Last updated on May 22nd, 2025 at 06:45 pm
Arquivo.pt took part in the workshop entitled “Digital preservation: tools and practices”, promoted by the Faculty of Letters of the University of Coimbra, on the afternoon of May 7, 2025. Moderated by Inês Santos, we highlight the initial panel with excellent speeches by Moisés Rockembach (University of Coimbra), Humberto Innarelli (Unicamp, Brazil) and Daniel Gomes (Arquivo.pt, digital service of FCCN-FCT).
The aim of the meeting was to offer the community a critical reflection on new trends in digital preservation tools and practices.
Digital preservation is a cross-cutting issue for organizations, as they all produce and generate information in digital format. There is a growing range of tools and solutions that promise greater efficiency in information processing. Many are labeled Artificial Intelligence. Such an abundance of products and frameworks calls for greater discussion and a critical approach. And this was achieved brilliantly by the panel of speakers.
Three approaches to Artificial Intelligence and Digital Preservation
This meeting brought together three authors of works on digital preservation at the Amphitheatre III of the Faculty of Letters of the University of Coimbra and discussed different approaches.
Moisés Rockembach, co-author with Caterina Pavão of Arquivamento da Web e preservação digital (Archiving the Web and Digital Preservation), the first work in Portuguese on web archives, focused his presentation on the impact of Artificial Intelligence on digital preservation systems, namely on searching for and accessing information, in classification and indexing processes, for example. With regard to the impact of the new tools that digital technology offers us, he referred to a phrase by Demi Gretscko: “The process of searching for and capturing information described in the text could certainly be improved in the future, especially when considering the contribution of new tools, such as those of Artificial Intelligence”.
There are Artificial Intelligence tools that allow interesting access to information through novelty and format. Archiving must take this reality into account and test the extent to which it can transform the way in which many types of content are disseminated and accessed. One example to illustrate this idea was the presentation of a Podcast generated by Artificial Intelligence from An example to illustrate this idea was the presentation of a Podcast generated by Artificial Intelligence, based on chapter 2 of the book on Web Archives, which deals with digital preservation policies.
Humberto Innarelli, author of Criptex da preservação digital (Digital preservation cryptex), coordinator of the Arquivo Edgard Leuenroth (AEL) and specialist archival researcher at Unicamp, São Paulo and PhD professor at the Paula Souza Centre, São Paulo, posed the question of the future of digital preservation. Until now, the practice for preserving dynamic digital content has been to convert it into static documents. On the other hand, information is increasingly given to us dynamically, from databases or algorithms and Artificial Intelligence. What’s the next step? Archival practice needs to look not only at metadata, as it has done in recent years, but also at what explains how the information was generated (what we might call paradata). This is the only way to put archives and digital preservation in the long-term perspective. A hundred or two hundred years from now we should still be able to access the digital information produced today.
