
Última atualização em 5 de Dezembro de 2023 às 20:12
O Arquivo.pt acabou de acumular 1 PetaByte de conteúdos no seu acervo no mês em que completou 16 anos de existência.
Esta informação está acessível tanto para os investigadores como para o cidadão comum.
No Arquivo.pt é possível pesquisar informação publicada na Web no passado, como por exemplo:
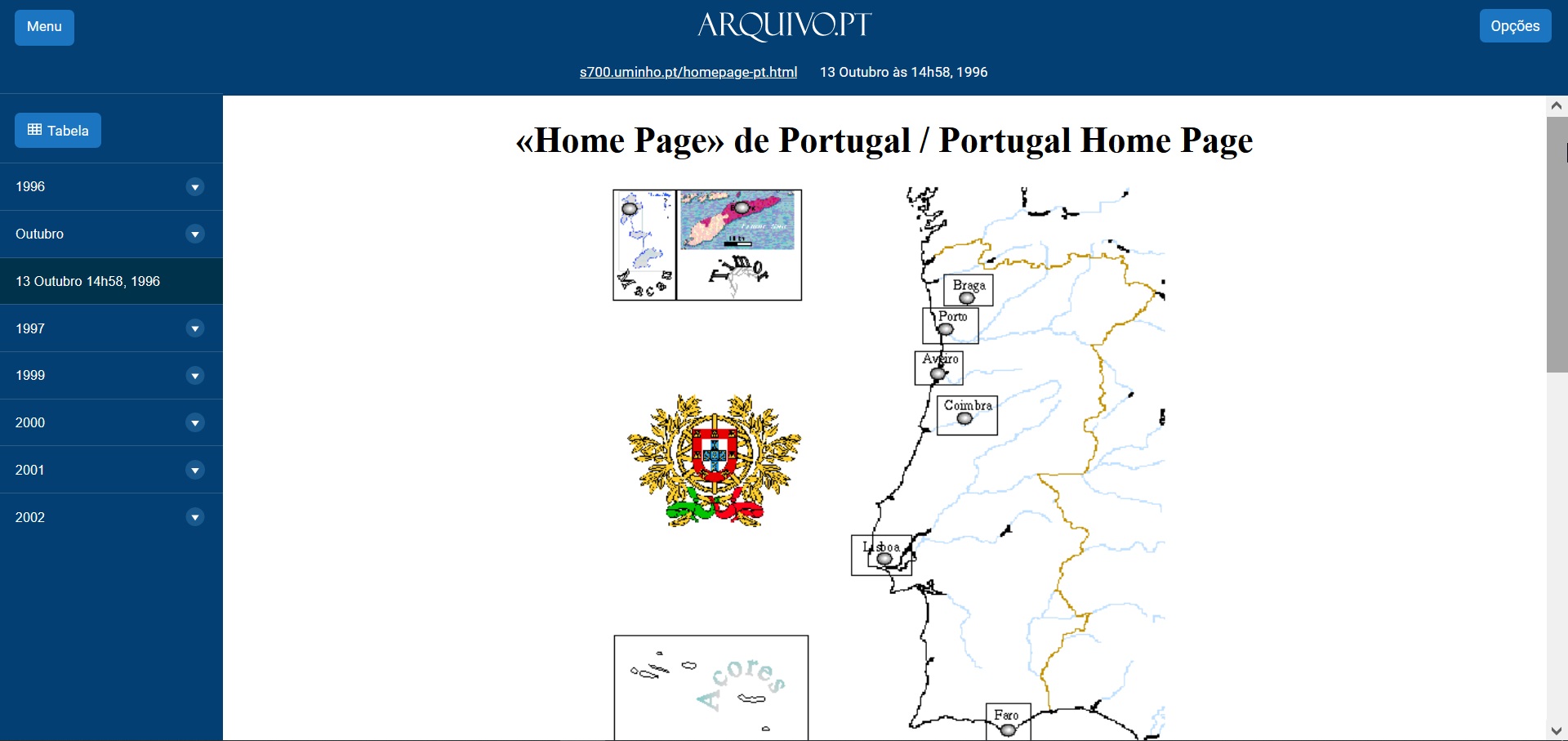
