Última atualização em 4 de Dezembro de 2025 às 13:12
O “Café com o Arquivo.pt” consiste em sessões online curtas para permitir a qualquer pessoa assistir em horário laboral. Tem por objetivo dar a conhecer o Arquivo.pt e trazer contributos da comunidade sobre temas relacionados com a preservação da Web.
Em dezembro de 2025, iniciou-se uma nova série dedicada às coleções temáticas que o Arquivo.pt publica sob a forma de conjuntos de dados na plataforma Dados.Gov.
Por exemplo, websites relacionados com o teatro, a música, as escolas, as freguesias, as eleições e outros temas, encontram-se preservados no Arquivo.pt. Nas sessões temáticas do Café com o Arquivo.pt vamos dar visibilidade a conjuntos de websites cujo histórico se encontra no arquivo da Web.
Cada sessão é dedicada a um tema e tem um convidado que fala da sua instituição ou do seu projeto e comenta o tema do dia.
Série coleções temáticas
1ª sessão – Eleições Autárquicas: como arquivamos websites e programas eleitorais
Convidados: Mário Rui André e Gonçalo Pereira Costa – Jornal LPP / Lisboa Para Pessoas
Os convidados, Mário Rui André e Gonçalo Pereira Costa, do jornal LPP / Lisboa Para Pessoas, falaram-nos do Portal das Autárquicas da Lisboa Metropolitana que criaram, onde se encontra informação sobre os candidatos e os seus programas eleitorais. O Arquivo.pt recolheu milhares de páginas e websites eleitorais, mais de 3 terabytes de informação, e explicou brevemente a metodologia utilizada.
Ao percorrer o vídeo da sessão vai saber:
Como foram as autárquicas na Área Metropolitana de Lisboa numa perspetiva jornalística;
Qual foi a metodologia seguida para recolher conteúdos eleitorais na Internet;
Como usar o arquivo da web para obter informação do passado.
O Arquivo.pt esteve presente na 6a Conferência RESAW para investigadores das Humanidades Digitais, Media e Comunicação e outras áreas, subordinado ao tema “The Datafied Web”, que teve lugar na Universidade de Siegen, Alemanha, de 4 a 6 de junho de 2025.
Inicialmente, o RESAW reunia investigadores europeus, mas agora congrega investigadores de todo o mundo, tendo-se tornado num fórum único no seu género. Em 2025, contou com mais de 100 participantes. Ali se encontra o que de melhor se faz no domínio utilização de arquivos da Web em contexto de investigação.
Niels Brügger, Professor de Media e Comunicação da Universidade de Aahrus, Dinamarca, tem sido o principal impulsionador do RESAW, ao longo de 10 anos.
Destacam-se ainda nomes de investigadores de referência com estudos desenvolvidos no âmbito dos arquivos da Web: : Valerie Schafer, da Universidade do Luxumburgo, Jane Winters, da Universidade de Londres, Anne Helmond, da Universidade de Utrecht, Susan Aasman da Universidade de Groningen, Sophie Gebeil, da Universidade de Aix-Marseille e Ian Millingan da Universidade de Waterloo.
O tema deste ano The Datafied Web abordou a questão da datificação da Web, desde os seus inícios na década de 1990 à atualidade, marcada pelo processamento massivo de dados e pelo uso da Inteligência Artificial.
Porquê a participação de um arquivo da Web num encontro de cariz académico?
O Arquivo.pt participa regulamente no RESAW desde 2019, pois quer dar-se a conhecer cada vez mais como um serviço destinado aos investigadores nacionais e internacionais.
Graças à participação em eventos internacionais como o RESAW, surgiram várias publicações que usam e referem o Arquivo.pt. Qualquer investigador com acesso à Internet pode pesquisar a informação preservada no Arquivo.pt, usar as APIs, processar informação ou treinar os seus modelos.
Convidamos os investigadores portugueses a participarem neste encontro, pois temos sido a única presença portuguesa em várias edições. Temos um arquivo da Web acessível, pronto a utilizar, o que não acontece em outros países. Gostaríamos de ter investigadores de áreas das Humanidades Digitais e Media e Comunicação em Portugal a usarem mais frequentemente o Arquivo.pt e a participarem ativamente em encontros como o RESAW.
