O Arquivo.pt contribuiu para a coleção internacional de páginas Web sobre os Jogos Olímpicos, que decorreram em Paris de 26 de julho a 11 de agosto de 2024, e os Jogos Paralímpicos que se realizaram de 28 de agosto a 8 de setembro.
No Arquivo.pt também ficarão disponíveis, passado um ano, as páginas desta coleção para quem quiser realizar estudos sobre desporto e olimpismo.
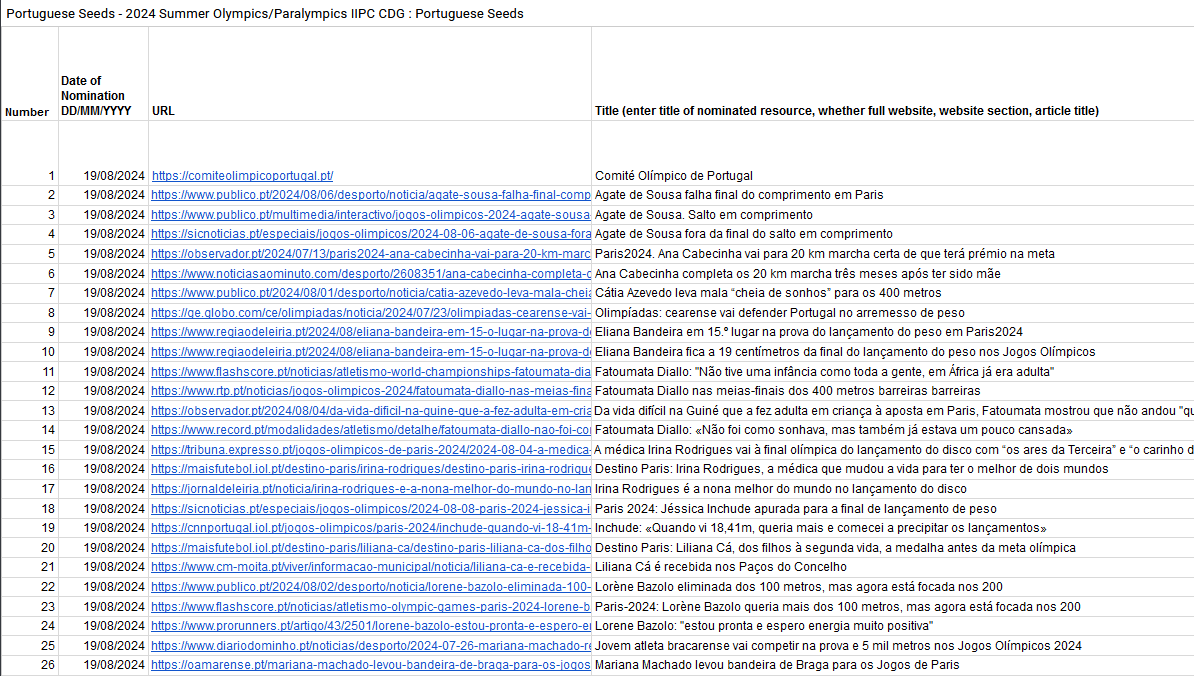
Como foram selecionadas as páginas sobre os atletas portugueses
Nos Jogos Olímpícos representaram Portugal 73 atletas em 15 modalidades, e nos Jogos Paralímpicos 27 atletas, em 10 modalidades.
O critério de seleção de páginas para a coleção internacional foram notícias sobre os atletas. Para cada atleta selecionou-se páginas referentes às suas expectativas antes dos jogos, à sua prestação na prova e aos seus comentários durante e após a competição.
Há atletas que têm mais notícias selecionadas do que outros e o mesmo acontece com os sites de onde provêm as notícias. A seleção de páginas não se limitou aos primeiros resultados apresentados pelo motor de busca. Procurou-se variedade de canais e notícias de sites regionais e locais, alguns da região ou cidade de onde vieram os atletas.
Mais de 500 páginas para recordar a presença portuguesa em Paris
O contributo do Arquivo.pt, como poderá ver na tabela, já tem mais de 500 paginas Web.
Última atualização em 13 de Dezembro de 2024 às 13:56
Arquivo.pt preservou documentos online em várias línguas sobre as Eleições Parlamentares Europeias de 2019
As Eleições Parlamentares Europeias de 2019 foram um evento de relevância internacional. A estratégia para preservar a informação relevante na World Wide Web é delegada às instituições nacionais. No entanto, a preservação de páginas web que documentam eventos internacionais ainda não foi oficialmente atribuída.
