Última atualização em 3 de Dezembro de 2025 às 12:55
As Eleições Autárquicas realizaram-se, em Portugal, a 12 de outubro de 2025 e o Arquivo.pt fez uma recolha especial de conteúdos eleitorais publicados na Web, de que resultaram 3.5 terabytes de informação para a investigação e a realização de trabalhos.
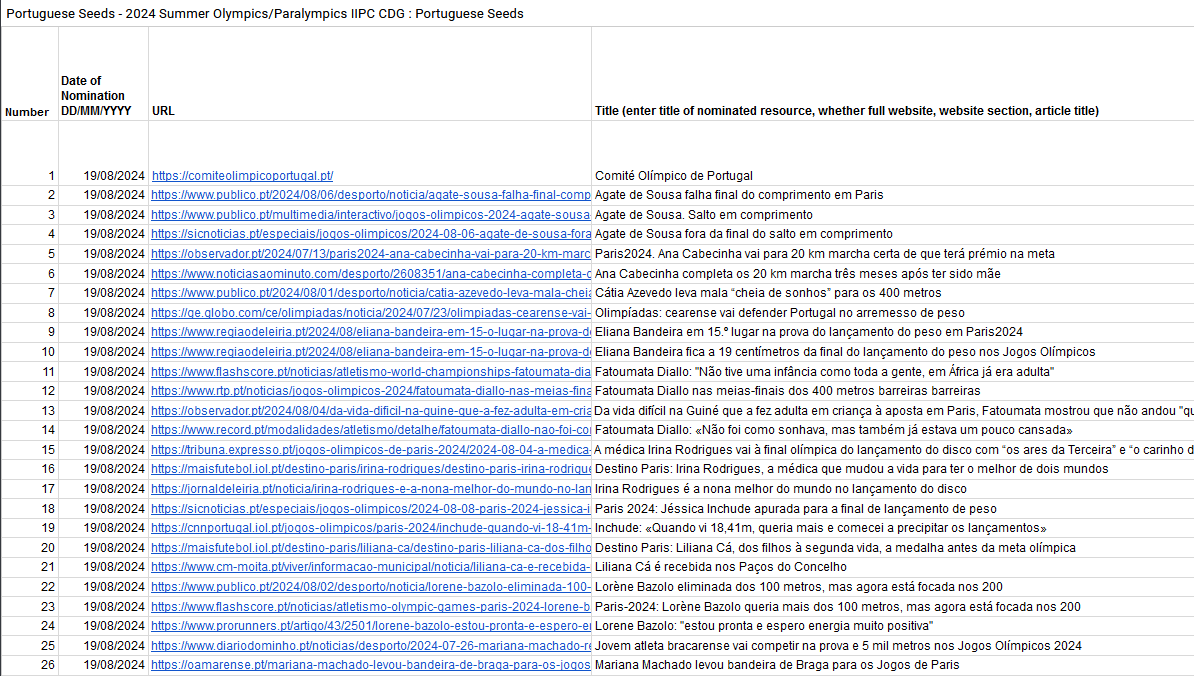
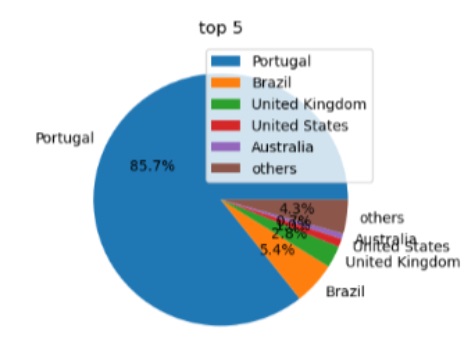
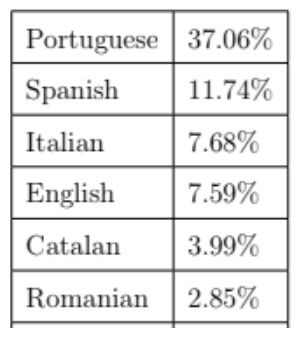
Foram utilizados 440 termos de pesquisa para obter 45 000 endereços de páginas, juntamente com os websites das freguesias, municípios e partidos.
Aqui se explica os diversos passos desta recolha sobre as eleições:
Como se identificam os conteúdos eleitorais na Web
Para identificar conteúdos relacionados com as eleições utilizamos uma lista de termos de pesquisa como, por exemplo, “eleições autárquicas 2025″, “habitação autárquicas 2025″, “promessas “autárquicas 2025”. Depois das eleições completou-se com outros termos como “vitória autárquicas 2025”, “resultados autárquicas 2025”, etc.