- A primeira página da Web portuguesa
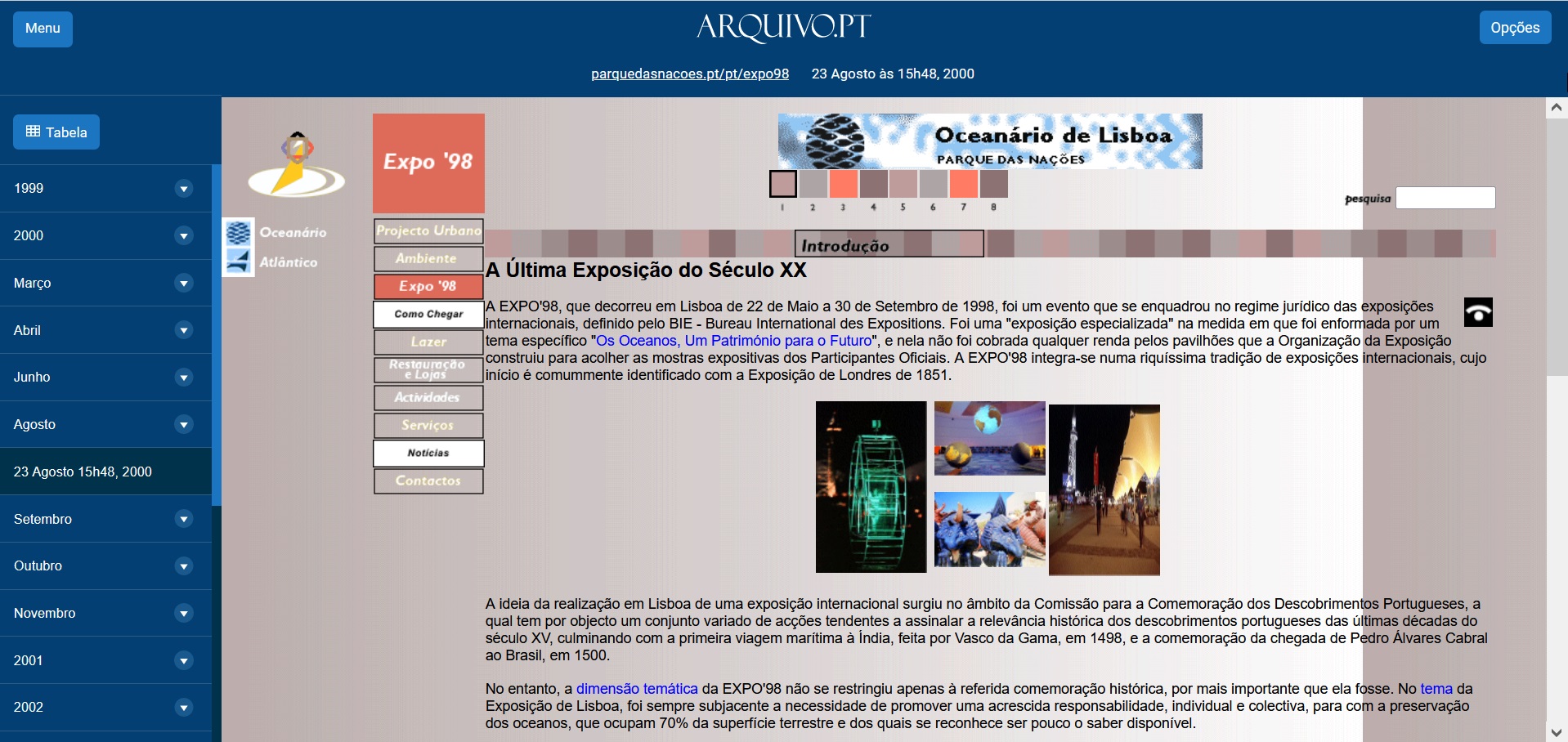
- O site oficial da Expo’98
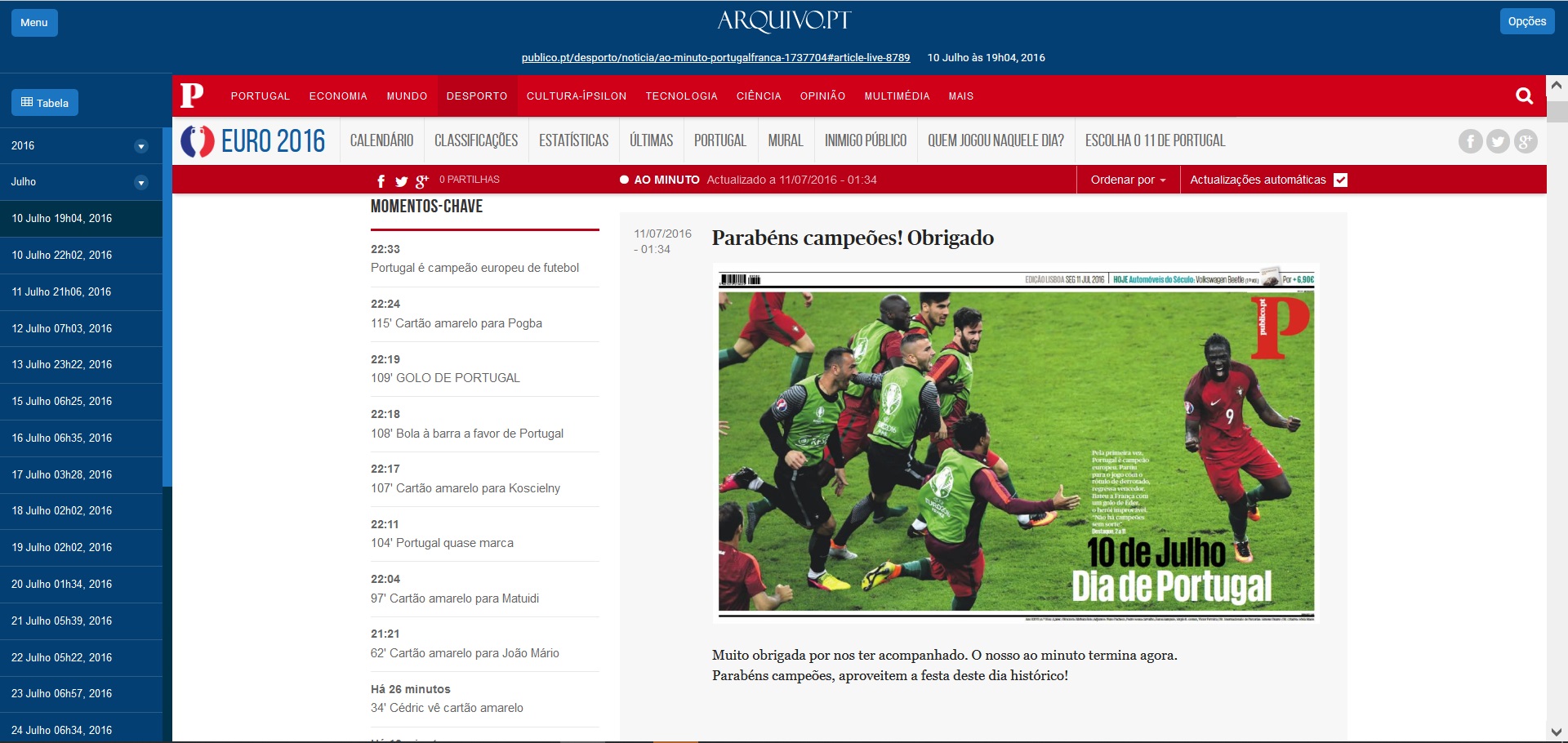
- Notícias do jornal Público no dia da final do Campeonato Europeu de Futebol de 2016
Descubra mais páginas através das paginas selecionadas nas Exposições Online do Arquivo.pt.

Objetivo e missão do arquivo da Web de Portugal
O Arquivo.pt foi criado a 8 de novembro de 2007 com o objetivo de preservar conteúdos da Web portuguesa.
Em 2013, enquanto serviço operado pela Fundação para a Ciência e a Tecnologia, a sua missão foi formulada nestes termos: “Promover a preservação de conteúdos disponíveis na Internet nacional, garantindo a disponibilização deste à comunidade científica e ao público em geral” (Decreto Lei nº55/2013).
