Este evento é um encontro para partilha de conhecimento entre as entidades que compõem a comunidade de ensino superior e de investigação nacionais.
O evento conta com a participação de decisores das instituições, responsáveis por serviços técnicos de informática e responsáveis por bibliotecas e serviços de documentação, entre outros.
O Arquivo.pt apresentou duas sessões de 90 minutos, no dia 28 de junho das 14h30 às 18h00, sob o tema “Serviços Arquivo.pt para gerir citações e cibersegurança”.
Agenda da sessões Arquivo.pt
28 de junho 14h30-16h00: Arquivo.pt – serviços disponíveis e arquitetura de sistema
Entre os conteúdos digitalizados que podem ser consultados no catálogo e acedidos nas instituições provedoras encontravam-se som, imagem, fotografia, material impresso digitalizado. Contudo, faltavam os Websites.
Assim, surgiu a ideia da nova coleção “Páginas Web” do MUVITUR.
Colaboração entre o MUVITUR e o Arquivo.pt
Em 2019, iniciou-se uma colaboração entre o Arquivo.pt e o MUVITUR com o objetivo de identificar sites relacionados com o Turismo em Portugal e de divulgar o histórico de conteúdos publicados na Web, desde 1996.
Em 2022, estabeleceu-se uma lista com cerca de 400 registos de websites de diversas entidades ligadas ao Turismo, hotéis, agências de viagens, páginas dos sites dos municípios com informação turística e outras.
O MUVITUR utiliza o software Nyron, o qual permite agregar conteúdos de diversas proveniências através do protocolo interoperabilidade OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting), cuja utilização é muito comum entre bibliotecas, arquivos e museus para fornecer conteúdos a portais, como por exemplo o Europeana.
O Arquivo.pt, porém, não disponibiliza informação através do OAI-PMH, pelo que foi necessário encontrar uma forma alternativa de criar um registo no Nyron com informação descritiva de Websites preservados.
O procedimento para a integração foi o seguinte:
Exportou-se para uma folha Excel o esquema XML com os campos para os metadados, de acordo com o que funciona no Nyron;
A informação foi inserida manualmente na folha Excel, respeitando o formato e a sintaxe, em colaboração com os técnicos responsáveis pelo sistema;
O ficheiro XML com os dados inseridos foi validado e importado para o Nyron.
A criação de registos em catálogos é em grande parte manual e exige uma curadoria humana. No entanto, foi possível introduzir informação para ser processada automaticamente nos registos da coleção de Websites. Por exemplo, a miniatura (thumbnail) foi obtida utilizando a API do Arquivo.pt, mais espeicificamento o linkToScreenShot, visível nos detalhes técnicos de uma página preservada (ver em Opções).
Para outros elementos, tais como o título do site, seria possível obtê-los automaticamente através da API do Arquivo.pt, no entanto a qualidade da informação depende do que os produtores do site inseriram e pode não ser a melhor. As datas para limitar o âmbito temporal também podem ser obtidas de forma automática. Privilegiou-se o método manual para controlar a informação apresentada.
Na continuidade do projeto, a coleção vai ser aumentada com novos registos, pois existem milhares de sites sobre o setor do Turismo.
Descrição de conteúdos Web no catálogo do MUVITUR
Na coleção “Paginas Web” são utilizados os seguintes dados:
Denominação – geralmente o título do website
Organização – a entidade a quem pertence a publicação
Endereço do sítio Web na Internet
Endereço para versão no Arquivo.pt
Momento(s) para recordar
Link para miniatura no Arquivo.pt
Descritores
Dados geográficos (localização, coordenadas, nome geográfico)
A apresentação da informação foi ajustada para ficar alinhada com a de outros recursos do MUVITUR e contém ligações para o Arquivo.pt.
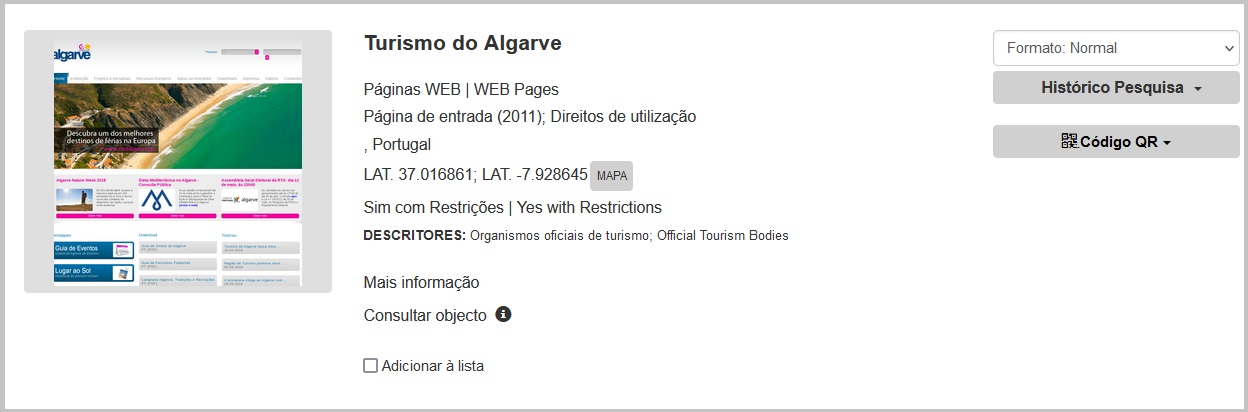
Por exemplo, no registo do site “Turismo do Algarve”, encontramos uma ligação para um momento a recordar em 2011 e outra a ligação para o histórico no Arquivo.pt em “Consultar objeto”.
