O Arquivo.pt esteve presente na 6a Conferência RESAW para investigadores das Humanidades Digitais, Media e Comunicação e outras áreas, subordinado ao tema “The Datafied Web”, que teve lugar na Universidade de Siegen, Alemanha, de 4 a 6 de junho de 2025.
RESAW (Research Infrastructure for the Study of Archived Web Materials) é uma iniciativa informal que reúne investigadores que utilizam arquivos da Web na sua investigação. A primeira conferência do RESAW foi em 2015, passando a realizar-se a cada dois anos.
Inicialmente, o RESAW reunia investigadores europeus, mas agora congrega investigadores de todo o mundo, tendo-se tornado num fórum único no seu género. Em 2025, contou com mais de 100 participantes. Ali se encontra o que de melhor se faz no domínio utilização de arquivos da Web em contexto de investigação.
Niels Brügger, Professor de Media e Comunicação da Universidade de Aahrus, Dinamarca, tem sido o principal impulsionador do RESAW, ao longo de 10 anos.
Destacam-se ainda nomes de investigadores de referência com estudos desenvolvidos no âmbito dos arquivos da Web: : Valerie Schafer, da Universidade do Luxumburgo, Jane Winters, da Universidade de Londres, Anne Helmond, da Universidade de Utrecht, Susan Aasman da Universidade de Groningen, Sophie Gebeil, da Universidade de Aix-Marseille e Ian Millingan da Universidade de Waterloo.
O tema deste ano The Datafied Web abordou a questão da datificação da Web, desde os seus inícios na década de 1990 à atualidade, marcada pelo processamento massivo de dados e pelo uso da Inteligência Artificial.
Porquê a participação de um arquivo da Web num encontro de cariz académico?
