galeria de imagens
Encontro Dia Mundial da Preservação Digital 2024 #WDPD2024
Créditos: fotografias por Leonor Arrimar (FCT). Incluídas algumas imagens de dispositivos móveis enviadas por participantes.
O Arquivo.pt arrecadou o galardão na categoria de “Melhor Projeto Digital da Administração Pública Central”.
Esta categoria reconhece, anualmente, um projeto que tenha contribuído “de forma inequívoca para o desenvolvimento do setor Público Central através do meio digital, assim como da Economia Digital em Portugal”.
O gestor do Arquivo.pt Daniel Gomes, a Coordenadora Geral Adjunta da FCCN Salomé Branco e o vice-presidente da FCT Francisco Santos estiveram presentes na cerimónia que se realizou no dia 24 de outubro no Técnico Innovation Center em Lisboa e receberam o galardão.
Arquivo.pt receives Award for Best Governmental service
Prémios Navegantes XXI
Os Prémios Navegantes XXI são uma iniciativa anual da ACEPI – Associação da Economia Digital, criada com a missão “Promover e Desenvolver a Economia Digital em Portugal”.
O concurso premia o melhor da Economia e Sociedade Digital em Portugal nas suas mais diversas vertentes. Atualmente, é composto por 20 categorias que premeiam os projetos, ideias e instituições portuguesas mais inovadoras na transformação digital. São ainda entregues 3 Prémios para Categorias Especiais extra-concurso.
Última atualização em 11 de Dezembro de 2024 às 12:16
O mês de setembro marca o início de um ano de trabalho e também o fim de muitos sites que se perdem sem remédio. Remodelados ou desligados sem se ter feito uma boa cópia dos seus conteúdos, é assim que se perdem muitos sites sem necessidade.
Há ferramentas que permitem a gravação imediata dos sites pelas próprias organizações que os gerem. Além disso, há o serviço arquivo a-pedido em alta qualidade que o Arquivo.pt presta a entidades parceiras ou no contexto de colaborações pontuais.
Neste artigo pretende-se destacar o Browsertrix Crawler que é utilizado pelo Arquivo.pt, sem excluir outras ferramentas, e que pode ser útil aos gestores de informação e departamentos de informática.
Uso do Browsertrix-crawler pelo Arquivo.pt para recolhas de alta qualidade
O Browsertrix Crawler é uma ferramenta que permite gravar websites inteiros e listas de páginas web de forma automática e num formato compatível com os arquivos da Web.
O Arquivo.pt utiliza o Browsertrix Crawler para fazer recolhas de alta qualidade de sites (RAQs), a pedido da comunidade. Por exemplo, quando um site está para ser desligado, quando vai sofrer uma remodelação ou, periodicamente, para manter um bom histórico de sites importantes.
Um caso ilustrativo é o site da Câmara Municipal de Almada, gravado em abril de 2021, a pedido do Arquivo Municipal. Outro caso é o site do jornal Notícias de Leiria que foi gravado antes do seu encerramento, em dezembro de 2023.
Os pedidos de recolha de alta qualidade (RAQs) ao Arquivo.pt são cada vez vez mais frequentes: 77 pedidos, de janeiro a setembro de 2024. É sinal de que há uma maior preocupação com a preservação dos conteúdos Web.
O que é preciso para usar locamente o Browsertrix-crawler
O grupo que o desenvolveu o Browsertrix Crawler, o Webrecorder.net liderado por Ilya Kreymer, tem como mote “web archiving for all”. As suas ferramentas permitem a gravação da Internet de forma descentralizada e em pequena escala.
O Browsertrix Crawler está disponível e pode ser instalado no próprio computador para pequenas recolhas.
A versão linha de comandos aqui recomendada é a mesma que o Arquivo.pt está a utilizar.
Pela experiência da equipa do Arquivo.pt, pode dizer-se que usar o Browsertrix Crawler é fácil em equipas multidisciplinares, onde há sempre alguém com conhecimentos mínimos para usar comandos Linux e dar algum apoio pontual.
Demonstração de gravação de sites inteiros no próprio computador
Neste vídeo apresenta-se um caso de utilização do Browsertrix Crawler num simples computador de secretária. É útil para quem quer aprofundar conhecimentos e práticas de gravação de sites em ambiente local e destina-se a não especialistas.
