Local elections will be held in Portugal on 12 October 2025 (Eleições Autárquicas), and Arquivo.pt will launch a special collection of electoral content.
Whenever elections are held, websites and social media channels are created for electoral purposes, many of which are deactivated shortly afterwards.
Sometimes, publications made during the election campaign disappear and it is not possible for citizens to see them again or for researchers to use them for study and analysis.
Arquivo.pt invites you to archive pages about the local elections. It’s simple: copy and paste an address and archive it. Here:
The aim of this joint FCT team was precisely to bring about the meeting and sharing of experiences between various institutions that inevitably have to manage information, both in traditional formats such as paper and in digital formats.
The meeting had 243 participants and 29 speakers throughout the day. Nine of the twenty-seven presentations were submitted for a session called ‘Community Space’.
Digital information was the main theme of the speeches. At the opening, the Head of the DGLAB – Direção Geral do Livro, dos Arquivos e das Bibliotecas (Directorate for Books, Archives and Libraries), Silvestre Lacerda, recalled that the DGLAB was a pioneer among public organisations in tackling the issue of digital preservation. FCT vice-president Francisco Santos emphasised the economic value of data for scientific research.
Digital preservation is not just about technology, as Henrique São Mamede, Professor at Universidade Aberta, INESC TEC, said at the opening conference. It’s also about people, the human factor, the environment outside organisations and new sensibilities such as sustainability and ecology. Hence the importance of creating bridges, of using Artificial Intelligence, for example, in conjunction with ethics. Presentation.
Throughout the day, four panels brought together presentations on various preservation contexts such as the digitisation of sound, image and video, research data, regulatory frameworks, management systems for digitised or born-digital information, dissemination and access, and use in academic research.
Panel 1: Digital preservation initiatives and realities
The first panel was moderated by João Gomes, Director of Advanced Services at FCT, and brought to the table the diversity of contexts in which the issue of preservation and access arises. Here we highlight one aspect of each presentation and invite you to follow the links to learn more about these initiatives.
Moisés Rockemback, Professor at the University of Coimbra and co-author of the book Arquivamento da web e preservação digital (Web archiving and digital preservation), spoke about the first initiatives carried out in Brazil to preserve content published on the Web. The websites of the candidates in the Brazilian elections, for example, are ephemeral by nature but have become material for historiographical research by being preserved in a web archive. From a more theoretical perspective, he addressed the issue of memory. Preserving the web allows us to bring to light events that were only broadcast on digital media such as the web and, in this sense, postpones the end of history expressed in the metaphor of the ‘Dark Age’, a time of darkness, empty of information. Presentation.
Pedro Penteado, Director of Archival and Standardisation Services, presented a set of instruments that the DGLAB has developed, such as the Macro Estrutura Funcional (MEF) (Macro Functional Structure, the Avaliação Suprainstitucional da Informação Arquivística (ASIA) (Super-institutional Assessment of Archival Information) project and the Lista Consolidada na Plataforma CLAV (Consolidated List on the CLAV Platform), which allows the different public administration bodies to comply with legislation and standardise classification and assessment practices. He recalled that these tools are flexible to meet the specific needs of organisations. Presentation.
Pedro Príncipe, Head of the Documentation Services Division at the University of Minho, spoke about research data. The preservation of and access to data is fundamental to the production of science. To achieve this, it is necessary to combine initiatives and work in networks and create communities of practice. The GDI Forum is an example of how useful it is to meet professionals. Certification is highly recommended, as demonstrated by the University of Minho, which has certified its repository, as it is an extra reason to create robustness and to achieve the FAIR (Findable, Accessible, Interoperable, and Reusable) objectives. Presentation.