Contributo do Arquivo.pt no RESAW 2025
O Arquivo.pt contribuiu com duas apresentações na edição de 2025 de encontro RESAW, realizado na Universidade de Siegen. A primeira acerca das APIs do Arquivo.pt e da sua aplicação em contexto de investigação, por Vasco Rato. A segunda sobre os conjuntos de dados abertos e listas de sites sobre temas e eventos que o Arquivo.pt preparou para ajudar os investigadores a iniciarem uma exploração mais profunda da informação arquivada.
Este Ciclo de Webinars, dedicado à preservação da memória cultural publicada na Web, é uma colaboração entre a APDSI e o Arquivo.pt, FCCN serviços digitais da Fundação para a Ciência e a Tecnologia I.P..
Luís Vidigal, Sócio Fundador da APDSI, Filipa Fixe e João Tavares, Vogais da Direção, introduziram o tema de cada sessão e a equipa do Arquivo.pt mostrou como funciona a preservação de conteúdos Web que permite às organizações e aos cidadãos acederem à web do passado.
As quatro sessões tiveram um total de 121 participantes.
Programa
Webinar 1 – 20 de março – Arquivo.pt: uma nova ferramenta para pesquisar o
passado. Daniel Gomes, Gestor do Arquivo.pt – Vídeo, slides
Webinar 2 – 25 de março – Bem publicar para bem preservar. Pedro Gomes,
Encarregado pelas recolhas do Arquivo.pt – Vídeo, slides
Webinar 3 – 27 de março – Acesso e processamento automático de informação
preservada da Web através de APIs. Vasco Rato, Web developer do Arquivo.pt – Vídeo, slides
Webinar 4 – 1 de abril – Arquivar a Web: faça-você-mesmo!. Ricardo Basílio, Vídeo, slides
Curador digital do Arquivo.pt
Última atualização em 11 de Março de 2025 às 16:21
Professor Doutor José Borbinha, workshop eArchiving, a 25 de Fevereiro de 2025, no Instituto Superior Técnico em Lisboa (Sala José Tribolet)
O Arquivo.pt participou no workshop eArchiving Portugal , que se realizou no Instituto Superior Técnico, no dia 25 de fevereiro de 2025, a convite do Professor Doutor José Borbinha, uma das primeiras pessoas a fazer arquivo da web em Portugal quando, na década de 1990, estava na Biblioteca Nacional.
O Professor José Borbinha, melhor que ninguém, sabe contar na primeira pessoa os pequenos episódios, quase épicos, as ações dos primeiros “heróis” que levaram à criação de um arquivo da Web em Portugal. Vê o Arquivo.pt como um serviço imprescindível quando se fala de preservação digital e de salvaguarda do património comunicacional das organizações.
O evento teve um formato hibrido com 50 participantes presencias e 270 online e foi aberto a todas as entidades públicas ou privadas com preocupações ao nível da preservação digital e gestão da informação em qualquer tipo ou formato. Aqui se incluem os conteúdos dos websites e redes sociais!
Os responsáveis dos Municípios, entidades da Administração Local, tiveram uma grande participação, respondendo ao apelo da Direção-Geral do Livro, dos Arquivos e das Bibliotecas (DGLAB). Este convite à participação de pessoas de todo o país foi uma oportunidade para o Arquivo.pt mostrar como pode ajudar na preservação dos sites institucionais e no cumprimento da Portaria n.º 112/2023, de 27 de abril.
eArchiving, uma iniciativa europeia nascida em Portugal
“Foi precisamente nesta (sala José Tribolet no Instituto Superior Técnico) que teve início o eArchiving há onze atrás, a 29 de maio de 2014” recordou José Borbinha (INESC-ID), anfitrião e organizador do workshop.
Janet Anderson, gestora do eArchiving, mostrou os progressos alcançados em onze anos no domínio da preservação digital. Os projetos financiados pela União Europeia no âmbito do consórcio resultaram no desenvolvimento de especificações, software, formação e conhecimento sobre preservação digital.