Outras ferramenta utilizadas pelo Arquivo.pt para gravar conteúdos
Brozzler: ferramenta para uma melhorar o histórico dos sites de recolha diária e mensal
O Brozzler é uma ferramenta semelhante ao Browsertrix Crawler, pois também baseia a sua gravação num browser. É utilizado e mantido pelo Internet Archive.
O Arquivo.pt utiliza o Brozzler, pelo menos desde 2018, para gravar páginas web com conteúdos interativos presentes nas páginas web e para recolhas de alta qualidade (RAQs).
Listas até 200 sites são gravadas com sucesso pelo Brozzler. Por exemplo, os 125 sites de recolha diária (FAWPs) são gravados com o Brozzler no início de cada mês. Ao longo do mês, outros 75 sites de recolha mensal (MAWPs) são gravados usando o Brozzler.
No final de 2023, o Arquivo.pt comparou o Brozzler e o Browsertrix Crawler e optou por manter estas duas ferramentas.
Heritrix, pywb e ArchiveWeb.page: ferramentas para milhares de sites ou para uma página
O Heritrix crawler é a principal ferramenta de gravação do Arquivo.pt. É utilizado em enormes listas de websites, como por exemplo os sites do domínio .PT a que se juntam outros sites portugueses, ultrapassando meio milhão de endereços.
Para completar a lista de ferramentas de gravação utilizadas pelo Arquivo.pt, deve referir-se o pywb que entra em ação, por exemplo, quando um utilizador do Arquivo.pt usa a funcionalidade “Completar a página” ou o serviço de gravação na hora ArchivePageNow.
Última atualização em 9 de Outubro de 2024 às 17:33
O Arquivo.pt fez recolhas especiais sobre as três eleições que se realizaram este ano: as Legislativas de 10 de março, as eleições na Madeira de 26 de maio e as Europeias de 9 de junho.
Foram identificadas mais de 70 mil páginas com conteúdos relacionados com as eleições e a vida política em Portugal e na Europa e recolhidos cerca de 4 Terabytes de informação.
Agradece-se às pessoas que contribuiram com a seleção de endereços. Desafia-se os professores e estudantes a fazerem trabalhos que utilizem as coleções especiais sobre as eleições que o Arquivo.pt tem feito ao longo dos anos.
Saiba mais detalhes sobre o procedimento da recolha e sobre os resultados obtidos.
Eleições Legislativas 2024
As Eleições Legislativas tiveram lugar no dia 10 de março de 2024 para eleger os membros da Assembleia da República para a 16.ª Legislatura da Terceira República Portuguesa.
Destacamos nesta recolha o contributo da comunidade com uma seleção manual de 827 páginas, o que contribuiu para melhorar a qualidade da coleção.
Utilizou-se cerca de 500 termos compostos ou palavras-chave para procurar conteúdos publicados na Web acerca das eleições. O serviço utilizado para pesquisa automática foi o Bing Search API. Os resultados foram limitados ao top 20.
Por exemplo, o termo composto “frente-a-frente legislativas 2024″ encontrou páginas relativas aos debates entre candidatos. O termo “habitação legislativas 2024″ obteve páginas relativas às propostas partidárias para a habitação. O termo “legislativas 2024 site:expresso.pt” identificou páginas do Expresso sobre as eleições. Foram utilizados também os nomes dos candidatos.
Após as eleições foram usados termos de pesquisa próprios para esse período, tais como “vitória legislativas 2024”, “derrota legislativas 2024” ou “resultados legislativas 2024”, entre outros.
A pesquisa automática no Bing Search API resultou em 34.120 endereços obtidos antes das eleições e em 5.803 após as eleições.
Os sites dos partidos políticos, incluindo os partidos sem assento parlamentar, também foram recolhidos durante o período eleitoral.
Nem todos os conteúdos identificados puderam ser efetivamente gravados, devido às limitações das ferramentas de gravação e às restrições dos próprios sites.
A gravação realizou-se entre 6 e 20 de março e resultou em 3.2 Terabytes de informação. Os conteúdos foram incluídos na coleção espeacial EAWP45 e estarão disponíveis passado 1 ano.
