Last updated on April 20th, 2023 at 09:37 pm
Documents cite web content by referencing their URLs so that readers can later access them.
In the case of scientific articles, the importance of these citations is even greater to maintain the integrity of research works because they often reference essential information to enable the reproducibility of an experiment or analysis.
For example, links in a scientific article may cite the datasets, software or web news that supported the research, which are not included in the text of the article.
To respond to the need of preserving the integrity of documents, Arquivo.pt launched the CitationSaver.
CitationSaver automatically extracts cited links in a document and preserves their content (e.g. web pages cited in a book) so that they can be retrieved later from Arquivo.pt.
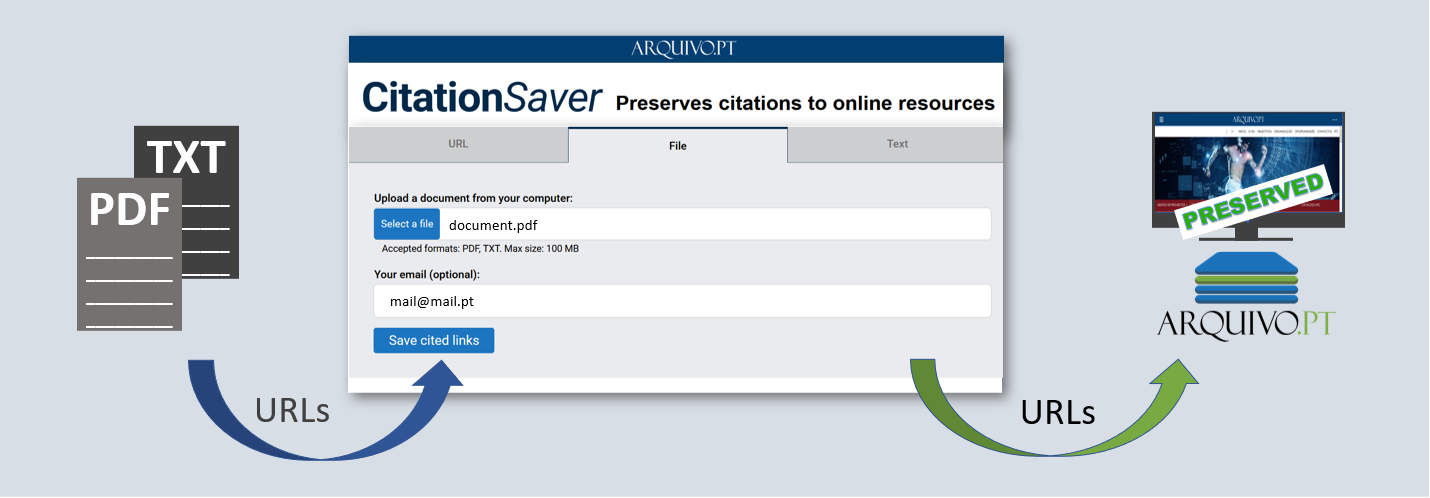
Use CitationSaver to preserve the integrity of your documents
Upload a document and CitationSaver will extract the cited URLs, archive their content and make it available on Arquivo.pt after a short notice. There are 3 methods to upload a document:
- insert the address (URL) of the PDF or TXT file, if it is published online
- upload the file in PDF or TXT format
- paste the text containing the addresses you want to preserve (e.g. References section of an article or Bibliography of a book).