The collection of 1 PetaByte of content predominantly in Portuguese, accessible to both researchers and ordinary citizens, is a milestone that deserves to be celebrated, in the month of its 16th anniversary.
At Arquivo.pt you can search for information published on the Web in the past, such as:
Discover more pages through the selected pages in the Arquivo.pt Online Exhibitions.
Purpose and mission of the Portuguese Web Archive
Arquivo.pt was created on November 8, 2007 with the aim of preserving content from the Portuguese Web.
In 2013, as a service operated by the Fundação para a Ciência e a Tecnologia (FCT), its mission was formulated as follows: “To promote the preservation of content available on the national Internet, ensuring that it is made available to the scientific community and the general public” (Decreto-Lei no. 55/2013).
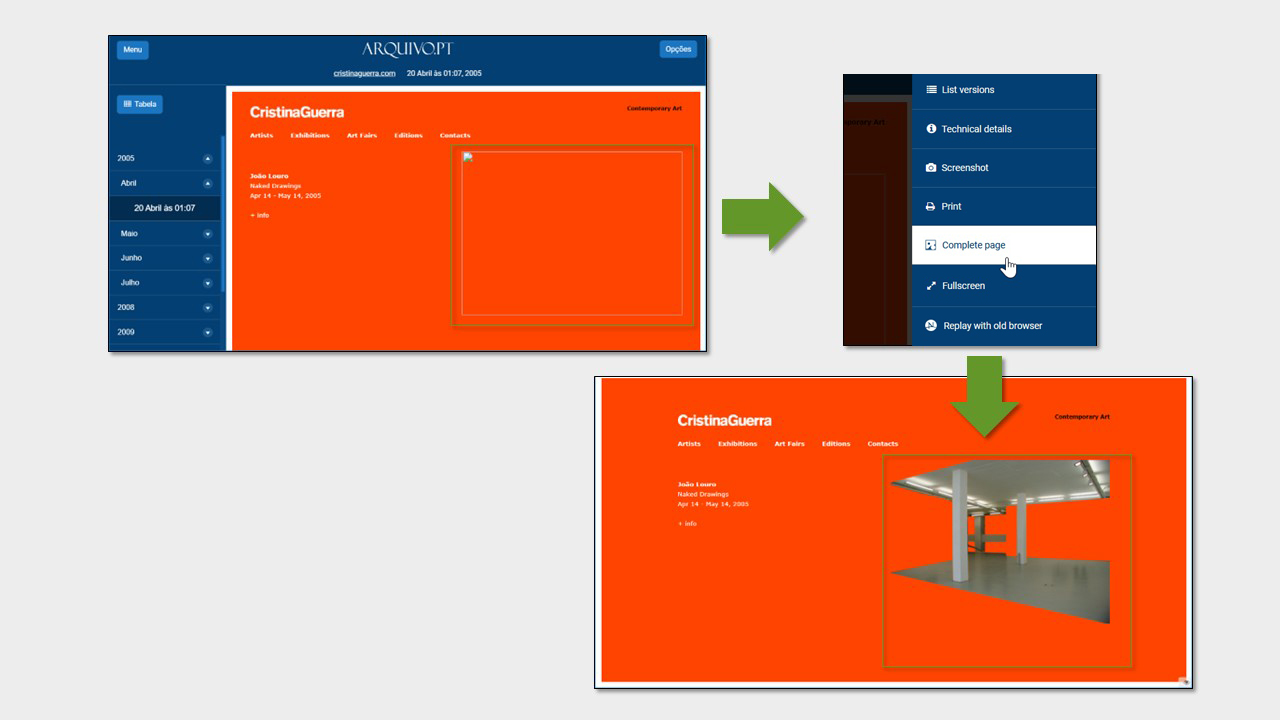
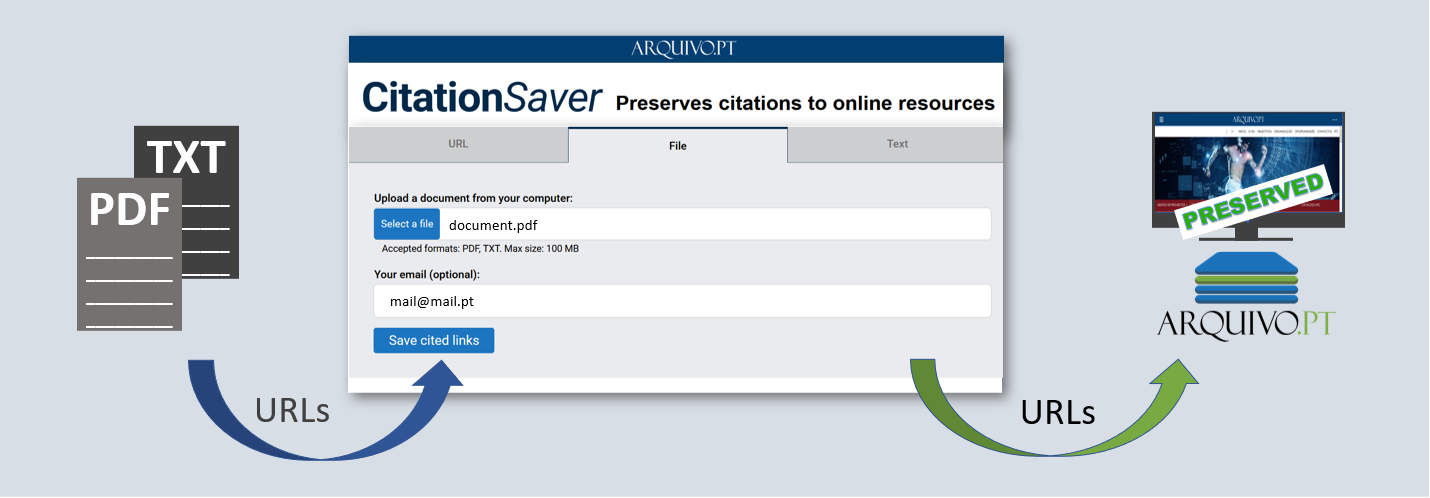
In recent years, Arquivo.pt has created new services, such as CitationSaver, which allows researchers to record references to web content in their scientific articles, Memorial and Complete page, which facilitate access to content scattered throughout the huge 1 PetaByte block of data.
Where did so much information come from?
In order to reach the 1 PetaByte volume, Arquivo.pt periodically recorded content from websites in the .PT domain and from Portuguese websites in other domains.
In addition, frequent daily and monthly collections were made from a small number of government sites and the main news sites in Portugal.
As part of international collaborations, content was collected from sites in various languages, for example on the 2019 European Elections.
Content prior to 2008 came from the Internet Archive and donations, such as a collection made by the National Library and INESC on the 2005 Legislative Elections.
The largest Portuguese-language dataset available to researchers
By making 1 PetaByte of information available, in open access and through the use of APIs (Application Programming Interfaces), Arquivo.pt is a useful tool for research.
For example, a researcher who wants to do a study on elections in Portugal can use the entire Arquivo.pt collection. Better still, they can focus on just a few special collections dedicated to the elections, choosing the ones that interest them and downloading just a few Terabytes to process automatically with the APIs.
Contributions from the various teams and friends of Arquivo.pt
The development of Arquivo.pt is more than a technological issue and has been due to the dedication and persistence of the various teams that have worked on it since 2007.
It was also due to the contribution of many friends of Arquivo.pt, who were always on hand to help improve, and to the response of the user community.
Congratulations to all! Thank you.