Começou-se por fazer uma pesquisa automática por notícias, páginas eleitorais e websites relacionados com as eleições na Madeira. Utilizou-se uma lista termos de pesquisa para colocar no Bing Search API.
Pretendeu-se obter o maior número possível endereços de páginas (URLs) relacionados com o evento ou tema em causa, ou seja, as eleições madeirenses. Para isso definiu-se vários limites para os resultados: top 10, top 20, top 50 e top 100. Deixou-se documentado esse processo, o qual mostra que quanto mais alargamos o número de resultados maior é o número de páginas pouco relevantes e por vezes fora do alvo pretendido.
A totalidade dos endereços (12.656) foi colocada a gravar no dia 7 de junho no Heritrix crawler.
Collection ID: EAWP46 (onde se encontram os conteúdos gravados, disponível passado 1 ano)
Eleições Europeias 2024 em recolha multilingue
As Eleições Europeias realizaram-se a 9 de junho em Portugal. Em alguns países, como por exemplo, a Estónia, a Chéquia ou a Itália as eleições foram em outras datas.
O Arquivo.pt recolheu páginas relativas às Eleições Europeias nos 27 países da União Europeia e nas 24 línguas oficiais.
Utilizou-se uma lista de 40 termos compostos que foram traduzidos para as 24 línguas oficiais da UE. A tradução dos termos para as diversas línguas foi feita em 2019 pelo pelo EU Publications Office. Dessa colaboração resultou uma lista multilingue com 960 de termos para colocar no Bing Search API.
Antes das eleições, a 3 de junho, foi realizada a primeira pesquisa da qual resultaram 8.986 endereços únicos, com o número de resultado limitado ao top 20.
Depois das eleições, adicionou-se novos termos de pesquisa com os nomes dos principais candidadatos ao Parlamento Europeu em cada país da União Europeia. Desta segunda pesquisa pós-eleitoral foram obtidos 15.371 endereços únicos.
A ferramenta utilizada para esta recolha foi o Heritrix. A recolha foi limitada a três “saltos” (“hops”). O crawler seguiu ligações, neste caso, até três vezes. Quer isto dizer que se optou por uma certa contenção na profundidade da gravação. Três “saltos” ou “hops” no Heritrix crawler é o suficiente para a recolha de uma página (em outras aplicações também denominada por gravação “page” ou “single page”).
Os conteúdos foram gravados entre 7 e 20 de junho e incluídos na recolha especial EAWP46. Estará disponível passado 1 ano.
O Arquivo.pt contribuiu para a coleção internacional de páginas Web sobre os Jogos Olímpicos, que decorreram em Paris de 26 de julho a 11 de agosto de 2024, e os Jogos Paralímpicos que se realizaram de 28 de agosto a 8 de setembro.
No Arquivo.pt também ficarão disponíveis, passado um ano, as páginas desta coleção para quem quiser realizar estudos sobre desporto e olimpismo.
Como foram selecionadas as páginas sobre os atletas portugueses
Nos Jogos Olímpícos representaram Portugal 73 atletas em 15 modalidades, e nos Jogos Paralímpicos 27 atletas, em 10 modalidades.
O critério de seleção de páginas para a coleção internacional foram notícias sobre os atletas. Para cada atleta selecionou-se páginas referentes às suas expectativas antes dos jogos, à sua prestação na prova e aos seus comentários durante e após a competição.
Há atletas que têm mais notícias selecionadas do que outros e o mesmo acontece com os sites de onde provêm as notícias. A seleção de páginas não se limitou aos primeiros resultados apresentados pelo motor de busca. Procurou-se variedade de canais e notícias de sites regionais e locais, alguns da região ou cidade de onde vieram os atletas.
