Última atualização em 7 de Novembro de 2025 às 15:55
No Dia Mundial da Preservação Digital, o Arquivo.pt promoveu uma sessão em linha dedicada à anotação de resultados de pesquisa no Arquivo.pt, no dia 6 de novembro, das 15h às 16 horas.
Foram abordados os seguintes tópicos:
i) O acesso como prioridade – pesquisa por texto como um motor de busca para o passado
ii) Como são processados os conteúdos arquivados
iii) Anotações como verificação de qualidade – demonstração
A equipa do Arquivo.pt tem vindo a reimplementar a pesquisa por texto no Arquivo.pt, mas precisa de medir a qualidade da nova implementação comparando-a com a anterior. Para isso apela à colaboração da comunidade.
Última atualização em 5 de Setembro de 2025 às 9:49
A natureza interligada da World Wide Web há muito que fascina investigadores e tecnólogos. Hoje, temos o prazer de anunciar o lançamento do conjunto de dados Arquivo.pt Links Dataset, uma coleção abrangente que abre novas possibilidades para a compreensão e análise dos padrões de conetividade da Web.
O conjunto de dados engloba mais de 139 milhões de URLs de páginas Web, cada um acompanhado de metadados cruciais sobre as suas ligações de entrada – tanto os URLs de origem como os textos-âncora correspondentes, isto é, o texto visível e clicável nas hiperligações. Esta rica coleção de dados de interligação fornece aos investigadores uma janela única para a estrutura subjacente da Web.
A importância das hiperligações na arquitetura da Web não pode ser sobrestimada. Servem como blocos de construção fundamentais da navegação e descoberta na Web, permitindo aos utilizadores e aos sistemas automatizados percorrer a vasta paisagem de conteúdos em linha.
As hiperligações formaram a base do revolucionário algoritmo PageRank da Google, que transformou a nossa abordagem à recuperação de informações e à pesquisa na Web. A ideia fundamental do PageRank – que a importância de uma página podia ser medida através da análise das suas hiperligações de entrada – revolucionou a tecnologia de pesquisa e continua a ter influência nos sistemas modernos de recuperação de informações.
Ao disponibilizar publicamente este conjunto de dados, o Arquivo.pt permite aos investigadores explorar abordagens inovadoras semelhantes à análise da Web e ao desenvolvimento de motores de busca. O conjunto de dados abre inúmeras possibilidades de investigação em vários domínios:
Os investigadores podem implementar e experimentar vários algoritmos de classificação, desde abordagens clássicas como o PageRank até técnicas modernas baseadas na aprendizagem automática. A inclusão de textos âncora – o texto visível e clicável nas hiperligações – fornece um contexto semântico valioso que pode melhorar a relevância da pesquisa e a classificação dos documentos.
O conjunto de dados permite uma análise profunda da topologia da Web e das estruturas de ligações. Os investigadores podem investigar questões sobre os padrões de conetividade da Web, identificar grupos de conteúdos relacionados e estudar a forma como a informação se espalha pela Web através de redes de ligações.
O texto âncora associado a cada hiperligação oferece uma fonte rica de descrições do conteúdo da Web geradas por humanos. Estes dados podem ser particularmente valiosos para desenvolver e testar algoritmos de resumo de documentos, ferramentas de análise semântica e sistemas de classificação automática.
Para os investigadores de arquivo da Web, este conjunto de dados fornece informações sobre a forma como as páginas da Web são ligadas e referenciadas ao longo do tempo, oferecendo dados valiosos para o estudo de estratégias de preservação da Web e de manutenção do património digital.
Metodologia
O processo começa com um instantâneo temporal de páginas Web de um período de tempo específico (recolha). Durante esta fase inicial, os nossos sistemas analisam cada página capturada, extraindo todas as hiperligações de saída juntamente com os respetivos textos âncora e carimbos de data/hora de captura. Isto cria um mapeamento preliminar de como as páginas se ligam umas às outras dentro do período de tempo capturado.
O que torna este conjunto de dados particularmente valioso é a sua estrutura de links invertida. Em vez de organizar os dados em torno das páginas de origem e dos seus links de saída, criámos um mapa invertido que se centra nas páginas de destino e nos seus links de entrada. Essa abordagem é particularmente útil para analisar a importância ou a autoridade de uma página na estrutura da Web, pois fornece acesso imediato a todas as páginas que fazem referência ou apontam para um determinado URL.
Considere-se uma estrutura de ligações tradicional em que a Página A liga às Páginas B, C e D. Na nossa estrutura invertida, vemos entradas para as Páginas B, C e D, cada uma listando a Página A como uma fonte de ligações de entrada. Esta reorganização dos dados facilita uma análise mais eficiente da autoridade e influência da página, tornando-a particularmente valiosa para investigadores que trabalham em algoritmos de classificação ou que estudam padrões de fluxo de informação na Web.
