By: Marie Haškovcová and Luboš Svoboda, Webarchiv, National Library of the Czech Republic, May 13th to 17th, 2024.
A visit within the EU Erasmus+ programme
Thanks to the EU Erasmus+ programme, focused on adult education – staff mobility, we were able to spend a week job shadowing at the Portuguese web archive Arquivo.pt and compare the strategies of the Czech web archive – Webarchiv with the approaches of our Portuguese colleagues.
In both cases, these are archives focused on national (Czech and Portuguese) content on the Internet.
The Arquivo.pt
While the Czech web archive is part of the National Library of the Czech Republic, the Portuguese archive (Arquivo.pt) is part of the FCCN, under the FCT – Foundation for Science and Technology, which aims to contribute to the development of science, technology and knowledge.
FCT provides IT services to the Portuguese higher education and research system, as well as high-speed internet connectivity. The institutional background of both archives is also reflected in the specifics of their concepts.
The visit included a presentation of the team and the campus and departmental spaces, a presentation of the activities of both archives and a discussion of the different aspects of our work – technical and curatorial tools, technologies and processes, the legislative environment and ethical issues, data storage, some services, research activities, perspectives and future plans.
The Czech web archive
The Czech web archive was founded in 2000, the oldest archival copies date back to 2001 and currently has more than 580 TB of data. Like Arquivo.pt, it harvests content on a national domain based on a list of url addresses obtained from its provider. It supplements these so-called comperhensive harvests with thematic and selective harvests in its acquisition strategy.
Topic collections relate to a specific topic or event, can be one-off or continuously built, and combine manually selected and automated scraped resources. Selective ones are intended for long-term harvesting, have detailed cataloging records that are part of the Czech national bibliography and are licensed – archival copies are therefore freely available through the catalogue.
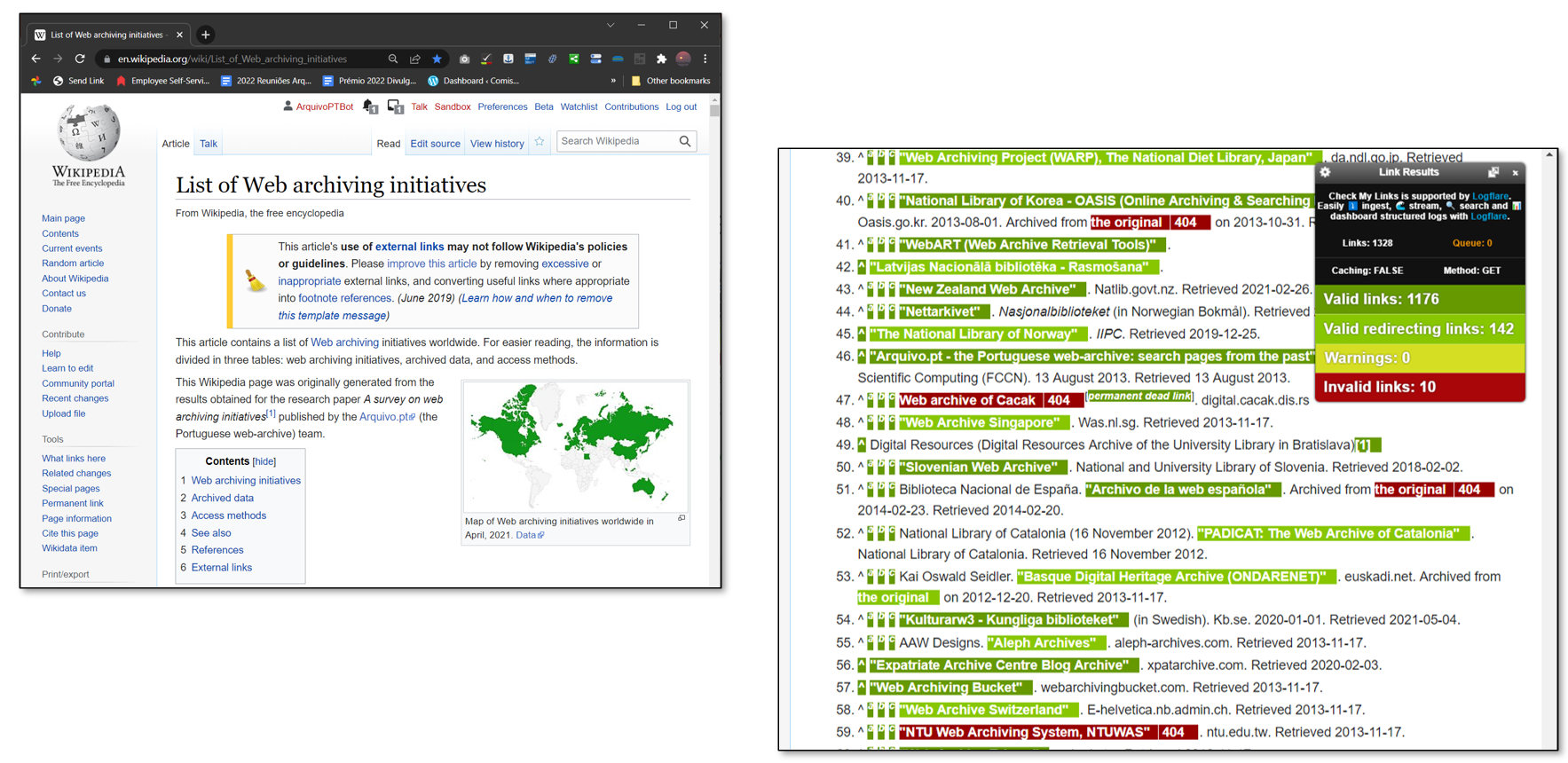
From the Webarchive’s research activities, we presented our project aimed at detecting so-called dead webs through the Extinct Websites application and creating a database to serve as a basis for monitoring broader changes in the Czech web, and the WACloud project aimed at extracting big data from the web archive.