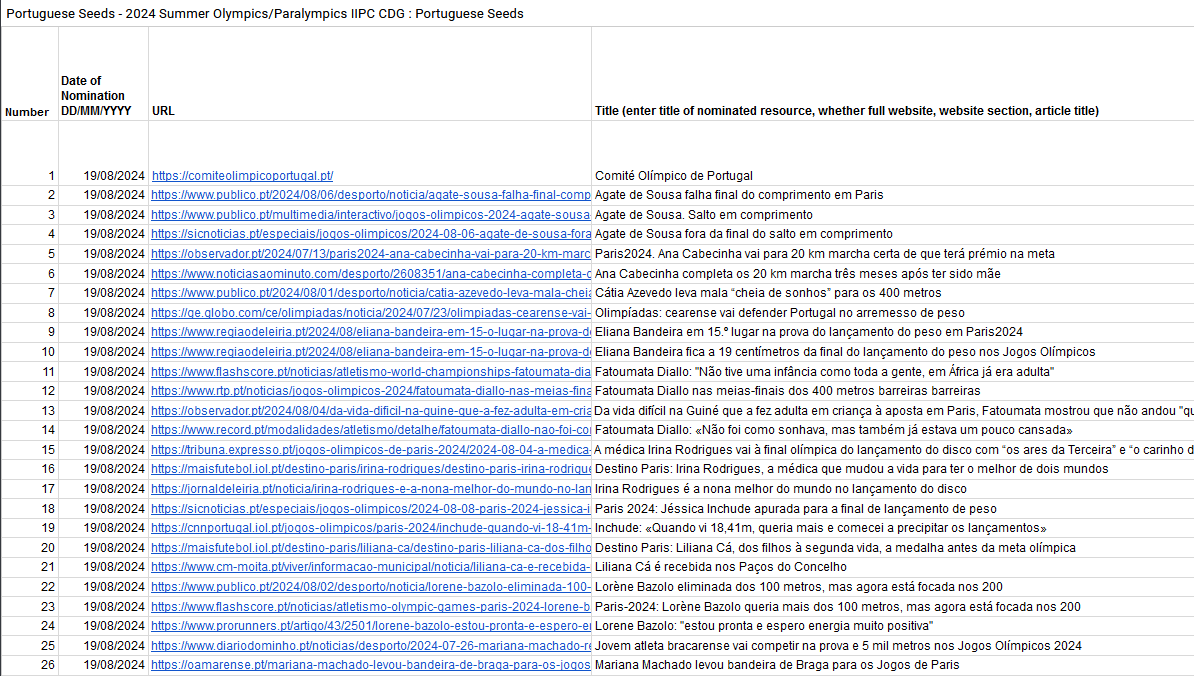
Mais de 500 páginas para recordar a presença portuguesa em Paris
O contributo do Arquivo.pt, como poderá ver na tabela, já tem mais de 500 paginas Web.
O Instituto Politécnico de Lisboa (IPL), através do Grupo de Ensino à Distância (EaD@IPL), promoveu um ciclo de webinars para a sua comunidade dedicado ao Arquivo.pt e à preservação dos conteúdos publicados na Internet.
Esta iniciativa teve a participação de docentes e investigadores do IPL, bem como pessoas ligadas à comunicação da mesma instituição.
O ciclo de webinars realizou-se em três sessões, entre maio e julho de 2024, e seguiu o programa de formação que o Arquivo.pt disponibiliza há vários anos.
Materiais das apresentações
1º webinar – Arquivo.pt: uma nova ferramenta para pesquisar o passado. Bem publicar, para bem preservar. 5 de junho.
Porque é importante fazer ações de formação acerca da preservação da Web
Arquivar conteúdos publicados na web e usar um arquivo da Web no dia-a-dia é uma prática pouco habitual, em grande parte devido ao desconhecimento por parte da comunidade da existência e do funcionamento do Arquivo.pt.
As sessões de formação do Arquivo.pt são um espaço de motivação para que as pessoas e as instituições passem a cuidar melhor dos seus websites e dos conteúdos que publicam na Web.
Como resultado deste ciclo de webinars reforçou-se a colaboração entre o Instituto Politécnico de Lisboa e o Arquivo.pt, tendo em vista a preservação dos seus sítios web institucionais e de outros conteúdos de interesse que estão em diversos meios on-line (notícias, eventos, referências a docentes investigadores e alunos).
O vencedor do prémio no valor de 10 000 euros foi o trabalho “Noticioso – Desafiar percepções” desenvolvido por Carmen Fonseca e António Ramiro (Equipa Cubbo).
“Noticioso” é uma plataforma em que o utilizador pode comparar a cobertura mediática sobre diversos temas através de um jogo (Quiz). Permite ainda explorar tendências ao longo do tempo através de uma ferramenta analítica. Acha que conhece bem as notícias portuguesas? Venha descobrir.