O conjunto de dados de links do Arquivo.pt combina três colecões web distintas:
PWA9609 (1996-2009): 89 milhões de páginas que captam a evolução inicial da Internet, centradas no domínio .pt. Esta coleção histórica fornece informações sobre os primeiros padrões de ligação na Web.
AWP38 (Out-Nov 2021): 44 milhões de páginas que oferecem um retrato contemporâneo da conetividade da Web, com ênfase no domínio .pt, mas incluindo conteúdos mais vastos da Internet.
FAWP47 (Out-Dez 2021): 8 milhões de páginas de capturas diárias de conteúdo do domínio .pt, concebidas para acompanhar as alterações de curto prazo nos padrões de ligação.
Como começar a utilizar o conjunto de dados
Os investigadores podem aceder ao conjunto completo de dados. Os dados são fornecidos num formato que permite um processamento e análise eficientes, tornando-os adequados tanto para estudos em grande escala como para investigações específicas.
O lançamento do conjunto de dados de links do Arquivo.pt representa uma contribuição significativa para a comunidade de investigação científica da Web. Ao disponibilizar gratuitamente esta rica coleção de dados de conetividade da Web, esperamos facilitar a investigação inovadora e aprofundar a nossa compreensão da complexa estrutura da Web.
Encorajamos os investigadores a explorar este conjunto de dados e esperamos ver as novas perspetivas e aplicações que emergem da sua análise. Quer esteja interessado em desenvolver novos algoritmos de pesquisa, estudar a topologia da Web ou investigar relações de conteúdo, este conjunto de dados fornece uma base sólida para a sua investigação.
Os query logs do Arquivo.pt são recursos únicos para investigação
O Arquivo.pt disponibiliza um serviço “tipo Google” (Google-like) que permite pesquisar páginas e imagens recolhidas da web desde a década de 1990. Note-se que a pesquisa do Arquivo.pt complementa os motores de busca da web, uma vez que permite a pesquisa temporal de informação que já não se encontra disponível online nos seus sítios originais.
A análise do comportamento dos utilizadores é um importante tópico de investigação para compreender as suas necessidades de informação e melhorar a qualidade dos resultados de pesquisa. Assim, quando um utilizador interage com um motor de pesquisa, este regista as acções do utilizador num ficheiro denominado query log (registo de pesquisas). Os query logs sobre arquivos da Web são recursos únicos para a investigação porque descrevem as necessidades reais dos utilizadores de arquivos da Web sobre informações históricas que foram publicadas em linha.
Estudo de caso
Flavie Gallois e Adam Jatowt, da Universidade de Innsbruck, e Ricardo Campos, da Universidade da Beira Interior e do INESC TEC, analisaram o comportamento de pesquisa dos utilizadores com base no conjunto de dados de pesquisas do Arquivo.pt recolhidos durante um período de 3 meses, entre junho e setembro de 2021 (Analyzing User Search Behaviour in Temporal Web Repositories through Search Query Log Analysis).
Este estudo analisou as características das pesquisas, como o comprimento, o tipo ou a frequência, e comparou os resultados obtidos com trabalhos anteriores sobre o comportamento de pesquisa dos utilizadores em arquivos da Web e em motores de pesquisa da Web em tempo real.
O estudo revelou tendências e padrões fundamentais sobre o modo como os utilizadores procuram informações nos arquivos da Web, o que motiva a realização de mais trabalhos de investigação.
Como é que os utilizadores de arquivos Web pesquisam?
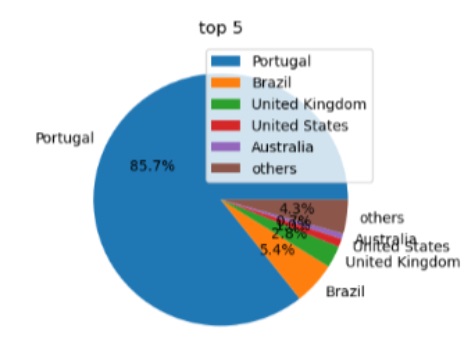
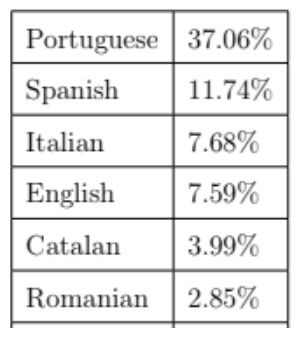
Figura 1 : Distribuição por país de origem dos utilizadoresFigura 2: Distribuição por língua utilizadas nas pesquisas
Os utilizadores eram de Portugal em 85,7% das pesquisas. No entanto, a língua portuguesa foi identificada através da identificação automática da língua das pesquisas como sendo utilizada em apenas 37% das pesquisas. Isto sugere que os utilizadores utilizam outras línguas que não a sua para pesquisar em arquivos Web.
