A comunidade académica e de investigação tem solicitado a possibilidade de descarregar automaticamente seleções de conteúdos arquivados e ficheiros de índice (CDXJ), por exemplo, para alimentar modelos de aprendizagem automática de Inteligência Artificial ou recuperar informação de sítios web selecionados (ex. notícias ou websites que foram atacados).
O Arquivo.pt passou a disponibilizar publicamente os seus ficheiros de índice CDXJ em tempo real, para facilitar o acesso automático a grandes volumes de conteúdos arquivados da web. Saiba como em:
Última atualização em 1 de Outubro de 2021 às 9:12
O Arquivo.pt identificou automaticamente sites de projetos de I&D para preservar o seu conteúdo. Já preservou mais de 52 milhões de ficheiros (7 TB) relacionados com ciência para acesso futuro.
Os sites de I&D são valiosos e estão a ser perdidos
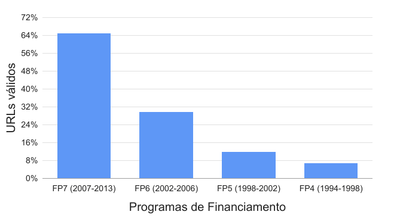
Distribuição de URLs de projetos que referenciavam conteúdo relevante por Programa-Quadro desde o FP4 (1994), oriundos do EU Open Data Portal e validados em novembro de 2015.
Distribuição de URLs de projetos que referenciavam conteúdo relevante por Programa-Quadro desde o FP4 (1994), oriundos do EU Open Data Portal e validados em novembro de 2015.
Arquivo.pt identificou sites de I&D automaticamente
O foco do Arquivo.pt é a preservação de informação publicada na Web para fins científicos e académicos. Assim sendo, desenvolveu um projeto para a identificação automática de endereços relacionados com projetos de I&D para que o seu conteúdo seja preservado de forma sistemática.
Todos os dados e ferramentas desenvolvidas durante esta investigação foram disponibilizados em acesso aberto de modo a que possam ser reutilizados e colaborativamente melhorados.
Já foram preservados 52 milhões de ficheiros da web relacionados com Ciência
A aplicação da metodologia desenvolvida pelo Arquivo.pt já permitiu preservar mais de 52 milhões de ficheiros (7 TB) oriundos de 53 993 sites de projetos de I&D financiados desde o FP4 (1994), tais como o projeto europeu WEZARD financiado com o objetivo de “preparar a futura comunidade de investigação na área da robustez dos sistemas de transporte aéreos quando for deparada com incidentes climáticos”. O site para este projeto (www.wezard.eu) já não se encontra disponível online.Contudo, foi preservado e pode ser acedido no Arquivo.pt.
Todos os sites identificados e preservados no âmbito deste projeto podem ser acedidos através do Arquivo.pt desde março de 2017.
Site do projeto europeu WEZARD (www.wezard.eu), financiado pelo 7º Programa-Quadro da União Europeia entre 2011 e 2013, disponível no Arquivo.pt.
Contributos para complementar os dados do European Open Data Portal
O processo desenvolvido foi aplicado aos conjuntos de dados publicados através do EU Open Data Portal para tentar complementar as informações em falta acerca dos URLs dos projetos. Os resultados obtidos mostraram que a integridade do conjunto de dados do FP7 foi melhorada em 86,6%.
Todos os conjuntos de dados resultantes foram disponibilizados ao público para que possam ser melhorados e reutilizados por outras organizações interessadas na preservação deste património digital (FP4, FP5, FP6, FP7).
Bases de dados do European Open Data Portal completadas pelo Arquivo.pt através da metodologia desenvolvida. Os novos URLs de projeto estão disponíveis na coluna “Identified Websites” dos ficheiros: FP4, FP5, FP6, FP7.