Last updated on August 5th, 2024 at 05:03 pm
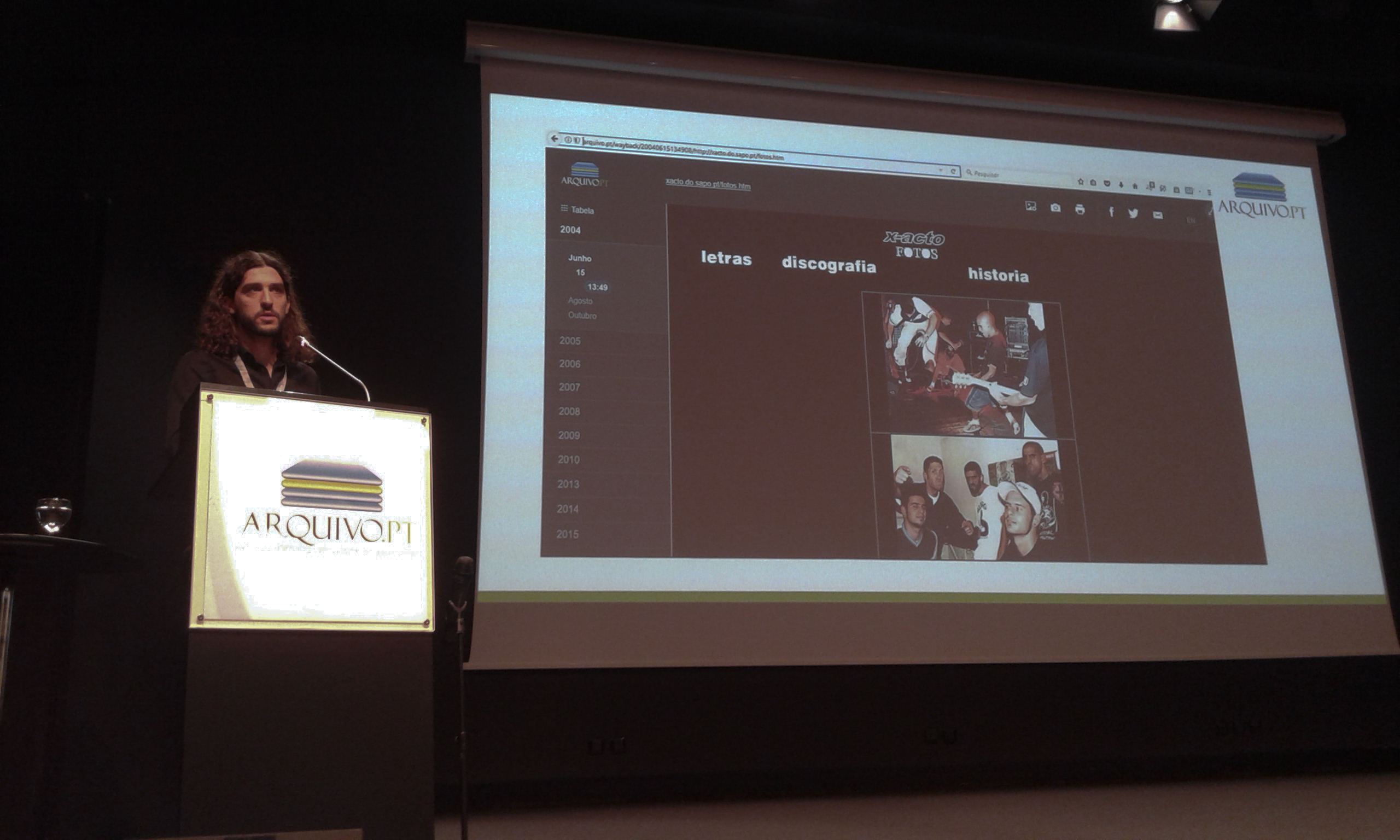
RESAW@Porto2018 workshop
An introduction to web archives for Humanities and Social Science research.
This one-day workshop will be held as part of TPDL 2018 on 13 September 2018, Porto, Portugal.
RESAW is a network of researchers and web archivists that promotes the development of Research infrastructures for the Study of Archived Web Material.
The organizing committee is composed by Jane Winters (Professor of Digital Humanities at the University of London) and Daniel Gomes (Arquivo.pt).
Call for Proposals
We are seeking proposals from potential contributors to the workshop in two main areas:
- Work presenting the state of the field and discussing the opportunities and challenges of using this new kind of primary source for research. This may include demonstrations of existing web archives.
- Presentations of ground-breaking Humanities and Social Science research drawing on web archives, from small-scale analyses of individual websites to large-scale investigations of entire domains.
Apply
To apply, just submit a 300-500 word abstract via our online form. Final presentations should be around 30 minutes in length.
Deadline for applications: 15 June 2018, 17.00 (GMT+1).
All details at: http://arquivo.pt/resawPorto2018
Spread the word!
Please disseminate among potentially interested authors and attendees.
Thanks!
Jane Winters & Daniel Gomes