Os utilizadores do Arquivo.pt tendem a utilizar queries mais longas, com mais palavras e caracteres, em comparação com estudos anteriores, tanto em arquivos da web como em motores de busca live-web. Cerca de 92% das pesquisas tinham 5 ou menos termos (média de 25 caracteres), sendo 3 o número mais comum de termos submetidos. No trabalho anterior sobre o comportamento de pesquisa em arquivos da Web, observou-se que os utilizadores tendiam a submeter de 1 a 3 termos por pesquisa, sendo 1 termo a submissão mais comum.
Os utilizadores tendem a fazer várias consultas numa sessão, em vez de uma única pesquisa, o que pode indicar a necessidade de aperfeiçoar as suas consultas de pesquisa ou de explorar várias opções de pesquisa
87,7% das pesquisas submetidas ao Arquivo.pt utilizaram browsers de desktop (computadores de secretária), apesar de o Arquivo.pt disponibilizar interfaces de utilizador amigáveis para telemóveis, as páginas antigas arquivadas na web não são responsivas e são mal renderizadas em dispositivos móveis. Assim, é expetável que os utilizadores utilizem maioritariamente os arquivos web através dos seus desktops.
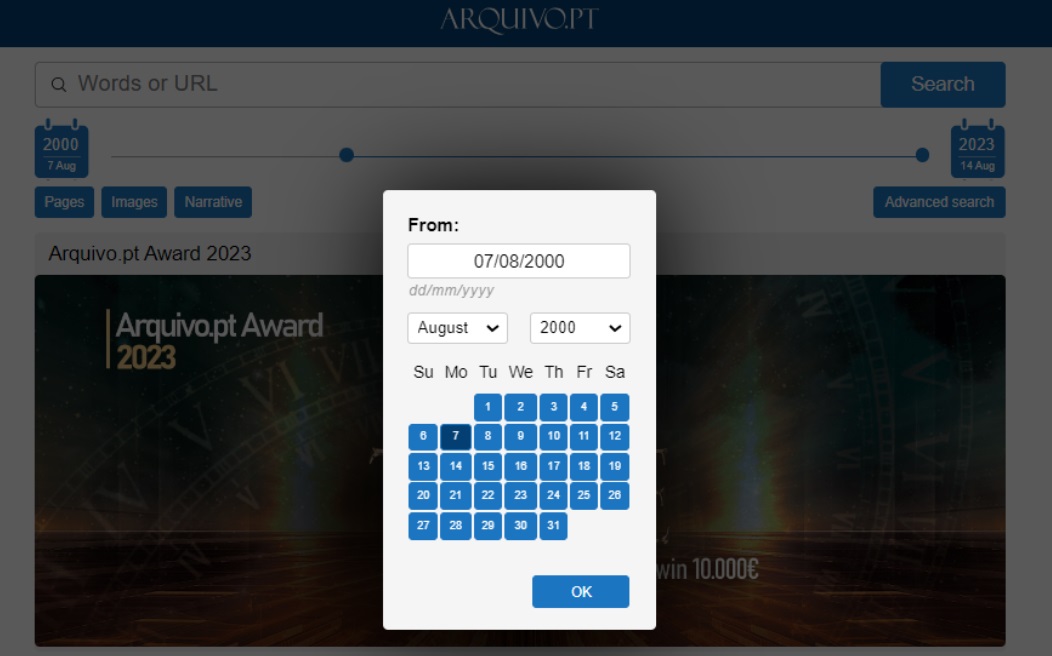
Figura 3: Os utilizadores do Arquivo.pt podem refinar o período de tempo das suas pesquisas utilizando os selectores de data “De” e “Até” (From and To).
Os utilizadores refinaram o período de tempo da pesquisa (utilizando os marcadores de data) em cerca de 50% das pesquisas, o que indica uma consciência das necessidades temporais próprias da utilização de arquivos Web. Curiosamente, os utilizadores modificaram o seletor de data “De” com mais frequência do que o seletor de data “Até”. Note-se que a manutenção do período de tempo predefinido pode corresponder às necessidades de informação do utilizador e não indica necessariamente a falta de conhecimento da existência da função de definição do período de tempo (própria da pesquisa em arquivos Web).