A equipa do Arquivo.pt, com o objetivo de preservar o conteúdo online multilingue que documenta este evento, aplicou uma combinação de processos humanos e automáticos de seleção.
Na primeira etapa, foram identificados 40 termos relevantes em português sobre as Eleições Parlamentares Europeias de 2019, que foram posteriormente traduzidos automaticamente para as 24 línguas oficiais da União Europeia: búlgaro, croata, checo, dinamarquês, holandês, inglês, estónio, finlandês, francês, alemão, grego, húngaro, irlandês, italiano, letão, lituano, maltês, polaco, português, romeno, eslovaco, esloveno, espanhol e sueco.
Estas traduções foram revistas em colaboração com o Publications Office of the European Union. Além disso, paralelamente, foi lançada uma lista colaborativa para reunir contribuições de endereços relevantes oriundos da comunidade internacional.
Na segunda etapa, a equipa do Arquivo.pt executou iterativamente 6 recolhas (99 milhões de ficheiros web, 4,8 TB) utilizando diferentes configurações e software de recolha, para maximizar a qualidade do conteúdo recolhido.
Os dados web obtidos foram agregados numa coleção especial identificada como EAWP23 e tornaram-se pesquisáveis e acessíveis através do Arquivo.pt em julho de 2020 (https://arquivo.pt/ee2019).
Projeto CLEOPATRA: Cross-lingual Event-centric Open Analytics Research Academy
Daniel Gomes e Diego Alves apresentando no evento final do CLEÓPATRA.
A CLEOPATRA ITN foi uma Rede de Formação Inovadora Marie Skłodowska-Curie destinada a gerar formas de compreender melhor a cobertura digital massiva de grandes eventos na Europa durante as últimas décadas.
O principal objetivo era facilitar o processamento avançado multilíngue em grande escala de informações textuais e visuais acerca dos principais eventos contemporâneos e desenvolver métodos inovadores para acesso e interação eficientes com informações multilíngue.
No total, 14 pesquisadores em estágio inicial hospedados em 9 universidades europeias desenvolveram suas pesquisas enquanto estavam matriculados como estudantes de doutoramento.
Parceiros associados como o Arquivo.pt contribuíram para o CLEOPATRA acolhendo e formando investigadores em início de carreira como Diego Alves. No âmbito do programa de formação, este investigador realizou um estágio no Arquivo.pt em Lisboa de junho a agosto de 2022.
A ideia era desenvolver parte da sua investigação sobre estruturas sintáticas das línguas da UE utilizando os recursos textuais preservados pelo Arquivo.pt e trocar conhecimentos com os especialistas em preservação da web sobre estratégias de extração e processamento de dados históricos da web.
Gerando conjuntos de dados textuais para processamento de linguagem natural
O trabalho de Diego Alves originou conjuntos de dados multilíngues sobre as Eleições Parlamentares Europeias de 2019 que constituem recursos preciosos para investigação científica.
Este trabalho será detalhado no capítulo “Robustness of Corpus-based Typological Strategies for Dependency Parsing” do livro de acesso aberto CLEOPATRA intitulado “Event Analytics across Languages and Communities”.
Um fluxo de Processamento de Linguagem Natural em 3 etapas foi desenvolvido para gerar conjuntos de dados textuais que podem ser usados em diversos tipos de estudos na área de Humanidades Digitais:
Extrair texto: O conteúdo textual foi extraído de cada URL arquivado usando a biblioteca Python newspaper3k. O idioma de cada texto extraído foi determinado usando a biblioteca langdetect e os textos escritos em diferentes línguas foram armazenados em ficheiros distintos;
Limpar textos extraídos: um script Python foi aplicado para limpar os textos removendo informações desnecessárias (ex.: instâncias repetidas, linhas vazias, etc.);
Dupla verificação de identificação de língua: a língua de cada texto extraído e limpo foi verificada novamente para eliminar possíveis erros originados durante as etapas anteriores.
Dois novos conjuntos de dados para investigação em acesso-aberto!
Número de tokens de cada corpus extraídos da coleção Eleições da União Europeia 2019 preservados pelo Arquivo.pt (EAWP23).
O referido corpus foi anotado automaticamente quanto às relações gramaticais e de dependência para gerar um corpus com informações sintáticas úteis para estudos linguísticos.
