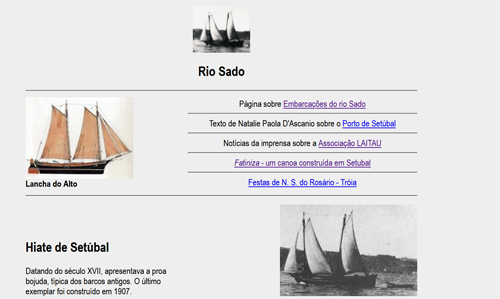
Última atualização em 22 de Maio de 2025 às 18:45
O Arquivo.pt participou no workshop intitulado “Preservação digital: ferramentas e práticas”, promovido pela Faculdade de Letras da Universidade de Coimbra, na tarde do dia 7 de maio de 2025. Com a moderação de Inês Santos, destacamos o painel inicial com excelentes intervenções de Moisés Rockembach (Universidade de Coimbra), Humberto Innarelli (Unicamp) e Daniel Gomes (Arquivo.pt, serviço digital da FCCN-FCT).
O encontro teve por objetivo oferecer à comunidade uma reflexão crítica acerca das novas tendências nas ferramentas e nas práticas de preservação digital.
A preservação digital é um tema transversal às organizações, pois todas produzem e geram informação em suporte digital. É cada vez maior a oferta de ferramentas, soluções que prometem maior eficiência no processamento de informação. Muitas são colocadas sob a designação de Inteligência Artificial. Tal abundância de produtos e enquadramentos exige uma maior discussão e abordagem crítica. E isso foi alcançado de forma brilhante pelo painel de oradores.
Três abordagens sobre Inteligência Artificial e Preservação Digital
Este encontro reuniu no Anfiteatro III da Faculdade de Letras da Universidade de Coimbra três autores de obras sobre preservação digital e trouxe à discussão abordagens diferentes.
Moisés Rockembach, co-autor com Caterina Pavão de Arquivamento da Web e preservação digital, a primeira obra em português sobre arquivos da Web, centrou a sua apresentação no impacto da Inteligência Artificial nos sistemas de preservação digital, nomeadamente na pesquisa e no acesso à informação, em processos de classificação indexação, por exemplo. A esse propósito do impacto das novas ferramentas que a tecnologia digital nos oferece, fez referência a uma frase de Demi Gretscko: “O processo de busca e captura da informação descrito no texto certamente poderá sofrer aportes futuros, especialmente ao se considerar o aporte de ferramentas novas, como as da Inteligência Artificial”.
Há ferramentas de Inteligência Artificial que permitem um acesso interessante à informação pela novidade e pelo formato. A arquivística deve ter em conta essa realidade e testar até que ponto isso pode transformar o modo como se opera a divulgação e o acesso a muitos conteúdos. Um exemplo para ilustrar esta ideia, foi a apresentação de um Podcast gerado por Inteligência Artificial, baseado no capítulo 2 do livro sobre Arquivos da Web, que versa sobre as políticas de preservação digital.
Humberto Innarelli, autor de Criptex da preservação digital, autor de Criptex da preservação digital, coordenador do Arquivo Edgard Leuenroth (AEL) e investigador especialista em arquivística na Unicamp, São Paulo e professor Doutor do Centro Paula Souza, São Paulo, colocou a questão do futuro da preservação digital. Até agora, a prática para preservar conteúdos digitais dinâmicos é convertê-los em documentos estáticos. Por outro lado, cada vez a informação é-nos dada de forma dinâmica, a partir de bases de dados ou de algoritmos e Inteligência Artificial. Qual é o próximo passo? A prática arquivística tem de olhar não apenas para os metadados (metadata), como tem feito nos últimos anos, mas também para aquilo que explica como a informação foi gerada (o que podemos chamar paradata). Só assim é possível colocar a arquivística e a preservação digital na perspetiva do longo termo. Daqui a cem ou duzentos anos deveríamos ser capazes de continuar a aceder à informação digital produzida atualmente.
Daniel Gomes, editor principal do livro The Past Web, fundador do Arquivo.pt, discutiu a questão da Inteligência Artificial na sua relação com os conteúdos de produção não artificial e humana. Que valor acrescentado trazem as ferramentas geradoras de texto, imagem, áudio ou vídeo? Se considerarmos por exemplo que um Podcast sobre preservação digital utilizou como base um livro escrito por um autor humano, que conhecimento novo gerou? Pouco ou nenhum. Assim, o que se convencionou chamar Inteligência Artificial pode considerar-se como uma forma de apresentar o conhecimento humano e de modo nenhum dispensa a humanidade de continuar a pensar, a investigar e a produzir novo conhecimento.
O Arquivo.pt preserva conteúdos que foram publicados por pessoas e organizações e nesse sentido é uma fonte única no seu género. A informação publicada na Web é importante para relatar e compreender melhor a história recente, desde a década de 1990. Qualquer ferramenta de Inteligência Artificial terá de voltar ao ponto onde a informação foi criada por pessoas. A origem humana dos conteúdos preservados pelo Arquivo.pt, e o mesmo se pode dizer dos arquivos tradicionais, faz com que estes tenham um enorme valor, até considerando-o do ponto de vista do valor económico. Quanto vale a informação preservada por um arquivo da Web?
Estreia do MOOC ou curso online do Arquivo.pt
Daniel Gomes, Gestor do Arquivo.pt anunciou em primeira mão o curso online na plataforma NAU: A Web do passado: preservação e pesquisa.
O curso online ou MOOC (Massivo Online Open Course) está disponível para quem pretende aprofundar os seus conhecimentos sobre preservação da Web.
