Last updated on October 1st, 2021 at 09:11 am
Preserving scientific project websites is important
The contents of the websites tend to disappear when the scientific projects are finished.
The preservation of scientific project websites is important because:
- documents the development of projects;
- ensures access to unique technical and scientific content that researchers have posted on the project websites (eg presentations, photographs, data sets);
- reinforces the visibility of the results of projects financed by FCT.
Experimental collection of scientific projects websites in 2016
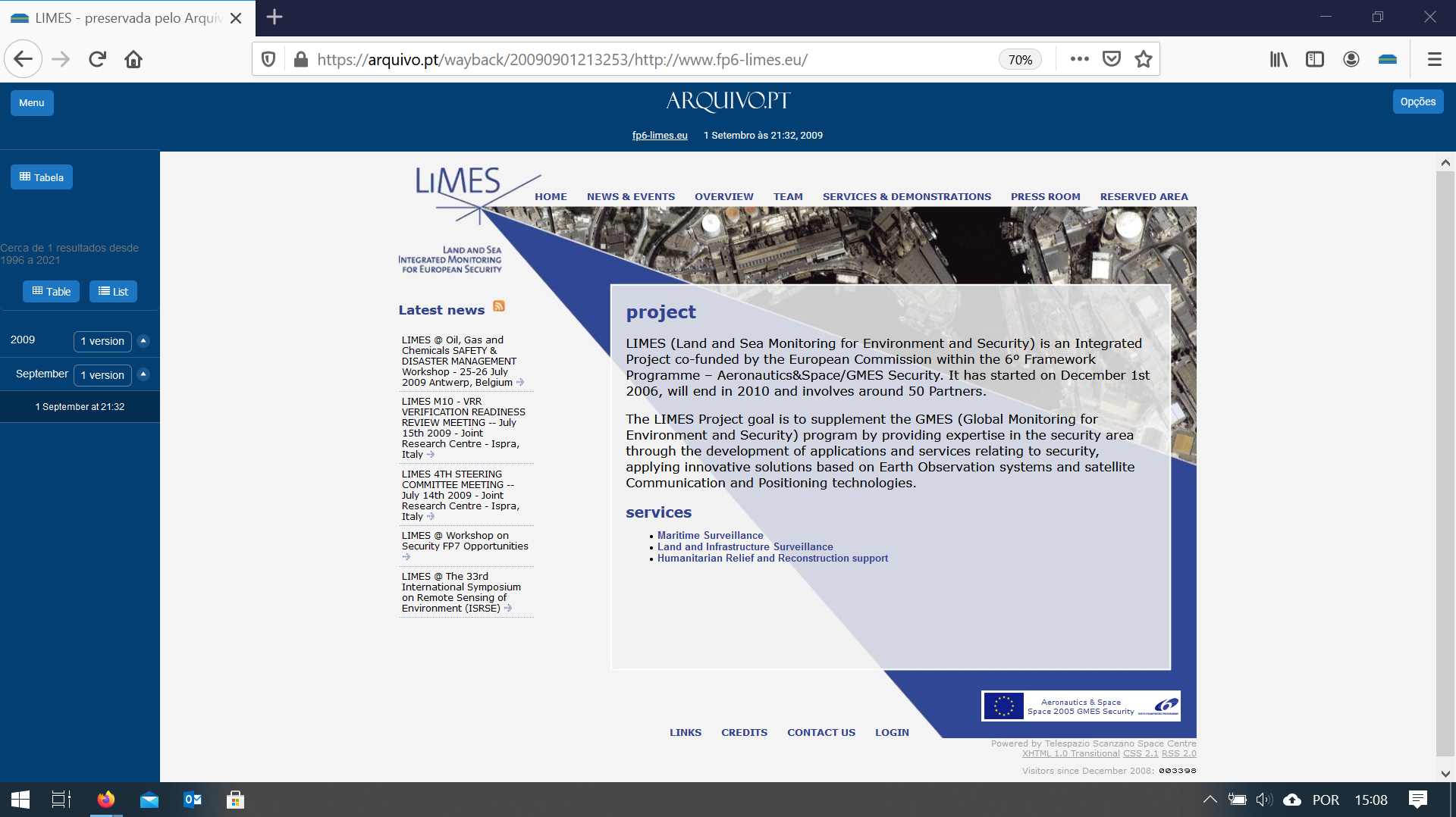
Arquivo.pt automatically collected websites for projects financed by FCT in 2016.
The information about these websites was dispersed as it was not recorded during the administrative process.
For about 20 years, FCT financed scientific projects, so the number of sites could be too high to be identified manually.
Then an automatic methodology for identifying these websites was developed, developed by Arquivo.pt.
The FCT database had a total of 11,996 project entries but did not include references to web addresses. Applying the automatic methodology, 7 956 URLs related to the funded scientific projects were identified.