Os textos anotados seguiram a mesma ordem dos respetivos ficheiros de texto originais. Cada frase foi anotada seguindo a Universal Dependencies framework no formato CoNNL-U, que é a referência em termos de anotação sintática em Processamento de Linguagem Natural. Assim, cada ficheiro deste conjunto de dados contém os textos anotados numa determinada língua sobre as Eleições da União Europeia de 2019.
Nos dias seguintes, 11 e 12 de maio, realizou-se a IIPC Web Archiving Conference (IIPC WAC), uma iniciativa aberta à comunidade, onde podem participar pessoas ou entidades não associodas ao IIPC e interessadas no domínio da preservação da Web.
Contributos do Arquivo.pt na Web Archiving Conference
O Arquivo.pt participou nas reuniões dos grupos de trabalho do IIPC (Training Working Group e Curators Working Group) e contribuiu com apresentações nas sessões temáticas Collaborations & Outreach e Program infrastructure (sessões 7 e 17).
O Arquivo.pt contribuiu com apresentações para as sessões Web Archive in Mediterranean area and its merge(4.A,), From online Tools to Web Archive (6.B.), Towards a participatory approach to collections (9. A.), Digging up the materials for writing web history (9.B.).
How to research governmental web data? (abstract, slides)
O Arquivo.pt participou em três cursos: Incentives design for hybrid multilingual information processing and analytics, em Southampton; National and transnational media coverage of European parliamentary elections, 2004-2014, Londres; e NLP for under-resourced languages, em Zagreb, na Croácia.
Em 2022, o Arquivo.pt acolheu dois investigadores nas suas instalações os quais utilizaram os recursos arquivados e tiveram apoio especial da equipa do Arquivo.pt para desenvolverem a sua investigação.
O projeto CLEOPATRA terminou em 2023 com a realização de um encontro a 16 de maio, em Hannover, que reuniu professores, investigadores e representantes de instituições envolvidas.
Daniel Gomes, Gestor do Arquivo.pt, destacou as novas ferramentas que o Arquivo.pt disponibiza e os resultados dos trabalhos realizados pelos investigadores que passaram pelo Arquivo.pt.
Secondments@Arquivo.pt and new research tools available (Slides)
Entre os conteúdos digitalizados que podem ser consultados no catálogo e acedidos nas instituições provedoras encontravam-se som, imagem, fotografia, material impresso digitalizado. Contudo, faltavam os Websites.
Assim, surgiu a ideia da nova coleção “Páginas Web” do MUVITUR.
Colaboração entre o MUVITUR e o Arquivo.pt
Em 2019, iniciou-se uma colaboração entre o Arquivo.pt e o MUVITUR com o objetivo de identificar sites relacionados com o Turismo em Portugal e de divulgar o histórico de conteúdos publicados na Web, desde 1996.
Em 2022, estabeleceu-se uma lista com cerca de 400 registos de websites de diversas entidades ligadas ao Turismo, hotéis, agências de viagens, páginas dos sites dos municípios com informação turística e outras.
O MUVITUR utiliza o software Nyron, o qual permite agregar conteúdos de diversas proveniências através do protocolo interoperabilidade OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting), cuja utilização é muito comum entre bibliotecas, arquivos e museus para fornecer conteúdos a portais, como por exemplo o Europeana.
O Arquivo.pt, porém, não disponibiliza informação através do OAI-PMH, pelo que foi necessário encontrar uma forma alternativa de criar um registo no Nyron com informação descritiva de Websites preservados.
O procedimento para a integração foi o seguinte:
Exportou-se para uma folha Excel o esquema XML com os campos para os metadados, de acordo com o que funciona no Nyron;
A informação foi inserida manualmente na folha Excel, respeitando o formato e a sintaxe, em colaboração com os técnicos responsáveis pelo sistema;
O ficheiro XML com os dados inseridos foi validado e importado para o Nyron.
A criação de registos em catálogos é em grande parte manual e exige uma curadoria humana. No entanto, foi possível introduzir informação para ser processada automaticamente nos registos da coleção de Websites. Por exemplo, a miniatura (thumbnail) foi obtida utilizando a API do Arquivo.pt, mais espeicificamento o linkToScreenShot, visível nos detalhes técnicos de uma página preservada (ver em Opções).