Seguiu-se a apresentação de contributos para a preservação digital em Portugal: DGLAB, por Pedro Penteado, Centro Hospitalar São João, por Fernanda Gonçalves, Ministério da Justiça, por Alexandra Lourenço e Cristina Soares, Arquivo.pt, pelo curador digital Ricardo Basílio.
Para terminar, Miguel Ferreira fez a sua intervenção em representação do DLM Forum MTÜ, comunidade onde a KEEP Solutions LDA participa com o desenvolvimento de software. Numa abordagem mais técnica mostrou como estão estruturados os metadados na especificação de empacotamento E-Ark de modo a cumprirem os requisitos da preservação digital.
Como usar o Arquivo.pt para preservação os websites institucionais
Apresentação do Arquivo.pt no Workshop eArchiving por Ricardo Basílio, curador digital. Foto por Pedro Penteado
A preservação digital exige colaboração, tanto ao nível interno como externo entre organizações, e este workshop serviu esse propósito, pois foi ocasião para partilha de boas práticas, divulgação de ferramentas e serviços e contacto entre pessoas.
Da parte do Arquivo.pt destacou-se três serviços do seu catálogo para a preservação dos conteúdos publicados na web:
Os serviços do Arquivo.pt podem ser utilizados, por exemplo, pelos Municípios para a preservação dos conteúdos publicados nos websites institucionais.
A formação do Arquivo.pt, tais como webinars ou sessões presenciais, são úteis para dar capacidade às entidades para cuidarem dos conteúdos institucionais, incluindo os conteúdos das redes sociais que exigem uma estratégia alternativa.
O Arquivo.pt contribuiu para a coleção internacional de páginas Web sobre os Jogos Olímpicos, que decorreram em Paris de 26 de julho a 11 de agosto de 2024, e os Jogos Paralímpicos que se realizaram de 28 de agosto a 8 de setembro.
No Arquivo.pt também ficarão disponíveis, passado um ano, as páginas desta coleção para quem quiser realizar estudos sobre desporto e olimpismo.
Como foram selecionadas as páginas sobre os atletas portugueses
Nos Jogos Olímpícos representaram Portugal 73 atletas em 15 modalidades, e nos Jogos Paralímpicos 27 atletas, em 10 modalidades.
O critério de seleção de páginas para a coleção internacional foram notícias sobre os atletas. Para cada atleta selecionou-se páginas referentes às suas expectativas antes dos jogos, à sua prestação na prova e aos seus comentários durante e após a competição.
Há atletas que têm mais notícias selecionadas do que outros e o mesmo acontece com os sites de onde provêm as notícias. A seleção de páginas não se limitou aos primeiros resultados apresentados pelo motor de busca. Procurou-se variedade de canais e notícias de sites regionais e locais, alguns da região ou cidade de onde vieram os atletas.