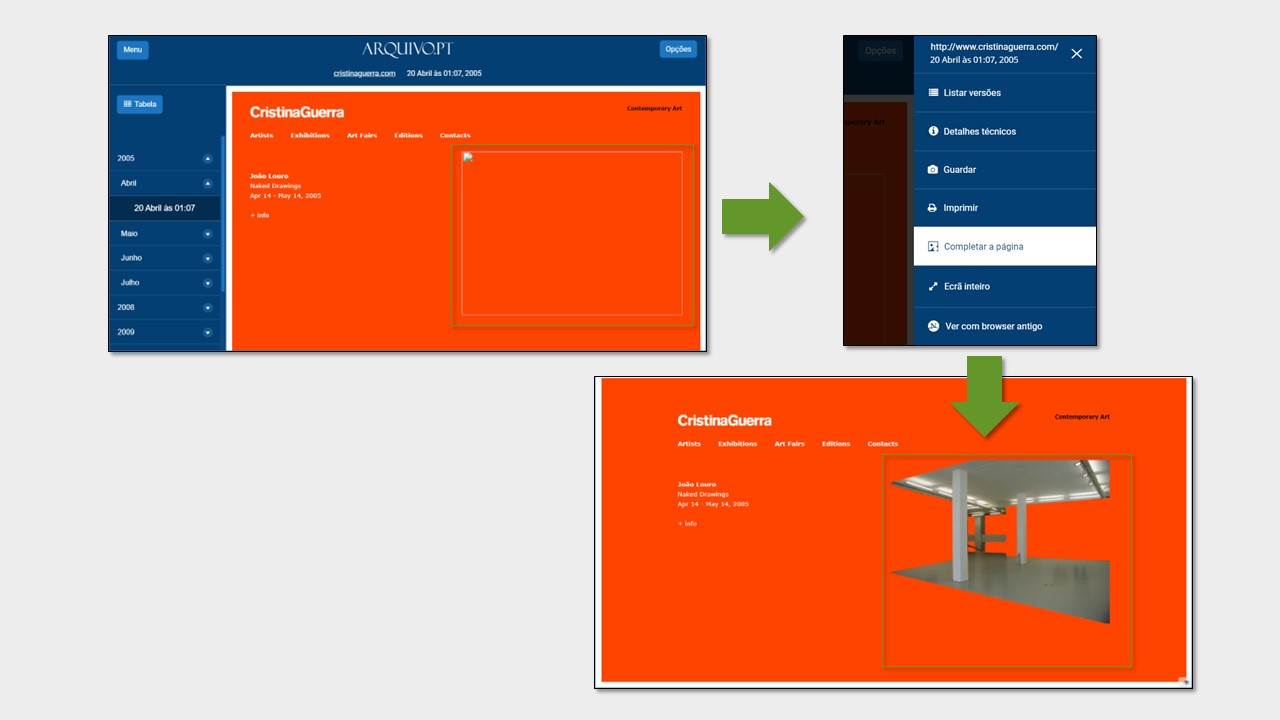
Nos anos mais recentes, o Arquivo.pt tem criado novos serviços tais como o CitationSaver que permite aos investigadores gravarem as referências a conteúdos Web que constam nos seus artigos científicos. O Memorial e o Completar a Página facilitam o acesso aos conteúdos dispersos no enorme bloco de 1 PetaByte de dados.
De onde veio tanta informação?
Para atingir o volume de 1 PetaByte, o Arquivo.pt gravou periodicamente conteúdos dos sites do domínio .PT e de sites portugueses noutros domínios.
Além disso, foram feitas recolhas frequentes, diárias e mensais, a um pequeno conjunto de sites governamentais e aos principais sites noticiosos em Portugal.
No âmbito de colaborações internacionais, foram recolhidos conteúdos de sites em diversas línguas, como por exemplo sobre as Eleições Europeias de 2019.
Os conteúdos anteriores a 2008 vieram do Internet Archive e de doações, como é o caso de uma coleção feita pela Biblioteca Nacional e pelo INESC sobre as Eleições Legislativas de 2005.
O maior conjunto de dados em língua portuguesa em acesso aberto para os investigadores
Ao disponibilizar 1 PetaByte de informação, em acesso aberto e através do uso de APIs (Application Programming Interfaces), o Arquivo.pt é uma ferramenta útil para a investigação.
Por exemplo, um investigador que pretender fazer um estudo sobre as eleições em Portugal pode utilizar todo o acervo do Arquivo.pt. Melhor ainda, pode focar-se apenas em algumas recolhas especiais dedicadas às eleições, escolhendo as que lhe interessam e descarregando apenas alguns Terabytes para processar automaticamente com as APIs.
Contributo de diversas equipas e dos amigos do Arquivo.pt
O desenvolvimento do Arquivo.pt vai para além da questão tecnológica e deve-se à dedicação e persistência das diversas pessoas que nele trabalharam, desde 2007.
Deve-se também ao contributo de muitos amigos do Arquivo.pt, sempre atentos para ajudar a melhorar, e à resposta da comunidade de utilizadores.
“Parabéns campeões! Obrigado”








.")








































{kind=link}