Para outros elementos, tais como o título do site, seria possível obtê-los automaticamente através da API do Arquivo.pt, no entanto a qualidade da informação depende do que os produtores do site inseriram e pode não ser a melhor. As datas para limitar o âmbito temporal também podem ser obtidas de forma automática. Privilegiou-se o método manual para controlar a informação apresentada.
Na continuidade do projeto, a coleção vai ser aumentada com novos registos, pois existem milhares de sites sobre o setor do Turismo.
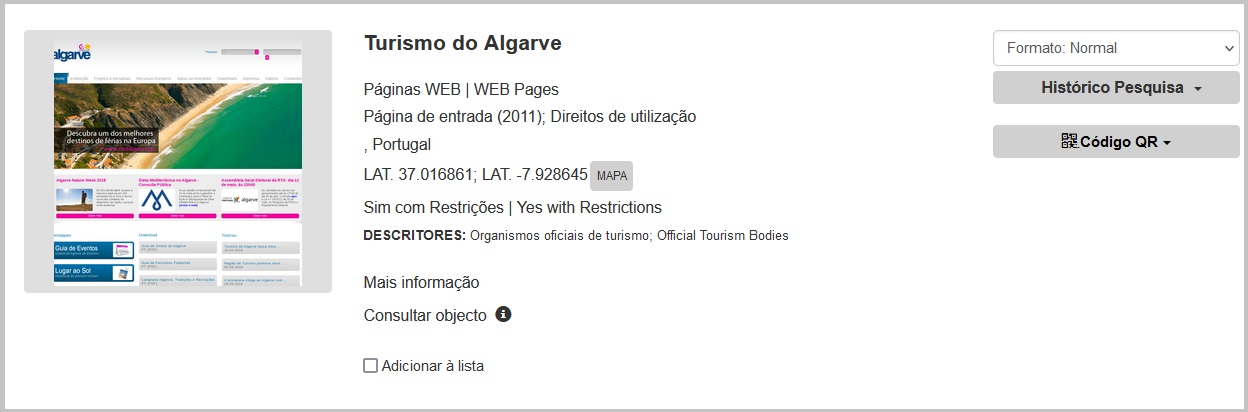
Descrição de conteúdos Web no catálogo do MUVITUR
Na coleção “Paginas Web” são utilizados os seguintes dados:
Denominação – geralmente o título do website
Organização – a entidade a quem pertence a publicação
Endereço do sítio Web na Internet
Endereço para versão no Arquivo.pt
Momento(s) para recordar
Link para miniatura no Arquivo.pt
Descritores
Dados geográficos (localização, coordenadas, nome geográfico)
A apresentação da informação foi ajustada para ficar alinhada com a de outros recursos do MUVITUR e contém ligações para o Arquivo.pt.
Por exemplo, no registo do site “Turismo do Algarve”, encontramos uma ligação para um momento a recordar em 2011 e outra a ligação para o histórico no Arquivo.pt em “Consultar objeto”.
Organizações podem criar coleções de Websites da sua área
Com este projeto inédito podemos dizer que os Websites preservados ganharam cidadania ou espaço em plataformas digitais dedicadas à memória histórica.
Os Websites raramente são incluídos em catálogos ou expostos em contexto museológico, em Portugal. Em breve, essa realidade pode mudar.
A National Library of Australia, por exemplo, tem registos de Websites preservados no catálogo. Na Tasmania Libraries o catálogo bibliográfico descreve em formato Marc21 mais de 3000 Websites preservados. Na Library of Congress há coleções de Websites antigos ao lado dos recursos tradicionais.
O MUVITUR abriu caminho para que outras entidades criem coleções de Websites do seu interesse nas suas plataformas.
No dia 15 de agosto de 2021 o palácio presidencial em Cabul foi tomado pelos Talibãs, consumando a queda do regime que vigorava há 20 anos, após os atentados do 11 de Setembro nos Estados Unidos.
Não há tempo a perder quando se trata de preservar a Web
O Arquivo.pt reagiu rapidamente lançando uma pesquisa automática de conteúdos focada em sites do domínio .af e em notícias dos media internacionais sobre os eventos em curso.
No dia 17 de agosto os websites começaram a ser gravados.
Foram utilizados 1800 endereços de sites do Afeganistão (terminados em .af) e 500 notícias dos meios de comunicação social de todo o mundo.
Os endereços, URLs ou “seeds” foram obtidos através de pesquisa automática, utilizando o Bing Search API, e colocados imediatamente em gravação.