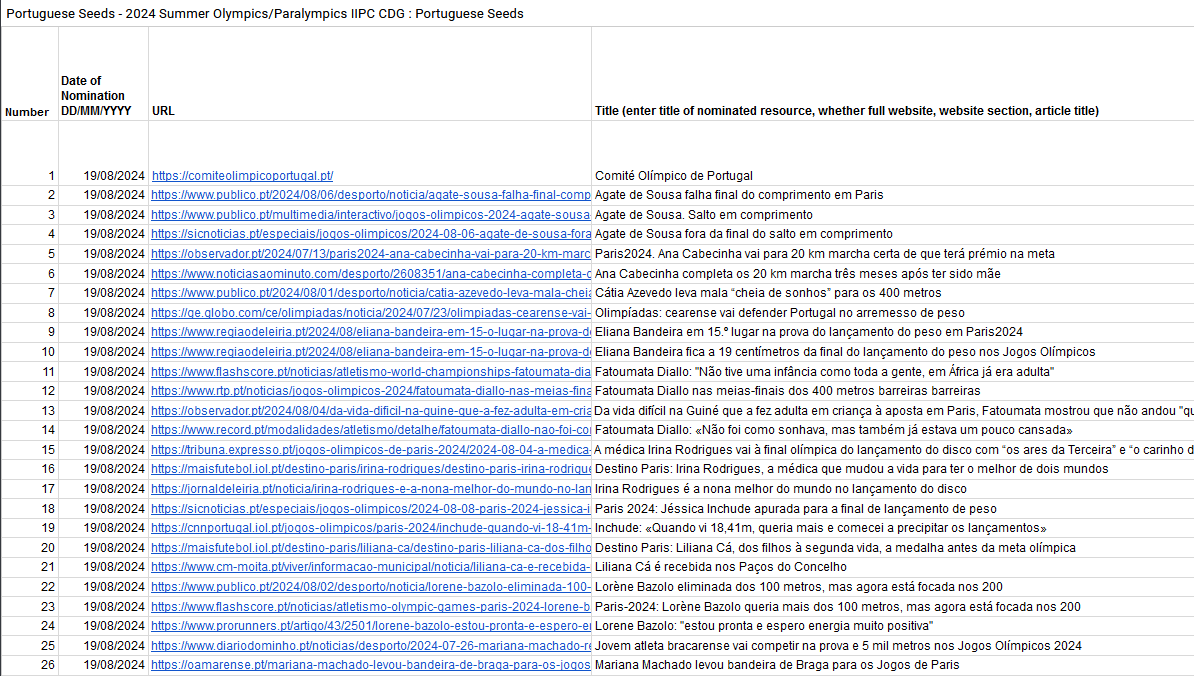
Mais de 500 páginas para recordar a presença portuguesa em Paris
O contributo do Arquivo.pt, como poderá ver na tabela, já tem mais de 500 paginas Web.
Arquivo.pt operado pela FCCN FCT, localizado no Campus do LNEC, na Avenida do Brasil, em Lisboa.
No dia 24 de maio, a FCCN recebeu pela primeira vez profissionais de Bibliotecas do Ensino Superior (BES) no âmbito do programa dinamizado pelo Grupo Trabalho das Bibliotecas do Ensino Superior (GT-BES) da Associação Portuguesa de Bibliotecários, Arquivistas, Documentalistas e Profissionais da Informação (BAD), A minha biblioteca é a tua biblioteca.
Trata-se de um programa de mobilidade que tem como objetivo a realização de visitas de curta duração tendo em vista a troca de experiências e o contacto, in loco e hands on, com boas práticas, fomentando a colaboração e o conhecimento das BES portuguesas entre os profissionais da área.
Serviços avançados para o conhecimento
Nesta primeira edição do programa na FCCN, foi proposto às colegas participantes (3 profissionais da Universidade de Lisboa e 1 da Universidade Católica do Porto) um percurso pelos serviços digitais de apoio às instituições do ensino superior que são operados pela FCCN- FCT
Alguns serviços são conhecidos dos profissionais da informação, como por exemplo, a B-On e o RCAAP. Outros são serviços de backoffice e, por isso, menos visíveis, mas fundamentais para as instituições de ensino superior. Por exemplo, o Eduroam que garante o acesso à Internet, o RCTSaai para a autenticação ou o RCTS CERT para responder a incidentes de segurança.
Destaque para os serviços Arquivo.pt e NAU
No decorrer dia, estiveram em destaque o Arquivo.pt e a Plataforma NAU, dois serviços da área do conhecimento que estão disponíveis para as Instituições do Ensino Superior e também para a sociedade.
A equipa do Arquivo.pt mostrou o backoffice deste serviço de preservação da Internet em Portugal e realizou um exercício prático de gravação e integração de conteúdos no arquivo da Web.
A Plataforma NAU, é uma plataforma de MOOCs (Massive Open Online Courses) criada com o propósito de democratizar o conhecimento, promover a literacia digital, possibilitar o ensino e formação a comunidades alargadas de utilizadores, em particular à população portuguesa e lusófona.
Mais recentemente, com a sua integração na plataforma norte-americana edx.org, também a todos os potenciais formandos falantes de língua portuguesa dispersos pelo mundo. Às participantes no programa foi explicado e exemplificado como construir cum curso MOOC na plataforma edx.
Por: Marie Haškovcová and Luboš Svoboda, Webarchiv, National Library of the Czech Republic, 13 a 17 de maio de 2024.