The collection of content referenced by these addresses resulted in the preservation of 600 721 files (72 GB), including content such as research group web pages, researchers’ personal pages or project-related blogs.
Online references in scientific project reports have been preserved since 2020
From June 2020, the website addresses of the projects financed by FCT must be registered in the progress and final reports funded by FCT.
Arquivo.pt started using these addresses to preserve the contents of websites of national scientific projects in a systematic way.
1st official collection of scientific project websites
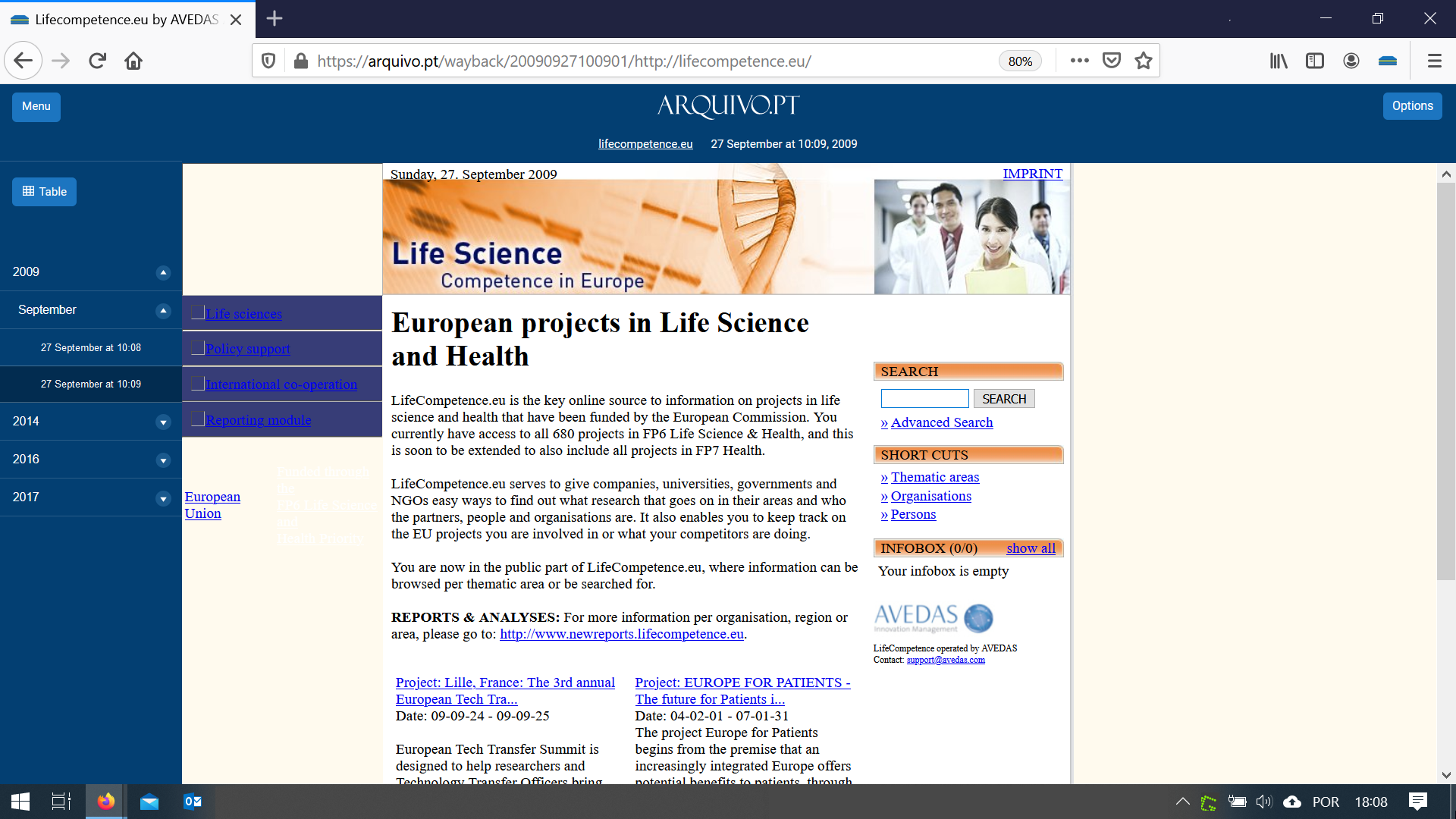
In June 2020, Arquivo.pt obtained 263 addresses related to 100 scientific projects from the reports submitted to FCT. Most of the addresses (67%) did not have any version previously preserved in Arquivo.pt.
The addresses obtained point to online resources such as the websites of the projects, R&D units, news in the media, articles in scientific journals or repositories, databases, videos on Youtube or Facebook pages.
In July 2020, a special collection was launched from this set of addresses which resulted in 6.9 GB of information obtained from the visit to 31,606 URLs.