Por exemplo, qual o tópico com mais notícias entre 2000 e 2020: Aquecimento global ou Sporting? Os dados do Arquivo.pt dizem que foi o Sporting.
2º classificado – “Habitação.NET: Uma visão do Mercado de Habitação em Portugal”
O 2º prémio no valor de 3 000 euros foi atribuído ao trabalho “Habitação.NET: Uma visão do Mercado de Habitação em Portugal”, da autoria de Diogo Gonçalves.
“Habitação.NET: Uma visão do Mercado de Habitação em Portugal” é uma ferramenta que permite ao utilizador explorar, de forma interativa, a evolução do valor médio do mercado habitacional e arrendatário português, contextualizado com notícias publicadas sobre o tema e as políticas de habitação.
Por exemplo, no ano 2009, em Lisboa o preço é cerca de 1600 €/m2, tendo subido para 4800 €/m2 em 2023. A subida de preços na habitação é contextualizados por notícias ao longo do tempo.
O 3º classificado recebeu um prémio no valor de 2 000 euros e foi atribuído ao trabalho “Pegada Lusa”, desenvolvido por Diana Costa e Sérgio Teixeira.
“Pegada Lusa” é um trabalho que mostra a evolução das políticas e iniciativas sustentáveis nas diversas regiões do país, a partir da análise dos projetos e boas práticas dos Objetivos de Desenvolvimento Sustentável (ODS).
Por exemplo, a região do Porto tem um índice de sustentabilidade (“Green Score”) de 57%, baseado no teor das notícias analisadas.
Menção Honrosa do Público: “Uma viagem no tempo com o Público e o Expresso”
O jornal Público, parceiro oficial da 7ª edição do Prémio Arquivo.pt, atribuiu a sua Menção Honrosa ao trabalho “Uma viagem no tempo com o Público e o Expresso“, realizado por Rita Marques Costa e Beatriz Malveiro.
“Uma viagem no tempo com o Público e o Expresso” analisa e compara as páginas web do Público e o Expresso, desde 1998, mostrando ao utilizador do website como evoluíram as versões digitais destes meios.
Por exemplo, em 2014, tanto o Público como o Expresso passam a dar maior destaque às manchetes nas suas homepages e o Expresso passa a ter edição digital diária.
Menção Honrosa AMCC – Aveiro Media Competence Center: “discordAR: a Proximidade dos Partidos na Assembleia da República”
O Aveiro Media Competence Center (AMCC), atribuiu a sua Menção Honrosa ao trabalho “discordAR: a Proximidade dos Partidos na Assembleia da República”, realizado por Miguel Salema e Sebastião Fonte.
“discordAR: a Proximidade dos Partidos na Assembleia da República” é uma App que mostra a proximidade entre partidos políticos, usando votos na Assembleia da República Portuguesa.
Por exemplo, podemos ver a percentagem de votos na mesma direção entre os Partidos no período relativo à XII Legislatura (2012 a 2015).
Menção Honrosa .PT: “ArquivoNC – arquivo web do Jornal de Notícias da Covilhã”
A Associação DNS.PT atribuiu uma Menção Honrosa ao Professor que incentivou a submissão do trabalho “ArquivoNC – o arquivo web do Jornal de Notícias da Covilhã”, promovendo assim a utilização do Arquivo.pt como ferramenta de treino e aprendizagem em contexto de aula. A autoria do trabalho é do aluno Rodrigo Dias da Silva, orientado pelo Professor Ricardo Campos, da Universidade da Beira Interior (UBI).
“ArquivoNC – o arquivo web do Jornal de Notícias da Covilhã” é um trabalho no âmbito do projeto de final de curso em Engenharia da Universidade da Beira Interior (UBI) que disponibiliza o acesso a dez anos de páginas web do jornal Notícias da Covilhã a partir das notícias preservadas pelo Arquivo.pt entre 2009 e 2019.









































































































































































{kind=link}
{kind=link}