Visita no âmbito do Erasmus+
Graças ao programa europeu Erasmus+ da UE, centrado na educação de adultos – mobilidade de pessoal, tivemos a oportunidade de passar uma semana a acompanhar o Arquivo.pt e comparar as estratégias do arquivo Web checo – Webarchiv – com as abordagens dos nossos colegas portugueses.
Em ambos os casos, trata-se de arquivos centrados em conteúdos nacionais (checos e portugueses) na Internet.
A FCT presta serviços de IT ao sistema de ensino superior e de Investigação português, bem como conetividade de alta velocidade à Internet. O contexto institucional de ambos os arquivos reflecte-se também nas especificidades dos seus conceitos.
A visita incluiu uma apresentação da equipa e dos espaços do campus e dos departamentos, uma apresentação das actividades de ambos os arquivos e uma discussão sobre os diferentes aspectos do nosso trabalho – ferramentas técnicas e curatoriais, tecnologias e processos, ambiente legislativo e questões éticas, armazenamento de dados, alguns serviços, actividades de investigação, perspectivas e planos futuros.
O arquivo da Web checo
O arquivo web checo foi fundado em 2000, as cópias de arquivo mais antigas datam de 2001 e tem atualmente mais de 580 TB de dados. Tal como o Arquivo.pt, recolhe conteúdos num domínio nacional com base numa lista de endereços URL obtida junto do seu fornecedor. Na sua estratégia de aquisição, complementa estas recolhas, ditas abrangentes, com recolhas temáticas e selectivas.
As colecções temáticas referem-se a um tópico ou evento específico, podem ser pontuais ou de construção contínua, e combinam recursos seleccionados manualmente e recursos extraídos automaticamente. As colecções selectivas destinam-se a ser recolhidas a longo prazo, têm registos de catalogação detalhados que fazem parte da bibliografia nacional checa e são licenciadas – as cópias de arquivo estão, portanto, disponíveis gratuitamente através do catálogo.
No âmbito das actividades de investigação em arquivos da Web, apresentámos o nosso projeto destinado a detetar as chamada web morta através da aplicação Extinct Websites e a criar uma base de dados que sirva de base para monitorizar mudanças mais amplas na web checa, bem como o projeto WACloud destinado a extrair grandes volumes de dados do arquivo da web.
Troca de conhecimentos e experiências
Entre os projectos portugueses, interessou-nos, por exemplo, o CitationSaver, e também discutimos o projeto Memorial, a recolha da Wikipédia portuguesa, e as actividades do arquivo português relacionadas com a formação sobre a preservação da Web (módulos de formação).
A reunião foi enriquecida pela discussão de colecções temáticas específicas.
A coleção de Net Art checa documenta a arte digital e a sua transformação no espaço em linha, proporcionando uma perspetiva histórica da arte única.
Outra coleção importante é a coleção “Redes sociais dos Membros do Parlamento da República Checa 2021-2025”, que preserva as comunicações e interacções em linha dos deputados checos, de valor inestimável para o estudo do marketing político e da vida política pública.
A coleção GitHub arquiva repositórios importantes desta popular plataforma para programadores, preservando os principais projectos de software nacionais e o seu código para as gerações futuras.
Por último, a coleção Crypto, NFT, Blockchain, Web3, Metaverse traça o crescimento e o impacto da tecnologia no espaço dos bens digitais. Estas colecções são recursos fundamentais para a investigação e análise da cultura, política e tecnologia digitais, e a discussão destas colecções em reuniões de arquivistas da Web contribui para o desenvolvimento de métodos de arquivo e inovação tecnológica.
Concentrámo-nos na troca de conhecimentos e experiências na identificação de endereços para gravar (seeds), na otimização do fluxo de trabalho e na partilha de dicas e aspectos técnicos.
Partilha de boas práticas
Discutimos as melhores práticas para identificar e recolher os principais recursos da Web, um passo fundamental para garantir um arquivo abrangente e representativo. Partilhámos várias estratégias para automatizar e simplificar os fluxos de trabalho, incluindo a utilização de ferramentas de raspagem da Web e filtragem avançada de conteúdos.
As conversas técnicas incluíram soluções para problemas comuns, como a recolha de páginas Web dinâmicas e a superação de restrições de acesso. A reunião constituiu uma plataforma valiosa para a partilha de métodos inovadores e para a promoção da colaboração entre peritos, promovendo o desenvolvimento de um arquivo digital eficaz e sustentável.