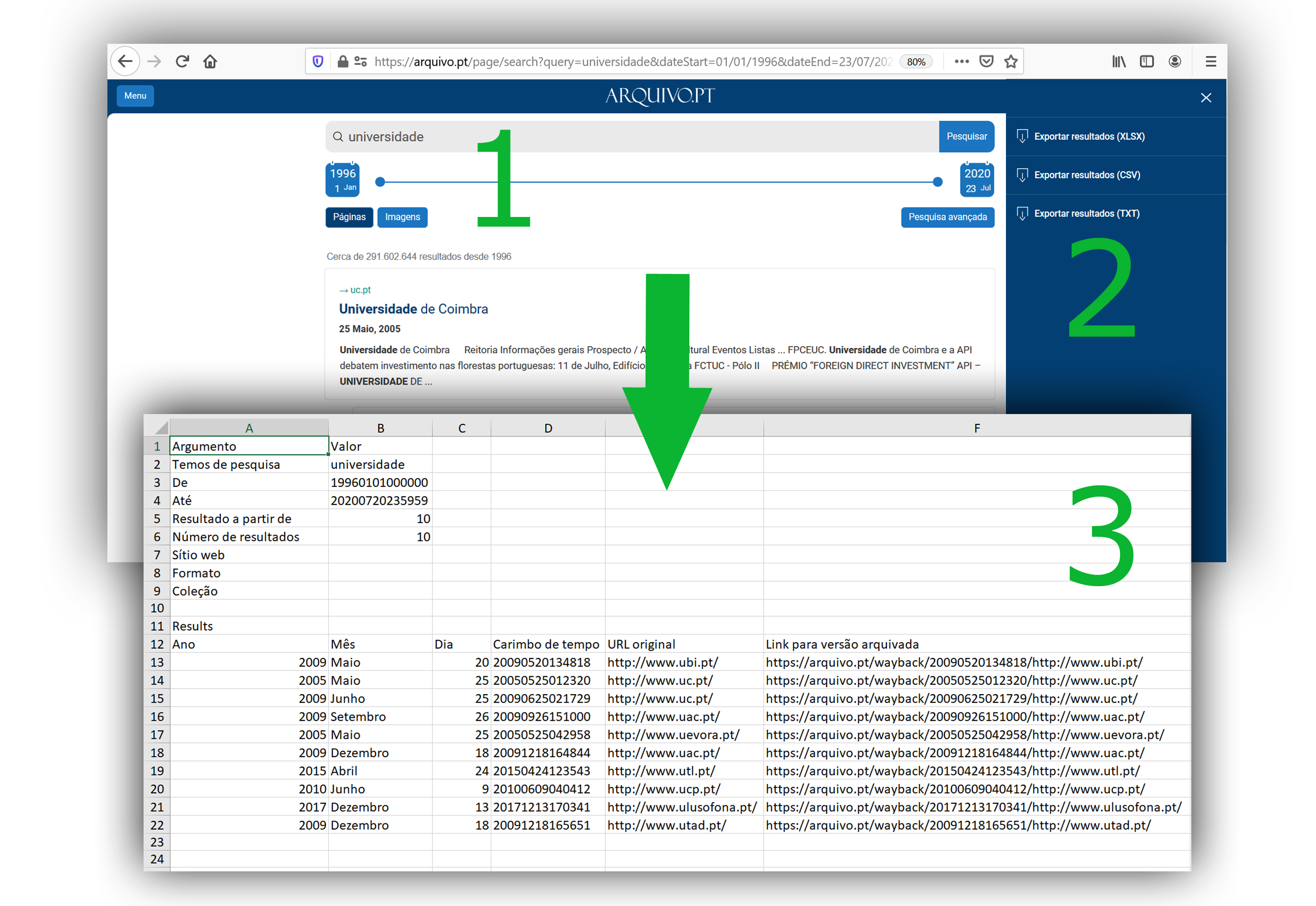
O link curto para divulgação é arquivo.pt/mooc
Os dados preservados do Arquivo.pt e o seu processamento automático por APIs
Vasco Rato, desenvolvedor do Arquivo.pt, mostrou como funcionam as interfaces de processamento automático, Application Programming Interfaces (APIs).
Os dados do Arquivo.pt podem ser processados por Inteligência Artificial. Os trabalhos concorrentes ao Prémio Arquivo.pt já o demonstraram, assim como alguns projetos como o GlórIA, um Large Language Model, desenvolvido na NOVA-FCT.
Para terminar, Ricardo Basílio, curador digital do Arquivo.pt, mostrou como qualquer pessoa pode gravar uma página ou um website inteiro no seu próprio computador num formato normalizado, compatível com os arquivos da Web. Usou-se para isso o ArchiveWeb.page e browsertrix-crawler como ferramentas de treino e formação. Esta prática permite que a comunidade seja cada vez mais ativa na preservação de informação institucional publicada na Web.
Agenda do evento
14h30 Painel – Moderadora: Inês Santos, Universidade de Coimbra
- Preservação digital e Inteligência Artificial – Moisés Rockembach, Universidade de Coimbra – Slides
- Cryptex da Preservação Digital: O próximo passo – Humberto Innarelli, Unicamp – Slides
- Arquivo.pt e a preservação da Web – Daniel Gomes, FCCN-FCT – Slides
16h00 Intervalo
- Dados Abertos para a Investigação. Processamento automático de informação através de APIs – Vasco Rato, FCCN-FCT – Slides
- Demo – Arquivar a Web: faça-você-mesmo – Ricardo Basílio, FCCN-FCT – Slides
17h00 – Final
Galeria de imagens
Imagens nos canais da Faculdade de Letras da Universidade de Coimbra
Vídeo com momentos do evento (publicado no Facebook)
Workshop na Faculdade de Letras da Universidade de Coimbra


















































.")