Organizações podem criar coleções de Websites da sua área
Com este projeto inédito podemos dizer que os Websites preservados ganharam cidadania ou espaço em plataformas digitais dedicadas à memória histórica.
Os Websites raramente são incluídos em catálogos ou expostos em contexto museológico, em Portugal. Em breve, essa realidade pode mudar.
A National Library of Australia, por exemplo, tem registos de Websites preservados no catálogo. Na Tasmania Libraries o catálogo bibliográfico descreve em formato Marc21 mais de 3000 Websites preservados. Na Library of Congress há coleções de Websites antigos ao lado dos recursos tradicionais.
O MUVITUR abriu caminho para que outras entidades criem coleções de Websites do seu interesse nas suas plataformas.
A comunidade académica e de investigação tem solicitado a possibilidade de descarregar automaticamente seleções de conteúdos arquivados e ficheiros de índice (CDXJ), por exemplo, para alimentar modelos de aprendizagem automática de Inteligência Artificial ou recuperar informação de sítios web selecionados (ex. notícias ou websites que foram atacados).
O Arquivo.pt passou a disponibilizar publicamente os seus ficheiros de índice CDXJ em tempo real, para facilitar o acesso automático a grandes volumes de conteúdos arquivados da web. Saiba como em:
Última atualização em 21 de Novembro de 2023 às 16:03
Os documentos citam conteúdos da Web referenciando os seus endereços (URL) para que o leitores possa vir a aceder-lhes.
No caso dos artigos científicos, a importância destas citações é ainda maior para manter a integridade de uma investigação porque muitas vezes referenciam informação fundamental para permitir a reprodutibilidade de uma experiência ou análise.
Por exemplo, as ligações num artigo científico podem citar os conjuntos de dados, software ou notícias da web que suportaram a investigação e que não estão incluídos no texto do artigo científico.
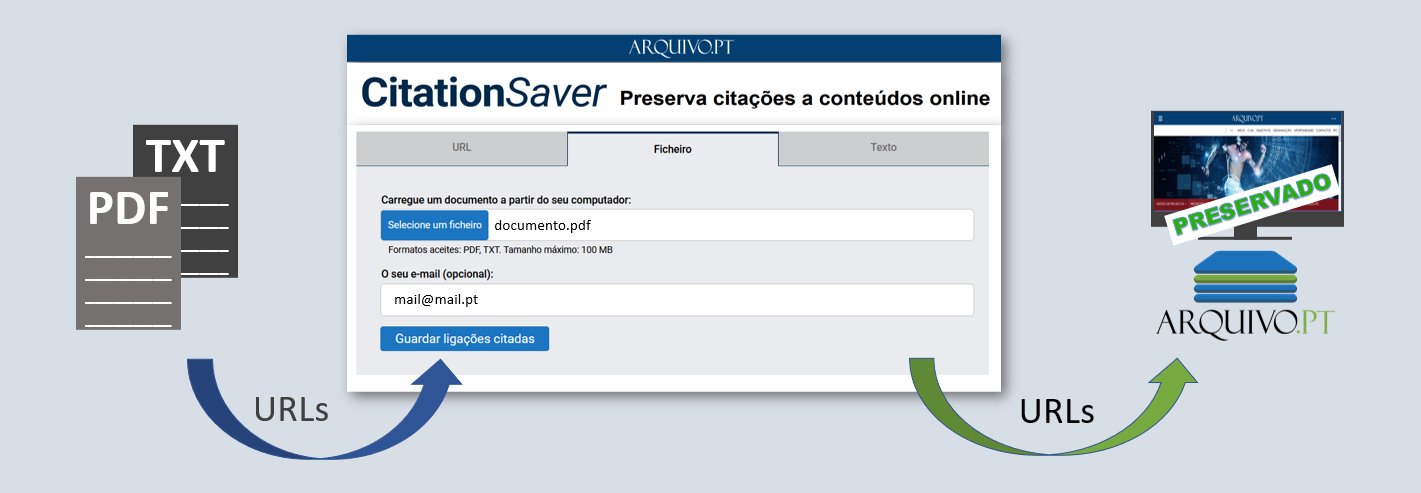
Para responder à necessidade de preservar a integridade dos documentos, o Arquivo.pt criou o CitationSaver.