Luboš Svoboda, curador digital, Marie Haškovcová,coordenadora do Webarchiv e Ricardo Basílio, curador digital do Arquivo.pt em visita ao Estúdio da FCCN, FCT.
O dia 18 de maio, Dia Internacional dos Museus, foi assinalado por todo o país com entradas gratuitas, visitas guiadas, animação de espaços e exposições relacionadas com a memória e o património.
O Arquivo.pt contribuiu com uma exposição de páginas antigas, intitulada “Memória Digital através da Internet do Passado”, que esteve patente num dos stands no Museu dos Coches, em Lisboa.
As páginas foram selecionadas para mostrar diversos aspetos do Alentejo ao longo do tempo. A partir de 2016, selecionou-se páginas relativas ao projeto Heritales.
Heritales e Crowd-Recycling chamaram a atenção para a preservação da memória da Internet
Heritales é um projeto sediado em Évora que tem por objetivo estudar e divulgar o património em todas as suas manifestações. É conhecido pelo seu evento principal criado em 2016, o HERITALES – International Heritage Film Festival.
Crowd-Recycling é um projeto focado nas boas práticas para a sustentabilidade.
O Heritales, o Crowd-Recycling e o Arquivo.pt concretizaram esta ação em colaboração com o objetivo de dar visibilidade aos conteúdos publicados na Web ao longo do tempo. Preservar e dar acesso aos conteúdos digitais é fundamental para valorizar o património.
Porque é que fazer uma exposição de websites antigos é um boa ideia
Fazer uma exposição de websites ao longo do tempo é relativamente fácil, bastando ter um tema que pode ser também a história de uma instituição e escolher páginas conservadas no Arquivo.pt.
Uma exposição de sites antigos é uma ideia original para o público-alvo. Muitas vezes apresenta textos e imagens que só existiram na Web.
Ao chamar a atenção para os websites damo-nos conta que muitas coisas ficaram por gravar e isso muda a nossa visão sobre os conteúdos que publicamos hoje. Passados a cuidar mais da gravação de páginas importantes, por exemplo, tomando medidas ou gravando-as na hora com o SavePageNow.
Heritales, Crowd-Recycling e Arquivo.pt presentes no Dia Internacional dos Museus no Museu dos Coches
Dia Mundial da Internet foi a 17 de maio
No dia anterior ao Dia Internacional do Museus assinalou-se o Dia Mundial da Internet (17 de maio). A proximidade das duas comemorações vem mesmo a propósito do tema da preservação da memória.
Portugal ligou-se à Internet, pela primeira vez, em 1991, com o projeto da FCCN “Serviço IP da RCCN”.
Para relembrar como tudo aconteceu, deixamos-lhe as três sugestões que a FCCN publicou nas redes sociais para este dia:
As iniciativas foram as seguintes: uma viagem no tempo, uma recolha especial sobre o tema “25 de Abril”, uma comunicação no Congresso Internacional 50 anos de Abril e a inclusão de uma menção especial na edição de 2025 do Prémio Arquivo.pt.
Exposição “Memórias do 25 de Abril na Internet”
A exposição Memórias do 25 de Abril na Internet apresenta uma seleção de páginas Web sobre as comemorações do 25 de Abril em diversas regiões do país, desde o princípio da Web na década de 1990.
Os critérios para a escolha das páginas da exposição foram os seguintes:
Páginas relativas a comemorações do 25 de Abril;
Páginas encontradas no Arquivo.pt em datas próximas da efeméride, em cada ano;
Diversidade para incluir diversas zonas do país;
Manifestações populares e cerimónias oficiais.
Uma memória histórica sem os arquivos da Web é incompleta. Com esta viagem no tempo pretende-se convidar os cidadãos a viajarem no tempo, percorrendo páginas Web antigas e reavivando episódios recentes da nossa vida em democracia.
O conjunto de dados contém uma lista de palavras-chave colocadas num motor de busca a fim de obter resultados sobre o tópico “25 de Abril”. Na pesquisa considerou-se nomes de pessoas, lugares, aspetos políticos, sociais, culturais e ainda palavras associadas ao acontecimento.