Os termos de pesquisa são palavras que pretendem incluir diversos tópicos relacionados com as eleições, tais como política, sociedade, economia, entre outros, meios de comunicação, nomes de candidatos, regiões do país.
Na recolha sobre as Autárquicas, utilizou-se o motor de busca Google para fazer cada uma das pesquisas. Recorreu-se a alguns parâmetros da pesquisa avançada: o número de resultados (&num=100), resultados de nótícias (&tbm=nws), resultados de imagens (&udm=2). Depois das eleições, restringiu-se os resultados com o filtro “última semana”.
Em cada pesquisa extraiu-se os endereços das páginas de resultados do motor de busca (SERP, Search Engine Results Page) utilizando a ferramenta Google Rank Checker,Keyword SERP Ranking Tool. Esta ferramenta funciona como uma extensão do browser que exporta a lista de resultados no formato JSON.
No total, foram realizadas 1400 pesquisas ou queries no Google (800 em pré-eleições, 600 em pós-eleições). No final, os resultados de todas as pesquisas (ficheiros .json) foram reunidos num documento e convertidos em tabela. Cada resultado tem vários dados, tais como a relevância, o domínio de onde foi extraído, o link ou URL, o título da publicação, a data da pesquisa e a query.
Deve ter-se em conta que a lista obtida representa apenas uma pequena parcela de tudo o que foi publicado na Web acerca das eleições. Além disso, a mesma lista contém resultados não relacionados com o objetivo da recolha (falsos positivos) e algumas repetições. Por economia de tempo, nenhuma linha foi eliminada.
Deste processo de identificação resultaram 43 000 páginas (seeds) com notícias, artigos e publicações relacionadas com as eleições para serem usadas no processo de recolha pelo Arquivo.pt. Este conjunto de dados “Eleições Autárquicas 2025” está disponível na plataforma de dados abertos Dados.Gov.
Adicionou-se ainda a lista das Juntas de Freguesia, Câmaras Municipais e Partidos com os seus respectivos websites.
Como foram gravados os conteúdos e limitações a ter em conta
Os endereços obtidos, antes e depois das eleições, foram colocados a gravar em dois web crawlers ou rastreadores da Web, o Heritrix e o Browsertrix-crawler. O que estas ferramentas fazem é gravar páginas a partir de um endereço inicial que é dado (seed), seguindo depois as ligações aí existentes, até um certo limite, neste caso até um máximo de 5 vezes (5 saltos ou hops).
O Heritrix foi utilizado para uma primeira recolha genérica de páginas, pois é capaz de processar listas com milhares de endereços com rapidez: 25 858 URLs antes das eleições e 17 258 URLs depois das eleições. Gerou 541 Gigabytes de informação.
O Browsertix-crawler foi utilizado como segunda ferramenta para melhorar a recolha de conteúdos dinâmicos. Neste crawler a gravação é baseada em browser, ou seja, cada página é lida por um browser e depois é gravada. A gravação é mais demorada, mas captura conteúdos que de outro modo escapariam à recolha.
A recolha correu no Browsertrix-crawler de modo faseado, primeiro com a gravação dos websites das freguesias em agosto e setembro e, depois, entre 9 de outubro e 5 de novembro, com a gravação de notícias sobre as eleições e 8.850 publicações nas redes sociais. Gerou 2.9 Tetabytes de informação.
Quanto aos limites da recolha, identificou-se alguns, tais como: bloqueio do acesso por parte de alguns sites que se defendem contra acessos automáticos, apesar de o agente do Arquivo.pt estar identificado; conteúdos de redes sociais, atrás de login que não se consegue reproduzir no Arquivo.pt; vídeos que pelo seu formato também não se consegue reproduzir.
Como e quando aceder ao dados para investigar e criar de trabalhos
EAWP48 é o nome identificador da coleção que vai reunir os conteúdos sobre as Eleições Autárquicas de 12 de outubro de 2025. Uma descrição, assim como o seu estado (disponível ou não) pode ser consultado na lista de coleções do Arquivo.pt.
Nos próximos meses, o conteúdo será indexado e os índices CDXJ ficarão disponíveis para os investigadores na lista de datasets do Arquivo.pt.
Passado um ano, os conteúdos recolhidos ficarão acessíveis na pesquisa do Arquivo.pt . Qualquer pessoa poderá então pesquisar páginas eleitorais por texto ou por imagem.
Para mais informação contacte-nos.
Dados da recolha Eleições Autárquicas 2025
Saiba mais sobre as recolhas eleitorais de anos anteriores