Apenas uma pequena percentagem de utilizadores incluiu anos específicos nos seus termos de pesquisa (4%), o que pode sugerir que a função de intervalo de tempo foi insuficiente ou passou despercebida a alguns utilizadores.
Os resultados obtidos sugerem que os utilizadores estão mais conscientes das suas necessidades de informação e que melhoraram as suas técnicas de pesquisa para serem mais eficazes nos arquivos Web, em vez de os utilizarem apenas por curiosidade, como primeiros utilizadores.
O que é procurado num arquivo Web?
Os autores do estudo aplicaram o reconhecimento automático de entidades (automatic entity recognition) sobre as pesquisas dos utilizadores e obtiveram um conjunto de nuvens de palavras que fornecem graficamente uma ideia das necessidades de informação mais comuns dos utilizadores do Arquivo.pt:
Figura 4: Nuvem de palavras dos termos de pesquisa mais frequentes submetidos ao Arquivo.pt.Figura 6: As localizações geográficas mais frequentes nos termos de pesquisa submetidos ao Arquivo.pt.
Figura 6: As organizações mais frequentes nos termos de pesquisa submetidos ao Arquivo.pt.
Figura 7: As pessoas mais frequentes nos termos de consulta submetidos ao Arquivo.pt.
Acesso ao dados das pesquisas no Arquivo.pt (query dataset)
O Arquivo.pt lançou um conjunto de recursos para apoiar estudos de investigação sobre as pesquisas dos utilizadores (query dataset):
Query_Dataset_Sample.csv: tabela que contém uma amostra das pesquisas (sample of the dataset query).
Query_Dataset_ArquivoPT.7z (in UTF-8): este ficheiro corresponde ao conjunto completo de dados de pesquisas disponíveis para investigação, recolhidos durante um período de 3 meses, de junho a setembro de 2021. Aconselhamos a ter cuidado ao abrir o ficheiro, porque alguns leitores, como o Microsoft Excel, podem utilizar o conjunto de caracteres errado e danificar o conteúdo, por exemplo, da coluna L “QUERY”.
Métricas de avaliação para pesquisa em arquivos Web
O primeiro passo para compreender o comportamento do utilizador é definir métricas de avaliação. A definição de métricas é uma ferramenta poderosa para estabelecer objectivos a longo e a curto prazo para decidir que novos produtos e funcionalidades devem ser lançados aos utilizadores.
Partilhamos um relatório de trabalho em curso que agrega informações sobre as métricas de avaliação da pesquisa em arquivos da Web: Web Archive Search Evaluation Metrics . Isto contribui