O CitationSaver automaticamente extrai as ligações citadas num documento e preserva o seu conteúdo (ex. páginas web citadas num livro) para que possam ser recuperadas mais tarde a partir do Arquivo.pt.
Use o CitationSaver para preservar a integridade dos seus documentos
Carregue um documento e o CitationSaver extrairá os endereços citados, gravando os seus conteúdos e disponibilizando-os no Arquivo.pt passado pouco tempo. Existem 3 métodos para carregar um documento:
insira o endereço (URL) do ficheiro PDF ou TXT, se este estiver publicado online
carregue o ficheiro em formato PDF ou TXT
cole o texto que contem os endereços que pretende preservar (ex. secção de Referências de um artigo ou Bibliografia de um livro)
Última atualização em 26 de Junho de 2023 às 17:33
As organizações mantêm domínios em sua posse que referenciavam websites apesar de já não os utilizarem, para evitar que sejam comprados ou apenas por esquecimento.
O objetivo do projeto Renascer é trazer de volta websites históricos cujo conteúdo deixou de estar disponível online e cujo domínio continua a ser detido pelos seus autores.
Domínios “esquecidos” podem causar problemas de cibersegurança
Nesta situação, o conteúdo original do website estava inacessível apesar do domínio continuar a ser detido pelo autor do website.
Além disso, uma vez que o domínio continuava a apontar para um servidor web ativo, se este não estiver a ser atualizado poderão ocorrer problemas de cibersegurança.
O dono do domínio apenas tem de o redirecionar para o Arquivo.pt, através do serviço Memorial.
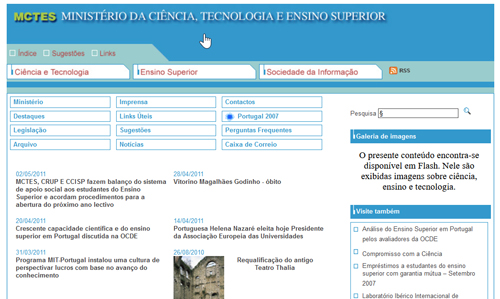
Por exemplo, o domínio mctes.pt passou a apontar para os seus conteúdos originais preservados no Arquivo.pt, fazendo assim Renascer este website.
Exemplos de domínios Renascidos
O projeto Renascer identificou domínios ativos geridos pela FCCN que não referenciavam conteúdo, e passou a dar-lhes nova vida com os conteúdos históricos preservados no Arquivo.pt.
Contacte o Arquivo.pt para fazer Renascer os websites históricos da sua organização.
Veja os seguintes exemplos de websites Renascidos:
O Arquivo.pt é um serviço público e gratuito que permite pesquisar e aceder a páginas da Web preservadas desde a década de 1990, como por exemplo, ver uma notícia antiga ou aceder a uma versão antiga de um website.
A colaboração entre o AMCC e o Arquivo.pt concretiza-se num programa de formação intitulado Arquivo.pt: Competências Digitais para os Media, desenvolvido em quatro webinars, e na atribuição da Menção Honrosa AMCC a trabalhos realizados sobre jornais centenários portugueses para o Prémio Arquivo.pt 2023.
Ciclo de webinars “Arquivo.pt: Competências Digitais para os Media”
O ciclo de webinars visa dotar os formandos de competências digitais que lhes permitam resolver problemas originados pelo desaparecimento de informação digital e ganhar vantagem competitiva na produção de conteúdos únicos e exclusivos.
Webinar 1: Arquivo.pt: uma ferramenta para pesquisar rapidamente o passado
Data: 24 de março de 2023 Hora: 14h00-15h30 (PT), Língua: Portuguesa
Última atualização em 6 de Agosto de 2024 às 17:24
Até dia 4 de maio, o Arquivo.pt lança o desafio de criar um trabalho baseado em informação histórica preservada da Web.
Nesta 6ª edição do Prémio Arquivo.pt serão atribuídos 15 000 € aos três melhores trabalhos (1º classificado: 10 000 €).
Podem concorrer trabalhos realizados individualmente ou em grupo sobre qualquer tema, desde que o Arquivo.pt seja a fonte principal de informação.
O Jornal Público atribuirá uma Menção Honrosa para os trabalhos realizados com base nos conteúdos do Público online guardados no Arquivo.pt.
O Aveiro Media Competence Center (AMCC) atribuirá também uma Menção Honrosa a um dos trabalhos submetidos que se foque no arquivos da versão online de jornais centenários.