As pesquisas foram realizadas no dia 22 de março de 2024 utilizando o Bing Search API, um serviço de pesquisa automática que devolve resultados de acordo com critérios de relevância do próprio serviço Bing e de outros configurados por nós.
No total foram obtidos 12.650 endereços únicos de páginas Web. Espera-se que a gravação destas páginas seja útil para as organizações que produziram esses conteúdos, para os investigadores que pretendem estudar a nossa história e para os cidadãos que cultivam o sentido da memória e da democracia.
Participação no Congresso Internacional 50 anos de Abril
João Gomes, Diretor Serviços Avançados, FCCN-FCT apresentando o serviço Memorial do Arquivo.pt no Congresso Internacional 50 anos de Abril
No dia 2 de maio de 2024, João Gomes, Diretor dos Serviços Avançados da FCCN Unidade de Computação Científica da Fundação para a Ciência e a Tecnologia I.P., apresentou o Arquivo.pt aos participantes do Congresso Internacional 50 anos de Abril, como um serviço distinto, aberto aos cidadãos e útil para as organizações.
O Arquivo.pt é um serviço de preservação da Web disponível para todos os cidadãos que pretendem pesquisar conteúdos antigos publicados na Web.
A utilização do Arquivo.pt contribui para uma melhor compreensão da nossa história. Além disso, fornece serviços úteis para a cibersegurança, como por exemplo o Memorial do Arquivo.pt que é capaz de manter os sites antigos das instituições, prevenindo ataques e poupando-lhes recursos.
Menção especial “O 25 de Abril e a Democracia” no Prémio Arquivo.pt 2025
O Prémio Arquivo.pt realiza-se anualmente e distingue trabalhos que utilizem o Arquivo.pt.
Em 2025, na continuação das comemorações dos 50 anos do 25 de Abril, será incluída uma menção especial a trabalhos sobre o tema “O 25 de Abril e a Democracia”.
Desafia-se pois os investigadores e cidadãos interessados a criarem trabalhos inovadores utilizando o Arquivo.pt.
Para questões relacionadas com o Prémio Arquivo.pt, contacte-nos.
Inteligência Artificial (IA), conhecida também pela sigla AI, de Artificial Intelligence, abrange várias áreas do conhecimento, tais como a linguística e a computação, e está presente nas novas tecnologias utilizadas no dia-a-dia pelos cidadãos.
Por exemplo, quando procuramos uma informação na Internet e o computador gera uma resposta espantosamente adequada, numa linguagem muito próxima da nossa.
O processamento da linguagem natural (PLN), correspondente em inglês a Natural Language Processing, NLP, é o que permite que as máquinas aperfeiçoem o algoritmo que gera essas respostas à medida dos utilizadores da Internet.
O problema é que os modelos de processamento de linguagem natural foram desenvolvidos mais para a língua inglesa e menos para língua portuguesa e outras com menos representação.
Quanto mais os modelos de processamento forem treinados sobre uma língua mais capazes serão de interpretar as complexidades da linguagem. Mas isso só é possível se tiverem dados de qualidade.
Acervo de texto em português no Arquivo.pt disponível para a investigação
O Arquivo.pt surge aqui como o maior conjunto de dados textuais em língua portuguesa de Portugal, disponível em acesso aberto, para os investigadores treinarem modelos de PLN.
Nos últimos anos foram os próprios investigadores, provenientes de vários grupos e projetos de investigação, que chamaram a atenção para a utilidade dos dados preservados da Web para processamento em larga escala.
O Arquivo.pt tem mais de 1 Petabyte de conteúdos preservados da Web, desde a década de 1990, onde se inclui tudo o que se pode encontrar nas páginas Web. Não se trata apenas de texto, mas também de imagens, ficheiros áudio, vídeo, o código das páginas e diversos metadados.
Os conteúdos estão acessíveis através da interface de pesquisa e das APIs do Arquivo.pt.
Um dos projetos que utilizou o Arquivo.pt para obter grande quantidade de texto denomina-se GlórIA e é um modelo de linguagem em larga escala (LLM, Large Language Model) focado na língua portuguesa europeia.