para comparar o comportamento de pesquisa dos utilizadores entre os motores de pesquisa da Web em direto e os dos arquivos da Web. Não hesite em comentar diretamente o documento colaborativo ou em contactar-nos.
Este relatório fornece também um resumo de referências sobre trabalhos anteriores, fluxos de pesquisa e estrutura dos correspondentes registos de pesquisa produzidos pelo Arquivo.pt, para facilitar o trabalho dos investigadores no estudo destes conjuntos de dados.
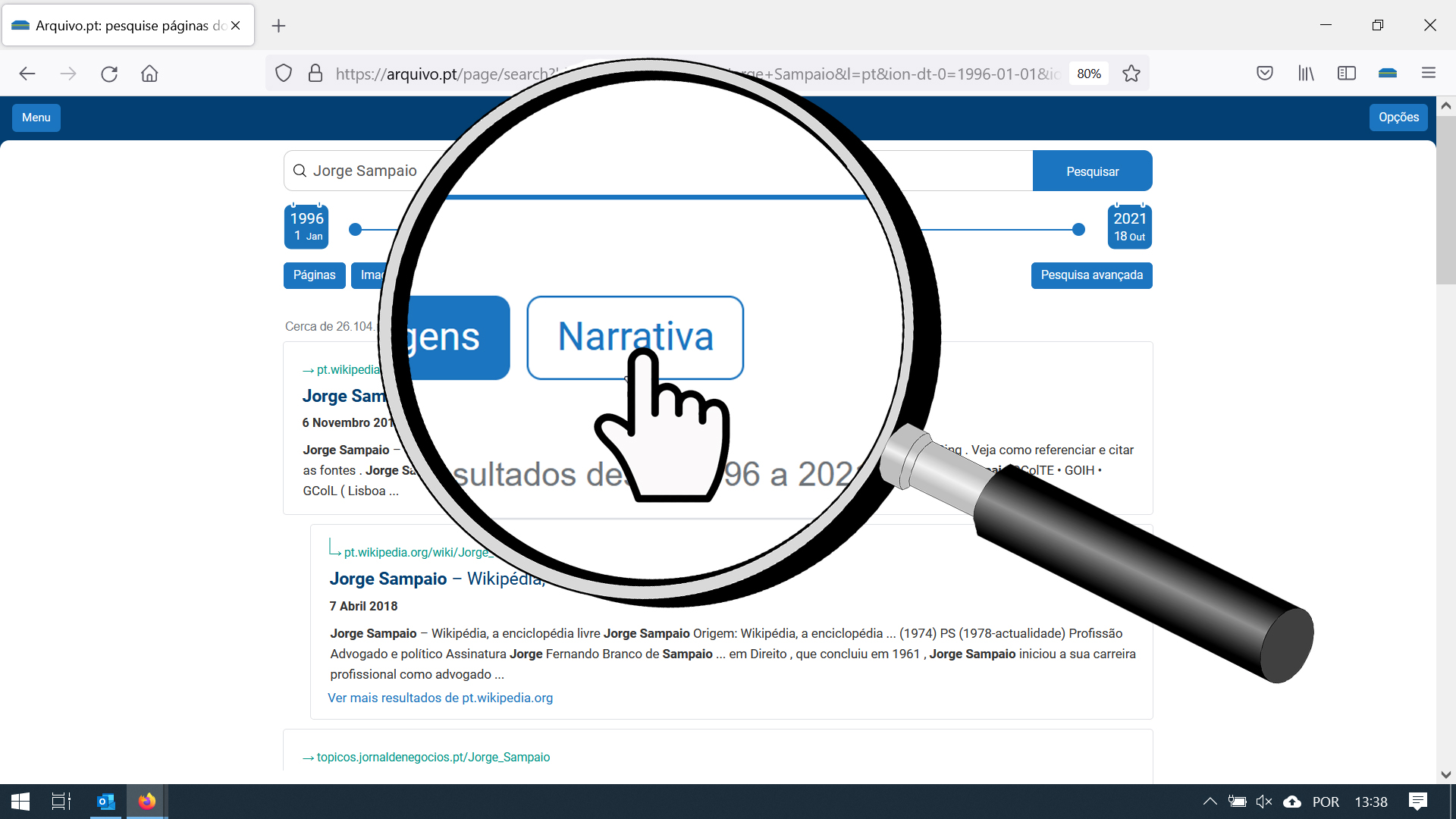
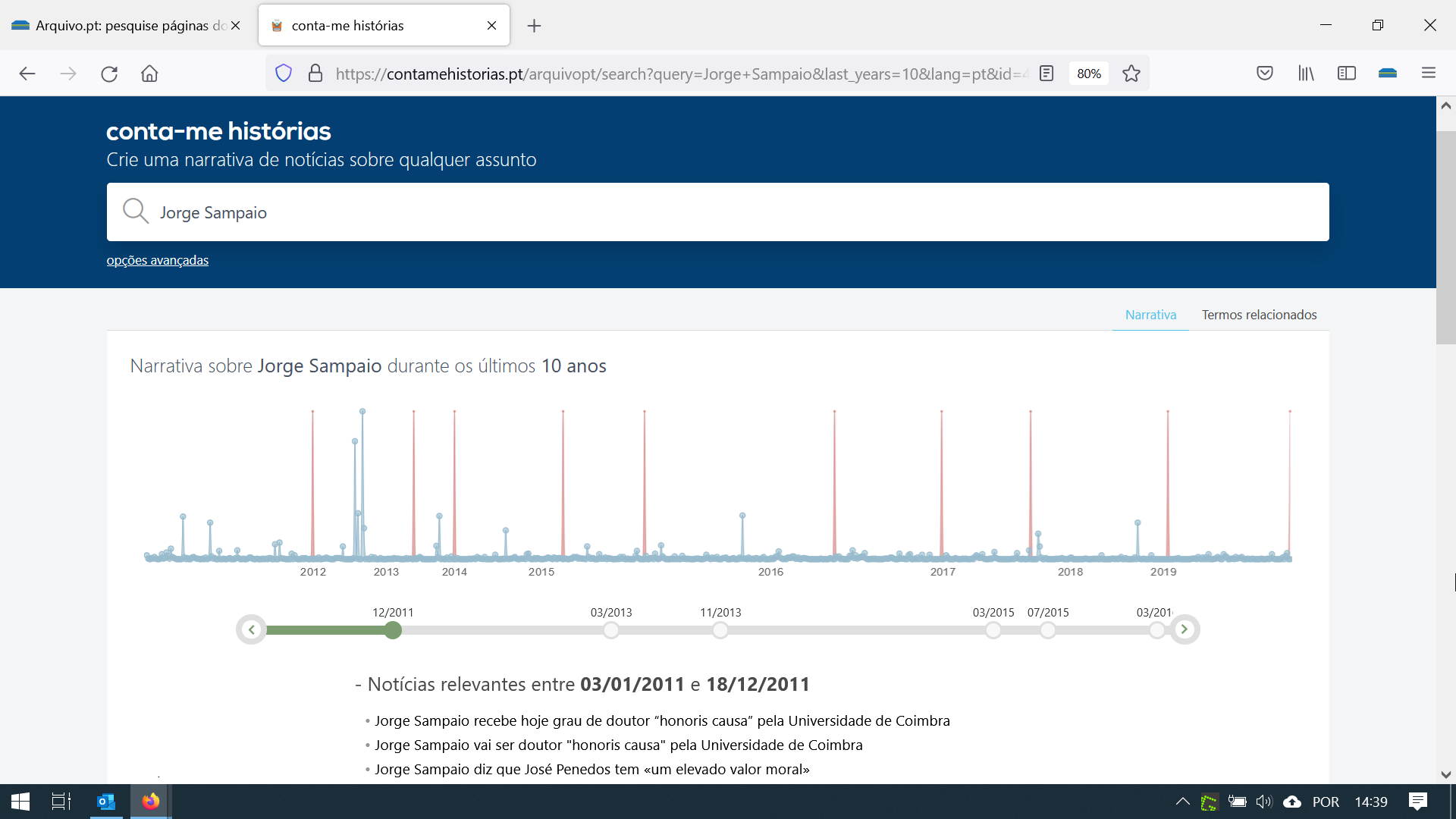
Quando um utilizador insere um conjunto de palavras acerca de um tema na caixa de pesquisa do Arquivo.pt e clica no botão “Narrativa”, é direcionado para o serviço “Conta-me Histórias”, que por sua vez analisa automaticamente as notícias de 25 websites arquivados pelo Arquivo.pt ao longo do tempo e apresenta ao utilizador uma cronologia de notícias relacionadas com o tema pesquisado.
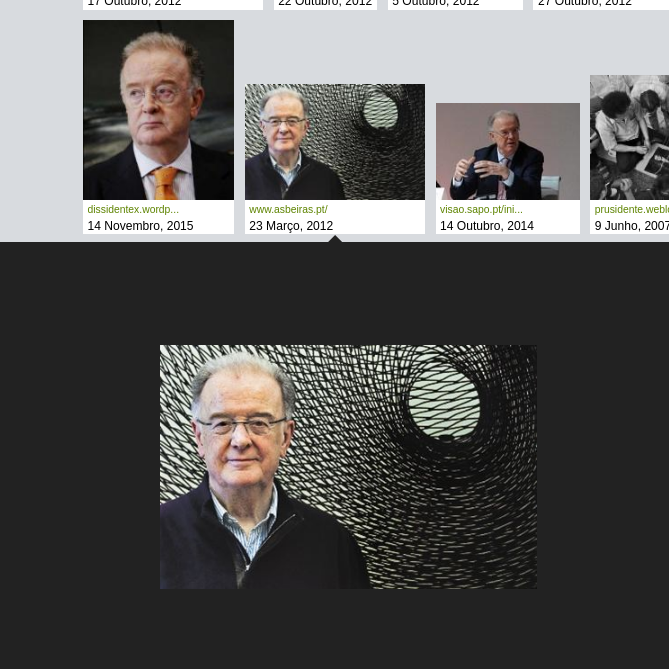
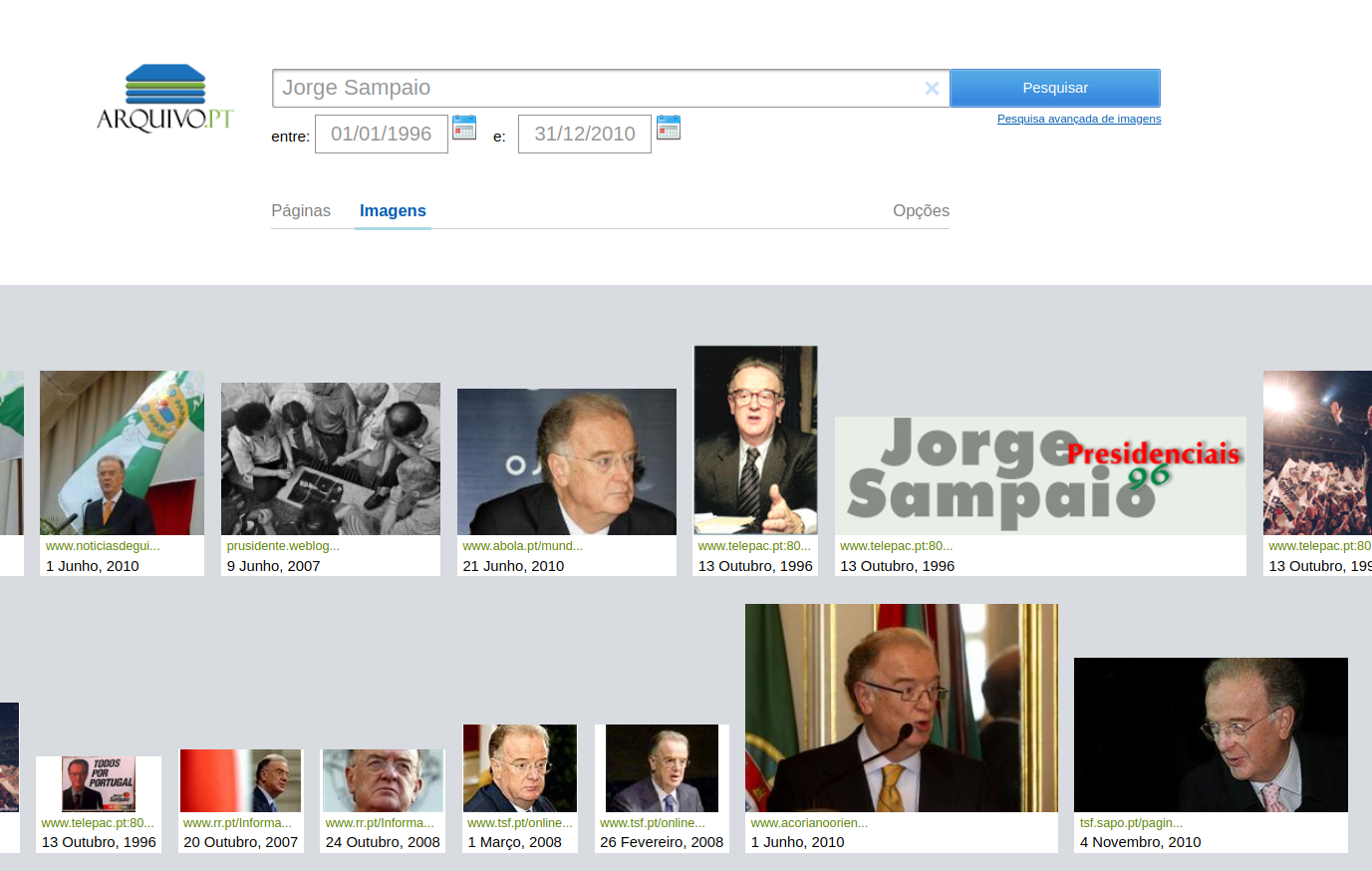
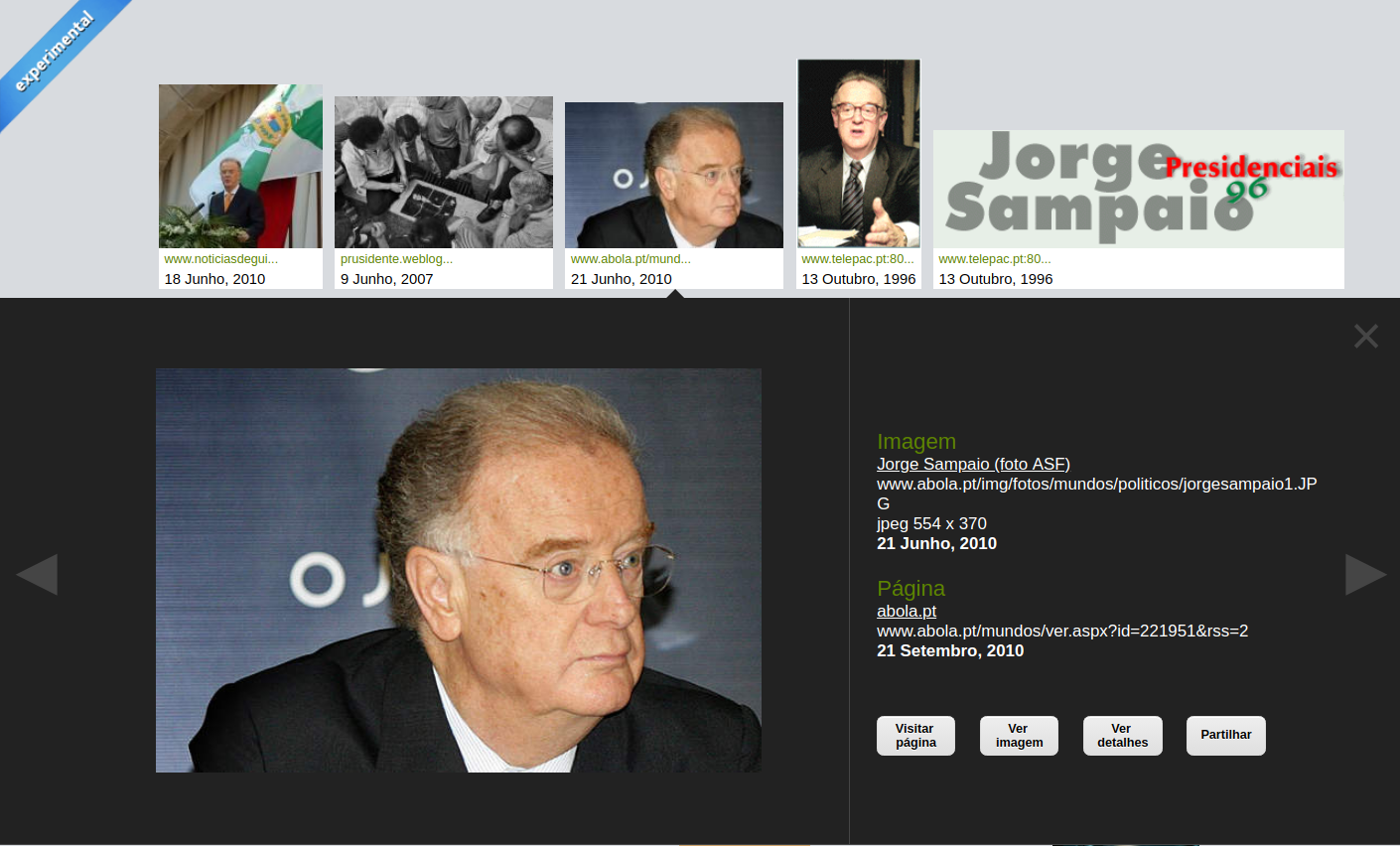
Figura 1: Resultados da pesquisa de páginas sobre “Jorge Sampaio”.
Figura 2: Narrativa de notícias sobre “Jorge Sampaio” gerada pelo serviço “Conta-me Histórias”.