Conteúdos disponíveis para conhecer a história do Afeganistão
Como resultado da recolha realizada passaram a estar disponíveis no Arquivo.pt mais de 400 Gigabytes de informação que qualquer pessoa pode utilizar para investigação nas mais diversas áreas.
O principal contributo do Arquivo.pt para a comunidade dos arquivistas da Web foi a demonstração da pesquisa automática que permite uma reação rápida na gravação de conteúdos Web em risco iminente de se perderem.
formação em preservação dos dados abertos publicados online.
A AMA é a organização pública responsável pela promoção dos meios digitais na Administração Pública e tem por objetivo modernizar e simplificar o acesso dos cidadãos aos serviços do Estado.
O Arquivo.pt é um serviço operado pela Fundação para a Ciência e a Tecnologia I.P. (unidade FCCN) que preserva dados publicados na Web entre 1996 e a atualidade, tornando-os acessíveis a qualquer cidadão para fins de memória e investigação.
Diretiva da União Europeia para dados abertos inclui documentos nos sítios na Internet
“(30) A presente diretiva prevê a definição do termo «documento» e essa definição deverá designar também qualquer parte do documento. O termo «documento» deverá abranger qualquer representação de atos, factos ou informações – e qualquer compilação destes –, seja qual for o seu meio (papel, suporte eletrónico, registo sonoro, visual ou audiovisual).
…
(34) A fim de facilitar a reutilização, os organismos do setor público deverão, se possível e adequado, disponibilizar os documentos, incluindo os que são publicados em sítios na Internet, num formato aberto e compatível com a leitura por máquina, juntamente com os respetivos metadados, ao melhor nível de precisão e granularidade, num formato que garanta a interoperabilidade
…
(35) Deverá considerar-se que um documento se apresenta em formato legível por máquina se tiver um formato de ficheiro estruturado de modo a ser facilmente possível, por meio de aplicações de software, identificar, reconhecer e extrair dados específicos. Os dados codificados em ficheiros estruturados num formato legível por máquina deverão ser considerados dados legíveis por máquina. Os formatos legíveis por máquina podem ser abertos ou sujeitos a direitos de propriedade; podem ser normas formais ou não.
…
(60) A Comissão deverá facilitar a cooperação entre Estados-Membros e apoiar a conceção, o ensaio, a aplicação e a implantação de interfaces eletrónicas interoperáveis que permitam dispor de serviços públicos mais eficazes e seguros.”
O serviço público Arquivo.pt tem a missão de preservar os documentos publicados nos sítios da Internet para viabilizar o seu acesso aberto a longo prazo e disponibiliza interfaces eletrónicas interoperáveis (APIs) para o seu processamento automático.
Qualquer cidadão pode aceder aos dados abertos resultantes destes arquivos históricos, podendo por exemplo, pesquisar informação oficial publicada em websites dos sucessivos Governos.
Em 2021, o Arquivo.pt disponibilizava acesso aberto a mais de 10 000 milhões de ficheiros (721 TB) oriundos de 27 milhões de websites. Os dados abertos preservados pelo Arquivo.pt podem ser explorados através da interface de pesquisa, automaticamente através de API (https://arquivo.pt/api) ou reutilizando os conjuntos de dados derivados.
Conjuntos de dados derivados disponíveis no Portal de Dados Abertos
Além dos artefactos web originais preservados no Arquivo.pt, este serviço tem gerado conjuntos de dados abertos derivados das suas atividades, que estão agora disponíveis em acesso aberto para que possam ser reutilizados:
Formulário de sugestão de endereços de páginas, sites e outros conteúdos Web
O Arquivo.pt convida todos os cidadãos a sugerirem páginas da Web relacionadas com as Eleições Presidenciais de 2021 para serem preservadas para o futuro.
As Eleições Presidenciais ocorrerão em Portugal no dia 24 de janeiro de 2021.
As suas sugestões são importantes para que o Arquivo.pt consiga guardar uma memória mais completa deste importante evento eleitoral.
A coleção especial de páginas Web acerca das Eleições Europeias de 2019 está disponível para pesquisa no Arquivo.pt.
Para compilar esta coleção, foram identificadas páginas escritas em 24 línguas europeias, através de pesquisas automáticas no motor de busca Bing e sugestões oriundas de 17 países europeus.