Exhibition about Research & Development projects
The Scientific Research Memory is an online exhibition dedicated to the websites of scientific projects funded by the Foundation for Science and Technology (FCT) that Arquivo.pt has preserved.
There are also websites of the Research & Development Units financed by FCT.
Memorial do Arquivo.pt preserves scientific websites for free
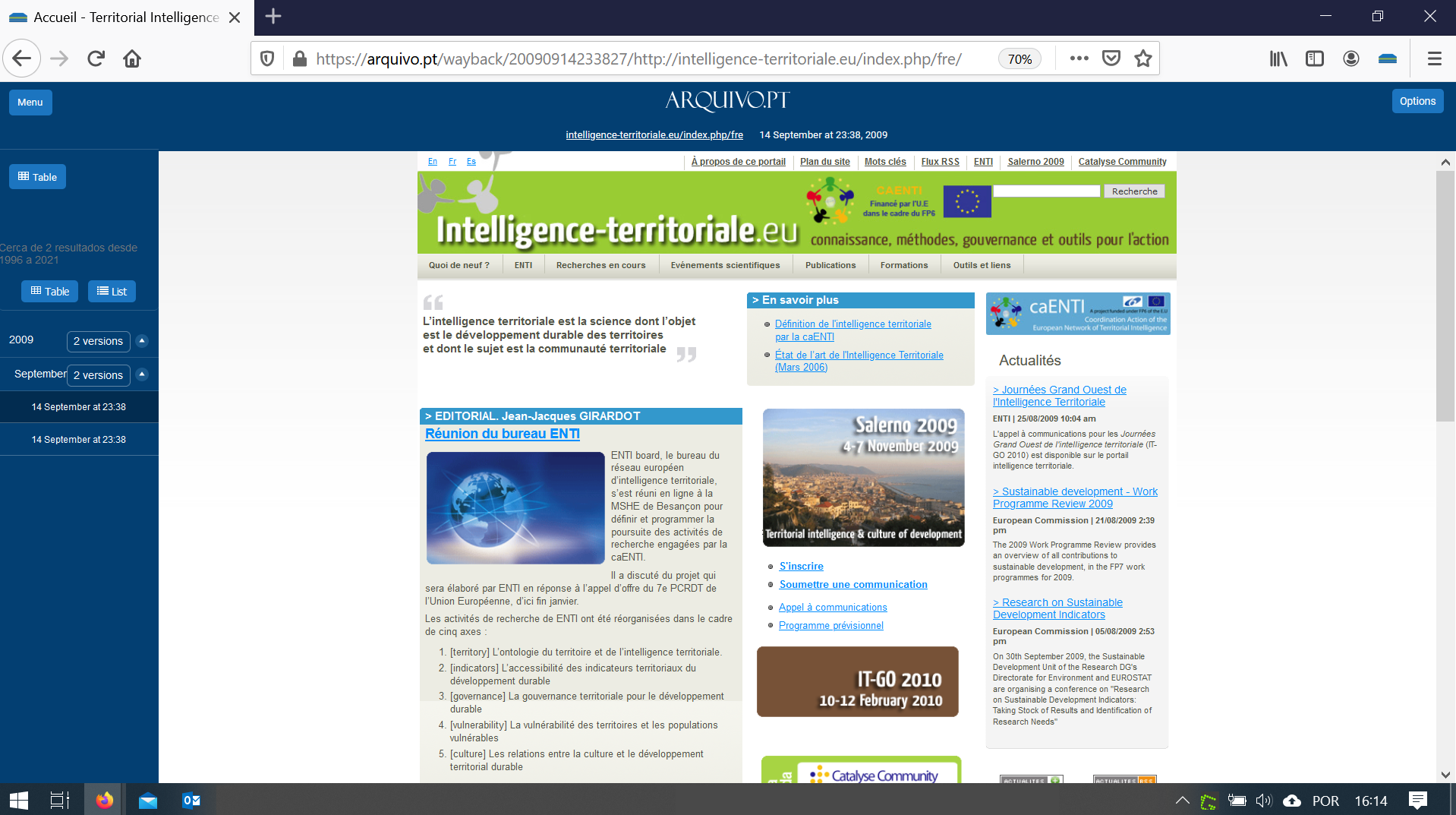
The Memorial do Arquivo.pt service has preserved historic FCT websites that have been disabled. These were created for events or initiatives that have ended and therefore their contents are no longer updated.
To include a website in the Memorial, Arquivo.pt starts by making a high quality collection of its contents.
Then, the collected contents are validated in collaboration with those responsible for the website.
Finally, the website address is redirected to the contents that have been preserved by Arquivo.pt.
For example, if someone wants to access any page on the Scientific Archives Meeting held in 2014, they will be redirected to Arquivo.pt.
Thus, the contents remain accessible over time and the links, the references in scientific communications that may exist do not break.
The digital preservation service Memorial do Arquivo.pt is free of charge for websites of the academic and scientific community, just send a request to contacto@arquivo.pt.
To know more