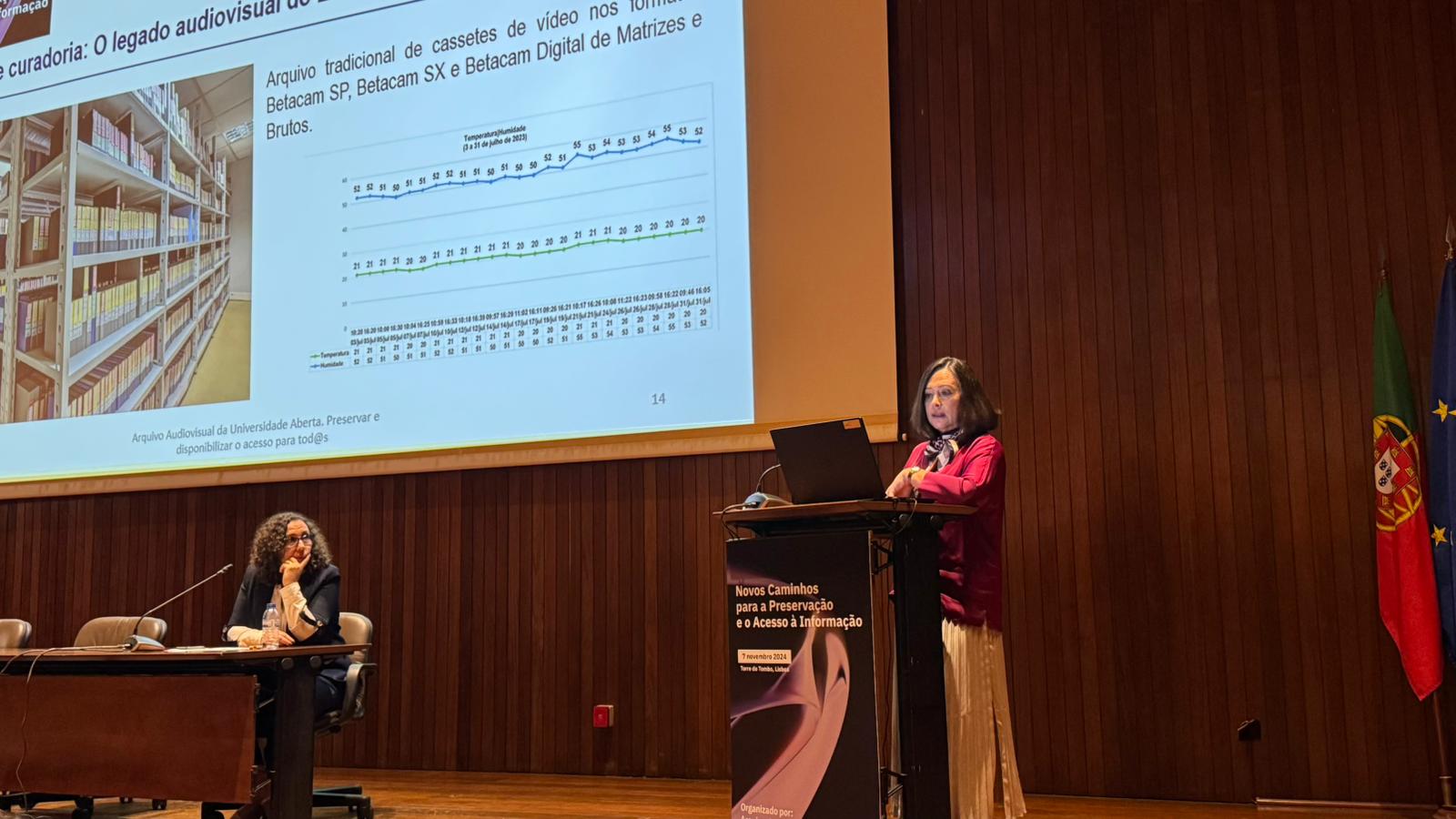
Hilário Lopes, RTP’s Deputy Director of Institutional Relations and Archive, described the path to digitalisation that has completely changed the way we access the RTP archive (Portuguese Radio and Televison). If until 2001 digitisation was done on request, from that year onwards the contents were massively digitised. Since 2007, the contents have been accessible in digital format, which has facilitated access and use. RTP Memória and Portal RTP are two examples of access to the audiovisual heritage of public radio and television. Presentation.