O Arquivo.pt participa regulamente no RESAW desde 2019, pois quer dar-se a conhecer cada vez mais como um serviço destinado aos investigadores nacionais e internacionais.
Graças à participação em eventos internacionais como o RESAW, surgiram várias publicações que usam e referem o Arquivo.pt. Qualquer investigador com acesso à Internet pode pesquisar a informação preservada no Arquivo.pt, usar as APIs, processar informação ou treinar os seus modelos.
Convidamos os investigadores portugueses a participarem neste encontro, pois temos sido a única presença portuguesa em várias edições. Temos um arquivo da Web acessível, pronto a utilizar, o que não acontece em outros países. Gostaríamos de ter investigadores de áreas das Humanidades Digitais e Media e Comunicação em Portugal a usarem mais frequentemente o Arquivo.pt e a participarem ativamente em encontros como o RESAW.
Contributo do Arquivo.pt no RESAW 2025
O Arquivo.pt contribuiu com duas apresentações na edição de 2025 de encontro RESAW, realizado na Universidade de Siegen. A primeira acerca das APIs do Arquivo.pt e da sua aplicação em contexto de investigação, por Vasco Rato. A segunda sobre os conjuntos de dados abertos e listas de sites sobre temas e eventos que o Arquivo.pt preparou para ajudar os investigadores a iniciarem uma exploração mais profunda da informação arquivada.
- Bulk access to web-archived data using APIs – Daniel Gomes e Vasco Rato
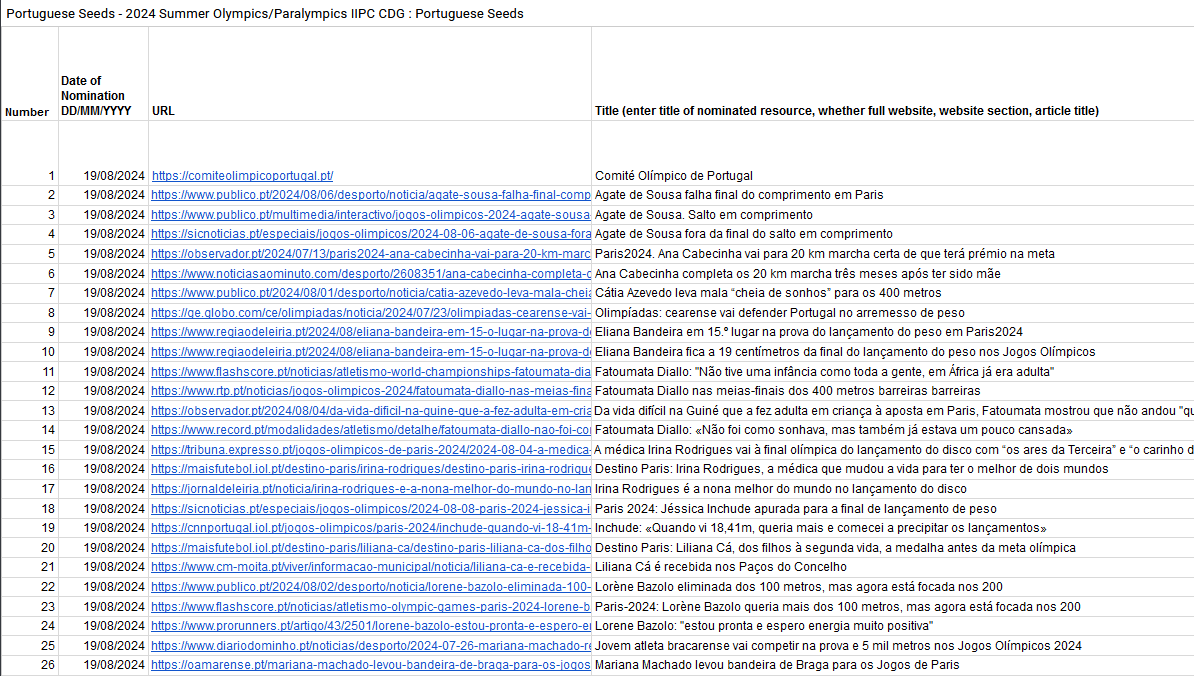
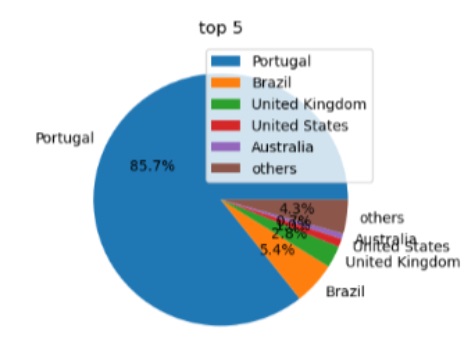
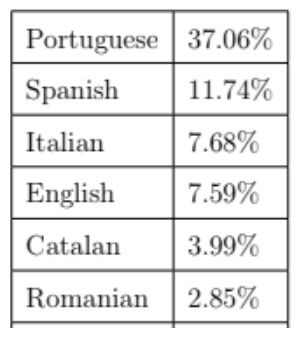
- Seed lists on themes and events on Arquivo.pt: a curious starting point for discovering a web archive – Ricardo Basílio
Galeria de imagens
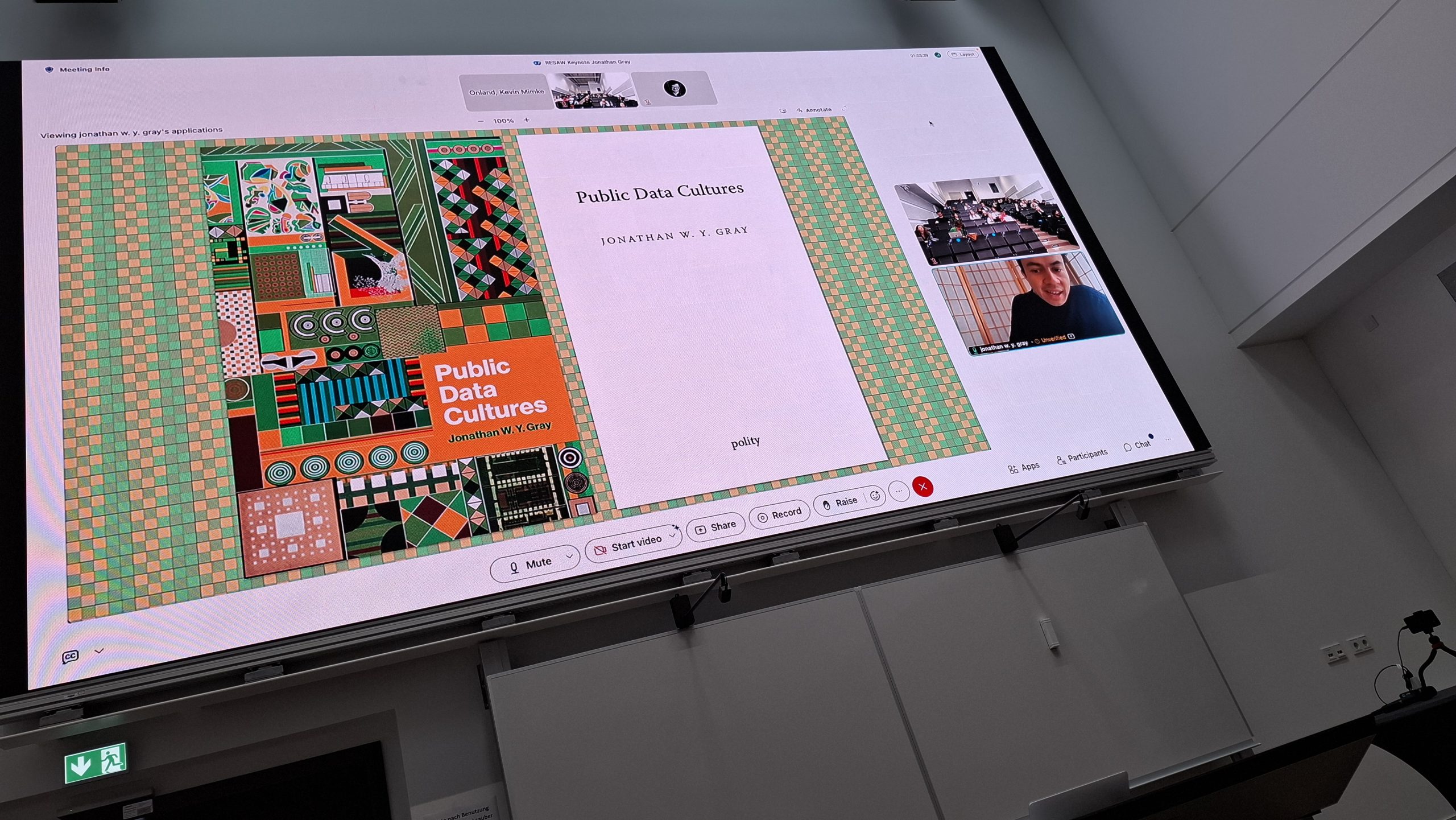
RESAW 2025 na Universidade de Siegen








































.")