Exchanging knowledge and experience
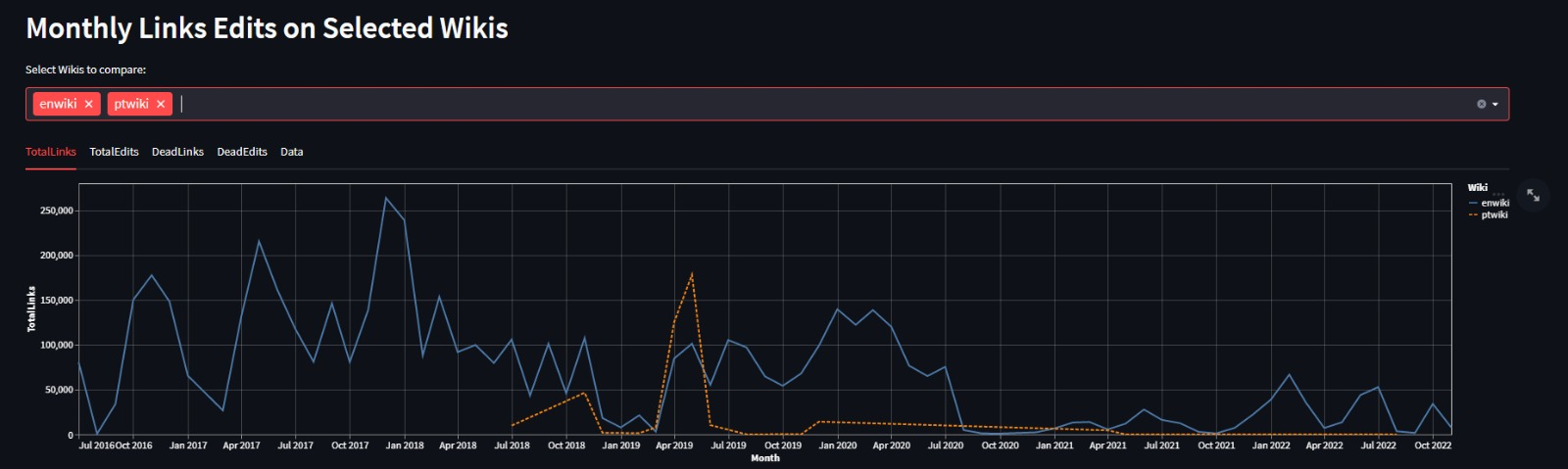
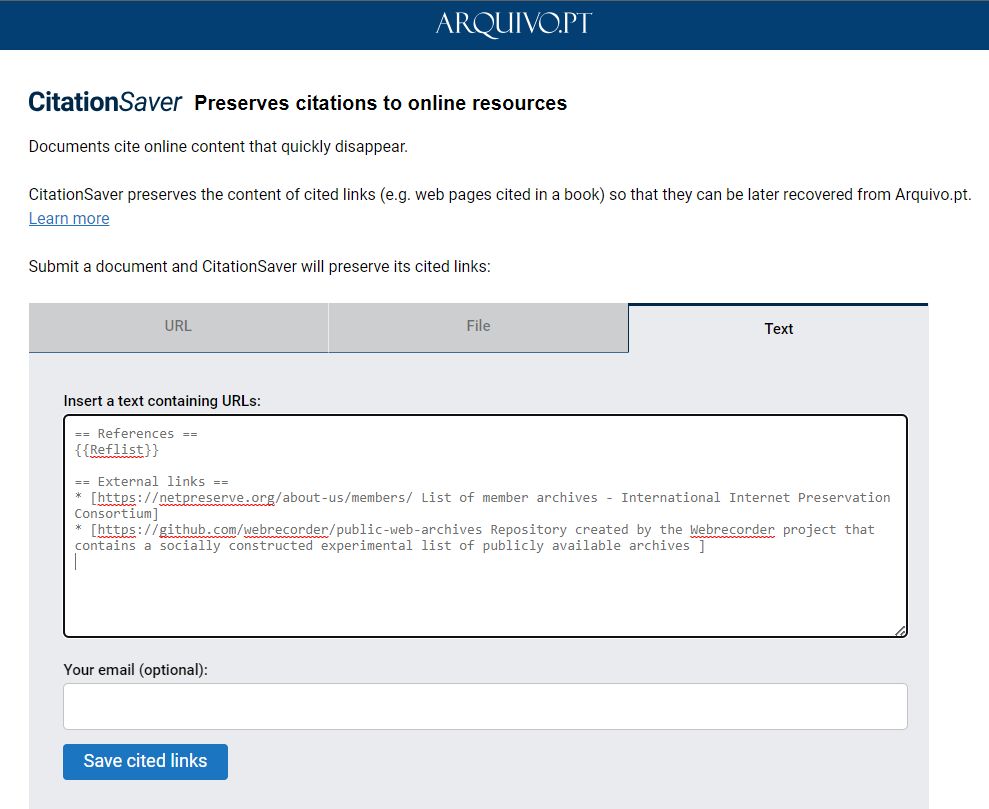
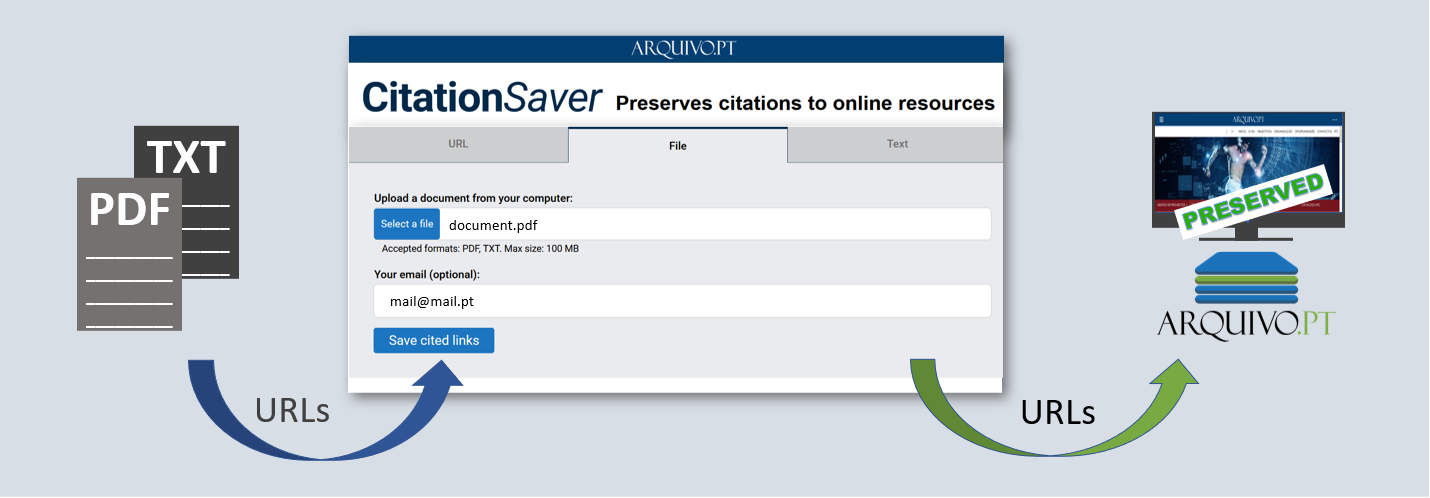
Among the Portuguese projects we were interested in, for example, CitationSaver, and we also discussed the Memorial project, the harvesting of the Portuguese Wikipedia, and the activities of the Portuguese archive related to education in web archiving (training courses).
The meeting was enriched by the discussion of specific topic collections.
- The Czech net art collection documents digital art and its transformation in the online space, providing a unique art historical perspective.
- Another important collection is the Social networks of Members of Parliament of the Czech Republic 2021-2025 collection, which preserves the online communications and interactions of Czech MPs, invaluable for the study of political marketing and public political life.
- The GitHub collection archives important repositories from this popular developer platform, preserving key domestic software projects and their code for future generations.
- Finally, the Crypto, NFT, Blockchain, Web3, Metaverse collection charts the rise and impact of technology in the digital asset space. These collections are key resources for research and analysis of digital culture, policy, and technology, and the discussion of these collections at web archivist meetings contributes to the further development of archival methods and technological innovation.
We focused on exchanging knowledge and experience in seeds acquisition, workflow optimization and sharing technical tips and tricks.
Sharing best practices
We discussed best practices for identifying and collecting key web resources, a critical step in ensuring a comprehensive and representative archive. We shared various strategies for automating and streamlining workflows, including the use of web scraping tools and advanced content filtering.
Technical discussions included solutions to common problems such as harvesting dynamic web pages and overcoming access restrictions. The meeting provided a valuable platform for sharing innovative methods and fostering collaboration among experts, furthering the development of effective and sustainable digital archiving.