Convidam-se todos os cidadãos, especialmente os investigadores, a explorarem os conteúdos da Web do passado e a incluí-los nos seus trabalhos através deste serviço criado especialmente para pesquisar a coleção multi-lingue Eleições Europeias de 2019: https://arquivo.pt/ee2019
Vídeo “A transnational and cross-lingual crawl of the European Parliamentary Elections 2019”
A transnational and cross-lingual crawl of the European Parliamentary Elections 2019, Ivo Branco, IIPC Web Archiving Conference and RESAW 2021 (slides)
Milhares de páginas Web para contar a história da pandemia em Portugal
Desde março de 2020, o Arquivo.pt tem feito recolhas especiais de páginas Web relacionadas com a pandemia da Covid-19.
“Futuros académicos, cientistas e jornalistas que estejam a estudar a resposta portuguesa à pandemia da Covid-19 vão querer ler testemunhos em primeira mão de quem foi afectado, registos oficiais do número de vítimas, e recomendações dos médicos, políticos e cientistas da época”, Jornal Público, edição de 1 de maio de 2020.
Diariamente, foram recolhidos conteúdos de um conjunto de 106 sites sobre o tema da Covid-19. Neste conjunto incluem-se, por exemplo, websites da comunicação social, Governo, associações e iniciativas de universidades.
Num outro conjunto estão páginas do Twitter (108 identificadas em maio), vídeos do Youtube (815 identificados em maio) e ainda páginas do Reddit e do Git Hub.
Foram incluídas sugestões da comunidade, tais com as do arquivo municipal de Sines que contribuiu com uma recolha de notícias relacionadas com a Covid-19 no Município de Sines (9 GB), páginas identificadas pelo projeto “Revisionista.pt” e sugestões enviadas através do formulário público.
Colaboração do Arquivo.pt com o IIPC para coleção internacional
O Arquivo.pt foi dos primeiros serviços a responder, tendo contribuído com 1 237 endereços selecionados, principalmente em Língua Portuguesa.
Com os sucessivos contributos de outros países a coleção do IIPC cresceu. Em julho, as sugestões de websites a preservar superaram as 7 000 linhas e em agosto as 8000. Continua disponível um formulário de participação nesta coleção colaborativa.
O Arquivo.pt realizou 3 recolhas à coleção do IIPC, a primeira a 23 de março, a segunda a 15 de junho e a terceira no final de agosto, acrescentando ao seu acervo conteúdos internacionais para servirem a investigadores de todo o mundo.
Metodologia para a seleção de páginas para a coleção Covid-19
Começou-se por identificar termos relacionados com a temática do Coronavírus que incluíram aspetos sanitários, económicos, políticos, geográficos ou organizacionais.
Em seguida, utilizou-se o serviço Bing Azure, para obter automaticamente através de um script, a seguinte informação para os primeiros 10 resultados para cada termo: o endereço da página, o título e a posição na lista de resultados.
Sobre o conjunto de endereços obtido, averiguou-se qual seria o software de recolha a utilizar e respectivas configurações para recolher as páginas com a melhor qualidade possível.
Por exemplo, no caso de uma secção de jornal dedicada à Covid-19, há que decidir se gravamos apenas uma página ou se faz sentido recolher todo o site exaustivamente.
Foram utilizados diversos tipos de software para recolher as páginas. Por exemplo, para as recolhas diárias sobre 106 sites utilizou-se o Heritrix. Para a captura de 108 páginas do Twitter optou-se pelo Brozzler e para os vídeos a captura manual com o Webrecorder e Browsertrix.
Foram realizadas 2 recolhas, durante e após o período de campanha eleitoral, que partiram da lista de 410 sites sugeridos pela comunidade, e de 13 887 sites relacionados com as eleições encontrados automaticamente através de motores de busca.
O processo de identificação manual originou uma lista de 337 endereços que documentavam as candidaturas às Eleições Autárquicas de 2017. Note-se que 46% destes endereços apontavam para a rede social Facebook.com e que grande parte destes conteúdos de interesse nacional não puderam ser preservados porque esta empresa privada estrangeira não o permite.
O resultado final foi um arquivo de 2 265 887 ficheiros recolhidos da Web (360 GB).
Nos sites recolhidos encontram-se por exemplo os sites oficiais das campanhas dos candidatos aos vários concelhos e freguesias, notícias na comunicação social, blogs e artigos de opinião.
O Arquivo.pt respeita um período de embargo de 1 ano, pelo que esta colecção só estará disponível para consulta no final de 2018.
Contudo, pode consultar já alguns sites das Eleições Autárquicas anteriores, tais como:


.")