Crie agora a sua narrativa!
O “Conta-me Histórias” pesquisa, analisa e agrega milhares de resultados para gerar cada narrativa acerca de um tema. Recomenda-se a escolha de palavras descritivas sobre temas bem definidos, personalidades ou eventos para obter boas narrativas.
A criação de uma narrativa é útil para investigadores, jornalistas ou cidadãos que pretendam obter rapidamente uma visão geral acerca da evolução de um tema ao longo do tempo, poupando-lhes assim imenso tempo e trabalho.
Aceda ao Arquivo.pt e experimente criar uma narrativa sobre um tema à sua escolha.
Última atualização em 31 de Janeiro de 2019 às 10:57
O Projeto CLEOPATRA está com 15 vagas abertas para Early Stage Researcher (PhD) com financiamento integral. Os assuntos vão de Web Semântica, processamento de linguagem natural, humanidades digitais até ciências sociais.
O Arquivo.pt está diretamente envolvido em três dos cursos: Incentives design for hybrid multilingual information processing and analytics, em Southampton; National and transnational media coverage of European parliamentary elections, 2004-2014, Londres (ambos nos Reino Unido); e NLP for under-resourced languages, em Zagreb, na Croácia.
Última atualização em 6 de Agosto de 2024 às 17:27
Depois do grande sucesso na 1ª edição, o Prémio Arquivo.pt abrirá novamente caminho para trabalhos que utilizem, de forma útil e inovadora, a informação web do passado.
Serão 15 000€ em prémios:
1º classificado: 10 000 €
2º classificado: 3 000 €
3º classificado: 2 000 €
As propostas distinguidas, individuais ou em grupo, serão as que melhor promovam a utilização da informação web preservada no Arquivo.pt.
As candidaturas podem conter projetos de investigação que utilizem os recursos do Arquivo.pt ou descobertas de aplicações úteis para a sociedade.
O regulamento será divulgado em breve e as candidaturas abrirão no início de 2019.
Vencedores da 1ª edição (Prémio Arquivo.pt 2018)
O grande vencedor da 1ª edição do Prémio Arquivo.pt foi o projeto Conta-me Histórias, liderado por Ricardo Campos, investigador do INESC TEC e docente do Instituto Politécnico de Tomar (IPT). A plataforma oferece uma narrativa temporal a partir das notícias publicadas online sobre um determinado tema.
“um importante impulso para o projeto e graças a esta distinção poderão decorrer outros trabalhos de investigação ou, inclusivamente, surgir aplicações a nível comercial”.