Panel 2: Preserving and reusing Web information
The theme of web archiving was highlighted in the second panel, moderated by Daniel Gomes, manager of Arquivo.pt and its initiator on 8 November 2007.
Ricardo Basílio, digital curator at Arquivo.pt, presented the online exhibition ‘Memories of 25 April on the Internet’, created in collaboration with the 50 Years of 25 April Commemorative Commission, based on preserved web pages. Select pages about the 25 April celebrations across the country were highlighted through a guided tour of the exhibition. Presentation.
António Campos and Hélder Mestre, from the Arquivo Municipal de Sines (Sines City Council Archive), showed how, since 2020, they have been preserving web content of local interest in collaboration with Arquivo.pt. They record web pages with ArchiveWeb.page, a Webrecorder tool, send a copy of the files to Arquivo.pt, transcribe images and videos verbatim, and also use PDF as the most traditional format for archiving news. The issue of accessibility to content for people with special needs is fundamental in the preservation process. Presentation.
Finally, Daniel Gomes emphasised how much has been done in the last 17 years in the field of web preservation, to the point where we now have a functional service that everyone can use. As a testimony to those early days, we found a page from Diário Digital newspaper from November 2006.
Panel 3: Preserving the present and safeguarding the future
The third panel was moderated by Paula Meireles, Coordinator of the Archive, Documentation and Information service at the Foundation for Science and Technology (FCT) and brought four other realities to the table.
Filipe Guimarães Silva, Executive Director of the Fundação Mário Soares e Maria Barroso, and António Coelho, Digital Reproduction Coordinator, delved into the technical issues related to digitisation, based on the case of the collection, which is also accessible on the Casa Comum portal. Quality control is the most important factor in obtaining a preservable digital version. You don’t always need expensive technology to get good results. It is essential to follow standards and ensure that quality metadata is generated. Presentation.
Fernanda Gonçalves, Director of Archives at the São João Local Health Unit, showed how the São João Digital Clinical Repository is transforming access to clinical files with advantages in terms of both speed and quality of information. The information management model at this huge institution poses immense challenges for preservation and continued access, as it involves creating interoperability between multiple systems. What’s more, this is sensitive data with different levels of access. This is where the archive comes in as an asset. The archive service must rise to the challenges of any organisation in order to serve all its ‘clients’. Presentation.
Augusto Ribeiro, head of the Documentation and Information Management Service at UPdigital, University of Porto, explained how the university collection is being preserved. From the treatment of paper documents to their digitisation and inclusion in the digital repository, it’s important to guarantee their robustness. This work has been progressive and systematic, i.e. it follows a plan where all the pieces fit together as the work is carried out. Presentation.
Pedro Penteado (DGLAB) presented the ‘Digital Preservation Guide’ project that is being developed in collaboration with the Asociación Latinoamericana de Archivos (ALA). This initiative will structure content on digital preservation in a pragmatic way. Soon, professionals will have a knowledge base to consult whenever they carry out digital preservation activities. Presentation.
Panel 4: Community space
The fourth panel, moderated by Paula Carvalho, from FCT’s Science and Technology Archive, included 9 short presentations submitted by the community. Below, we present the abstracts submitted by the authors:
Justiça do Futuro: + Digital – Alexandra Lourenço, Albertina Catrola, Alexandra Henriques, António Dias, Cristina Ferreira, Inês Nunes, Rute Ramos | SGMJ
It was shown the work that the Commission has been doing to identify archives, documentation centres and collections of all kinds with material about 25 April. There are public collections that are practically unknown, and others that are in private collections. Inventorying and publicising them is therefore the first step in promoting study and knowledge about 25 de Abrril.
Finally, Maria Inácia Rezola announced the award of the Honourable Mention ‘25 de Abril and Democracy’, together with a prize of 5,000 euros, in the Arquivo.pt Award 2025, to the best work on 25 April that uses Arquivo.pt.
Image gallery
Encontro Dia Mundial da Preservação Digital 2024 #WDPD2024
Credits: photos by Leonor Arrimar (FCT). Included are some images of mobile devices sent in by participants.