Daniel Gomes, editor of the book The Past Web and founder of Arquivo.pt, discussed the issue of Artificial Intelligence as it relates to non-artificial, human-produced content. What added value do tools that generate text, images, audio or video bring? If we consider, for example, that a Podcast on digital preservation used a book written by a human author as its basis, what new knowledge did it generate? Little or none. So, what has come to be called Artificial Intelligence can be considered a way of presenting human knowledge and in no way exempts humanity from continuing to think, research and produce new knowledge.
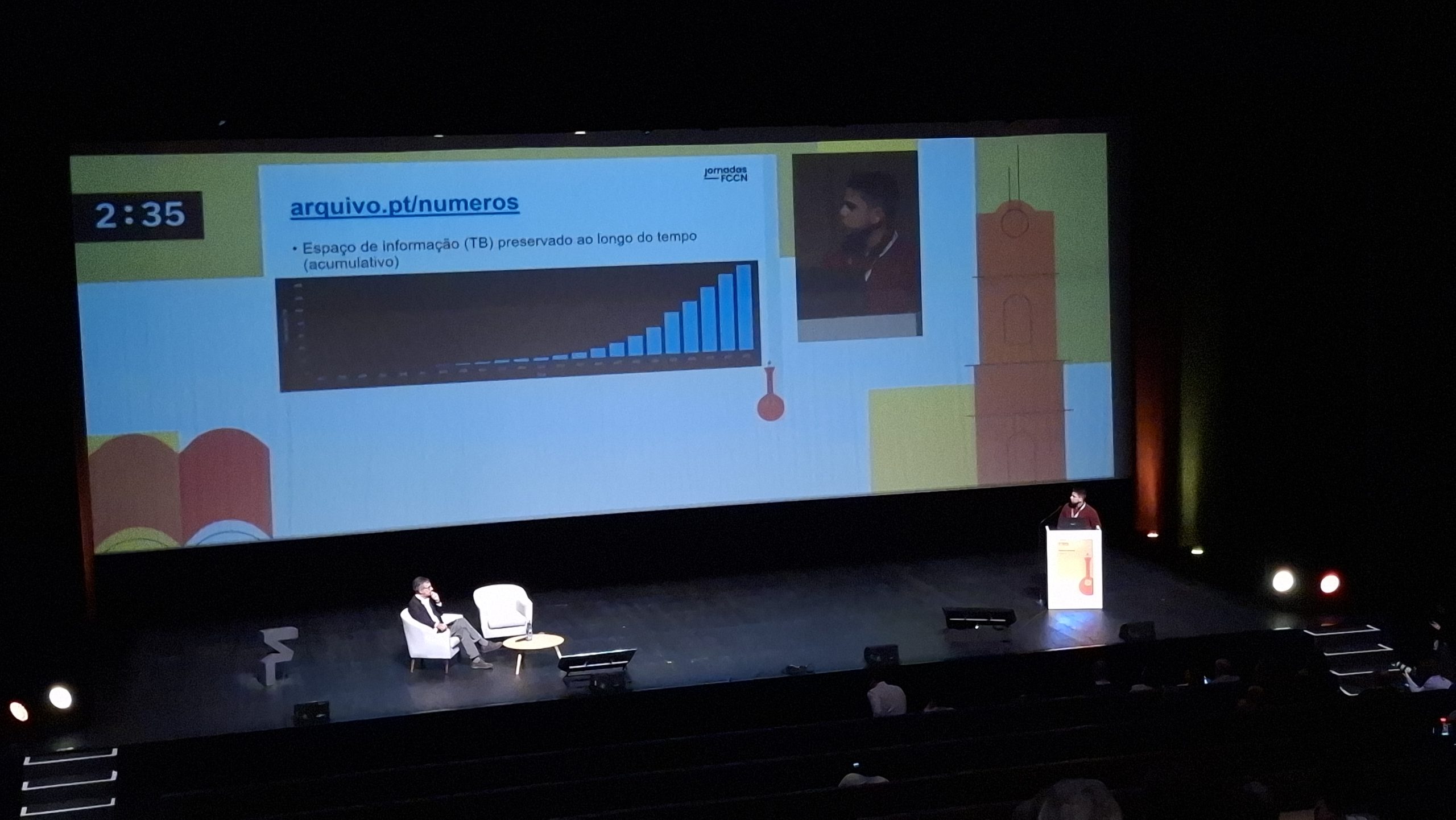
Arquivo.pt preserves content that has been published by individuals and organizations and in this sense is a unique source of its kind. Information published on the web is important for reporting and better understanding recent history, since the 1990s. Any Artificial Intelligence tool will have to go back to the point where the information was created by people. The human origin of the content preserved by Arquivo.pt, and the same can be said of traditional archives, makes them of enormous value, even considering their economic value. How much is the information stored in a web archive worth?

New MOOC (Massive Online Open Course) about web archiving
Daniel Gomes, Manager of Arquivo.pt, has announced first-hand the online course on the NAU platform: The Web of the Past: Preservation and Research (in Portuguese).
The online course or MOOC (Massive Online Open Course) is available for those who want to deepen their knowledge of web preservation.
The short link for dissemination is arquivo.pt/mooc
Preserved Arquivo.pt data and its automatic processing by APIs
Vasco Rato, developer of Arquivo.pt, showed how the automatic processing interfaces, Application Programming Interfaces (APIs), work.
Arquivo.pt data can be processed by Artificial Intelligence. The works competing for the Arquivo.pt Award have already demonstrated this, as have projects such as GlórIA, a Large Language Model developed at NOVA-FCT.
Finally, Ricardo Basílio, digital curator, showed how anyone can save a page or an entire website on their own computer in a standardized format, compatible with web archives. ArchiveWeb.page and browsertrix-crawler were used for this, as training tools. This practice allows the community to be increasingly active in preserving institutional information published on the Web.
Agenda
14h30 Panel – Moderator: Inês Santos, University of Coimbra
- Digital Preservation and Artificial Intelligence – Moisés Rockembach, University of Coimbra – Slides
- Cryptex for Digital Preservation: The Next Step – Humberto Innarelli, Unicamp – Slides
- Arquivo.pt and Web Preservation – Daniel Gomes, FCCN-FCT – Slides
16h00 Break
- Open Data for Research. Automatic information processing through APIs – Vasco Rato, FCCN-FCT – Slides
- Demo – Archiving the Web: do-it-yourself – Ricardo Basílio, FCCN-FCT – Slides
17h00 – Final
Image gallery
Images on the Coimbra University social media
Video of some moments from the event (published on Facebook)
Workshop na Faculdade de Letras da Universidade de Coimbra
























































{kind=link}